神经网络与深度学习笔记 Chapter 2.
转载请注明出处http://www.cnblogs.com/zhangcaiwang/p/6886037.html
以前都没有正儿八经地看过英文类文档,神经网络方面又没啥基础,结果第一章就花费了我将近一周的晚上。不过还是有收获的,希望英文阅读水平越来越高吧。
上一章讲解了神经网络如何通过梯度下降学习权重和偏差,但是没有讲解代价函数(cost function)的梯度是怎么求解的。本章中主要讲解一个用来计算代价函数梯度的快速算法:反向传播(backpropagation)算法。
Warm up: a fast matrix-based approach to computing the output from a neural network
定义 表示第(l-1)层的第k个神经元到第l层的第j个神经元的权重。
表示第(l-1)层的第k个神经元到第l层的第j个神经元的权重。 表示第l层的第j个神经元的bias。
表示第l层的第j个神经元的bias。 表示地l层的第j个神经元的激活值。
表示地l层的第j个神经元的激活值。
接下来我们要把下面的等式向量化:
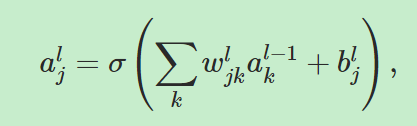 =====》
=====》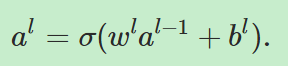
其中al表示第l层网络的神经元的激活值构成的向量,wl、bl同理。其中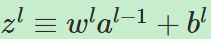 被称为加权输入(weighted input).
被称为加权输入(weighted input).
The two assumptions we need about the cost function
第一个假设是,损失函数可以写为单个训练样例(x1,x2,x3,x4,...,xn)的损失函数的平均值,也就是: ,这个假设在本系列文章中的其他损失函数中同样成立。我们做这个假设的原因是因为反向传播实际上让我们计算的是
,这个假设在本系列文章中的其他损失函数中同样成立。我们做这个假设的原因是因为反向传播实际上让我们计算的是 ,然后我们通过对每一个训练样例做平均来得到
,然后我们通过对每一个训练样例做平均来得到 。
。
第二个假设是,损失函数可以写成神经网络的输出的函数,如下所示:
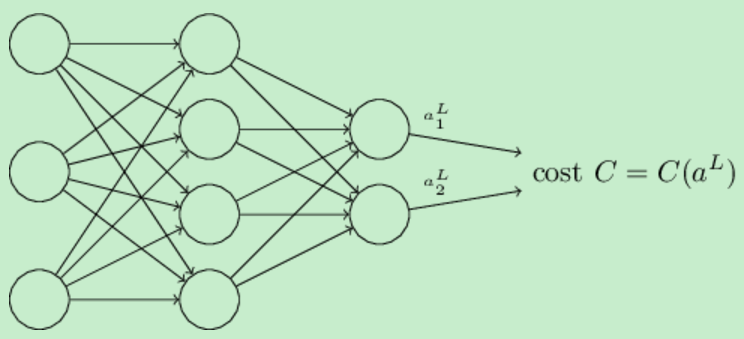
比如说二次损失函数(quadratic cost function)就满足这个要求,因为对于一个训练样例x的损失函数可以被写成 ,而它正是输出激活值的函数。
,而它正是输出激活值的函数。
The Hadamard product, s⊙t
Hadamard乘积是用来定义向量之间的乘积。向量s和向量t的乘积的结果仍为一个向量,且元素为sjtj,也就是有 比如:
比如:
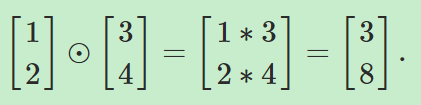
反向传播的四个基本方程
理解反向传播就是理解改变权重和bias是如何影响损失函数的。最终,这意味着计算 ,为了计算它们,我们要先引入一个中间量
,为了计算它们,我们要先引入一个中间量 ,它被称为第l层的第j个神经元的误差。定义:
,它被称为第l层的第j个神经元的误差。定义:
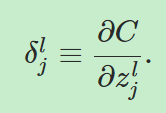
公式一,输出层误差公式:
 ------------------------>输出层单个神经元误差
------------------------>输出层单个神经元误差
 ------------->输出层误差向量形式,
------------->输出层误差向量形式, 是偏导数
是偏导数 的向量。
的向量。
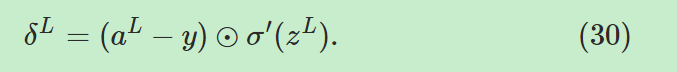 ------------->输出层误差向量形式。如果单个神经元对单个输入样例的损失函数有
------------->输出层误差向量形式。如果单个神经元对单个输入样例的损失函数有 的形式,那么很容易有
的形式,那么很容易有 。
。
公式二,误差传递公式:
 。对于这个公式的前一部分
。对于这个公式的前一部分 ,我们可以直观地认为当误差通过网络反向传播时
,我们可以直观地认为当误差通过网络反向传播时
它给了我们一种测量第l层神经元误差的方式。第二部分 把误差又进行反向传播并通过了激励函数,这样我们就得到了第l层加权输入中的误差。通过公式一和公式二,我们可以计算任意一层的误差,由公式一我们可以得到第L层的误差,用公式二反向传播可以获得l-1层的误差。依次向下进行。。。
把误差又进行反向传播并通过了激励函数,这样我们就得到了第l层加权输入中的误差。通过公式一和公式二,我们可以计算任意一层的误差,由公式一我们可以得到第L层的误差,用公式二反向传播可以获得l-1层的误差。依次向下进行。。。
公式三,损失函数对网络中bias的偏导公式:
 ,这就是说
,这就是说 实际上等于损失函数的改变率
