MLlib--PIC算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/82c3ef86303321055eb10f7e100eb84b.html
PIC算法 幂迭代聚类
1.谱聚类
2.谱聚类分割方法


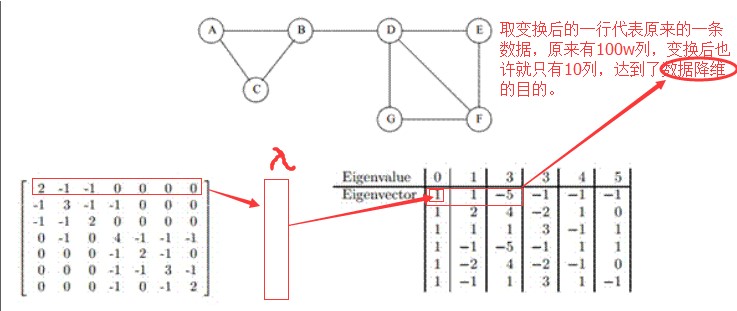
3.PIC算法VS谱聚类
4谱聚类code
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.clustering.PowerIterationClustering
/**
* Created by hzf
*/
object PowerIterationClustering_new {
// E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 3 20 local
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
if (args.length < 5) {
System.err.println("Usage: PIC <inputPath> <modelPath> <K> <iterations> <master> [<AppName>]")
System.exit(1)
}
val appName = if (args.length > 5) args(5) else "PIC"
val conf = new SparkConf().setAppName(appName).setMaster(args(4))
val sc = new SparkContext(conf)
val data: RDD[(Long, Long, Double)] = sc.textFile(args(0)).map(line => {
val parts = line.split(" ").map(_.toDouble)
(parts(0).toLong, parts(1).toLong, parts(2))
})
val pic = new PowerIterationClustering()
.setK(args(2).toInt)
.setMaxIterations(args(3).toInt)
val model = pic.run(data)
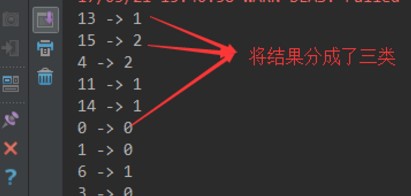
model.assignments.foreach { a =>
println(s"${a.id} -> ${a.cluster}")
}
model.save(sc, args(1))
}
}
E:\IDEA_Projects\mlib\data\pic\train\pic_data.txt E:\IDEA_Projects\mlib\data\pic\model 320 local
MLlib--PIC算法的更多相关文章
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- spark mllib k-means算法实现
package iie.udps.example.spark.mllib; import java.util.regex.Pattern; import org.apache.spark.SparkC ...
- Spark MLlib回归算法LinearRegression
算法说明 线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析方法,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归,在实际情况中大多数都是多 ...
- Spark MLlib基本算法【相关性分析、卡方检验、总结器】
一.相关性分析 1.简介 计算两个系列数据之间的相关性是统计中的常见操作.在spark.ml中提供了很多算法用来计算两两的相关性.目前支持的相关性算法是Pearson和Spearman.Correla ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- Spark2.0机器学习系列之11: 聚类(幂迭代聚类, power iteration clustering, PIC)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet all ...
- 转载:Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现
Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现 发表于2015-05-07 21:58| 10255次阅读| 来源<程序员>电子刊| 9 条评论| 作者孟祥瑞 大 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
随机推荐
- lesson - 1 aming
一. Linux是什么* 关于Linux历史(http://www.aminglinux.com/bbs/thread-6568-1-1.html 需要大家查查资了解,也可以看看5期的视频)* 发 ...
- c#程序连接mysql,报"Illegal mix of collations (utf8_general_ci,IMPLICIT) and (utf8_unicode_ci,IMPLICIT) for operation '='"的解决方案
=============================================== 20170607_第一次修改 ccb_warlock === ...
- COMPUTE子句和Group By
首先声明一下,这个COMPUTE语法在SQLServer 2012之后,就废弃使用了,详情请看https://msdn.microsoft.com/librar ...
- Django ORM详解
ORM:(在django中,根据代码中的类自动生成数据库的表也叫--code first) ORM:Object Relational Mapping(关系对象映射) 我们写的类表示数据库中的表 我们 ...
- S2 深入.NET和C#编程 一: 深入C#.NET框架
深入C#.NET框架 1..NET框架 之一 推荐一个代码管理平台,博客发布平台 git 之前的复习: 学习的网站: git github.com 2.类和对象的关系 Dept de ...
- 01-Java基础及面向对象
JAVA基础知识 Java 是SUN(Stanford University Network,斯坦福大学网络公司)1995年推出的一门面向 Internet 的高级编程语言. Java 虚拟机(JVM ...
- Java中对List<E>按E的属性排序的简单方法
这是LeetCode上的题目56. Merge Intervals中需要用到的, 简单来说,定义了E为 /** * Definition for an interval. * public class ...
- 关于 Python 入门的一些问题?
一.用 python 能够做什么?解决什么问题? A1:理论上来说,计算机能做什么,python 语言就能让它做什么,也即 python能做什么. 数值计算.机器学习.爬虫.云相关开发.自动化测试.运 ...
- (笔记):组合and继承之访问限制(二)
上篇简单介绍了public与private的基本使用.private的访问限制相对复杂.针对这种访问属性,我们会想到有没有一种方式可以无视这种属性.答案是:有.我们可以通过friend的方式(可以破解 ...
- 用grant命令为用户赋权限以后,登录时,出现:ERROR 1045 (28000)
ERROR 1045(28000)信息是因为权限的问题.这个ERROR分为两种情况: 第一种: ERROR 1045 (28000): Access denied for user 'root'@'l ...