实际上等于损失函数的改变率 。该公式可以重写如公式(31):
。该公式可以重写如公式(31):
 ,它的意思是说某一神经元的δ值由该神经元的bias值表示。
,它的意思是说某一神经元的δ值由该神经元的bias值表示。
公式四,损失的改变率与网络中的权重的等式:
 ,这个公式表明了,如何通过a和δ计算
,这个公式表明了,如何通过a和δ计算 。它可以被简化重写如(32):
。它可以被简化重写如(32):
 ,用图表示就是
,用图表示就是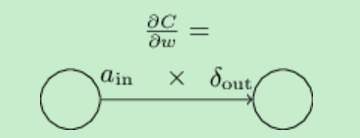 。公式(32)表明,当ain很小的时候,损失函数对权重的偏导数也会很小,我们称之为学习慢(learn slowly),也就是说从低激发值神经元深处的权重学习慢。
。公式(32)表明,当ain很小的时候,损失函数对权重的偏导数也会很小,我们称之为学习慢(learn slowly),也就是说从低激发值神经元深处的权重学习慢。
由以上分析可知,反向传播通过δ来计算代价函数对权重和偏置的偏导数,进而可以通过梯度下降推导出的公式对权重进行更新。反向传播算法的意义就在于不用通过对权重和bias真正求出偏导数,这省去了很大的麻烦。
参考资料:http://neuralnetworksanddeeplearning.com/chap2.html
神经网络与深度学习笔记 Chapter 2.的更多相关文章
- 神经网络与深度学习笔记 Chapter 6之卷积神经网络
深度学习 Introducing convolutional networks:卷积神经网络介绍 卷积神经网络中有三个基本的概念:局部感受野(local receptive fields), 共享权重 ...
- 神经网络与深度学习笔记 Chapter 1.
转载请注明出处:http://www.cnblogs.com/zhangcaiwang/p/6875533.html sigmoid neuron 微小的输入变化导致微小的输出变化,这种特性将会使得学 ...
- 神经网络与深度学习笔记 Chapter 3.
交叉熵 交叉熵是用于解决使用二次代价函数时当单个神经元接近饱和的时候对权重和bias权重学习的影响.这个公式可以看出,当神经元饱和的时候,sigma的偏导接近于0,w的学习也会变小.但是应用交叉熵作为 ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- Deeplearning.ai课程笔记-神经网络和深度学习
神经网络和深度学习这一块内容与机器学习课程里Week4+5内容差不多. 这篇笔记记录了Week4+5中没有的内容. 参考笔记:深度学习笔记 神经网络和深度学习 结构化数据:如数据库里的数据 非结构化数 ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- UFLDL深度学习笔记 (一)反向传播与稀疏自编码
UFLDL深度学习笔记 (一)基本知识与稀疏自编码 前言 近来正在系统研究一下深度学习,作为新入门者,为了更好地理解.交流,准备把学习过程总结记录下来.最开始的规划是先学习理论推导:然后学习一两种开源 ...
随机推荐
- webpack1 新手入门教程
本文github仓库地址: https://github.com/Rynxiao/webpack-tutorial ,里面包括了本教程的所有代码. [如果你觉得这篇文章写得不错,麻烦给本仓库一颗星:- ...
- window10(64bit)+VS2010编译ACE_TAO源码库
1.下载 ACE+TAO下载地址:http://download.dre.vanderbilt.edu/previous_versions/ VS2010下载地址:https://pan.baidu. ...
- KMP算法(研究总结,字符串)
KMP算法(研究总结,字符串) 前段时间学习KMP算法,感觉有些复杂,不过好歹是弄懂啦,简单地记录一下,方便以后自己回忆. 引入 首先我们来看一个例子,现在有两个字符串A和B,问你在A中是否有B,有几 ...
- AddDigitsTotal - 把数字中单个数相加
给定一个int数字,把数字中的单个数相加起来:得到的结果如果不是个位数,继续相加 如给定 19,执行1+9 = 10 --> 1 + 0 = 1 返回1 给定22,返回4 思路很简单,把各个位 ...
- 51nod_1490: 多重游戏(树上博弈)
题目链接 该题实质上是一个树上博弈的问题.要定义四种状态--2先手必胜 1先手必败 3可输可赢 0不能控制 叶子结点为先手必胜态: 若某结点的所有儿子都是先手必败态,则该结点为先手必胜态: 若某结点的 ...
- Linux shell 自定义函数
一.定义shell函数(define function) 语法: [ function ] funname [()] { action; [return int;] } 说明: 1.可以带functi ...
- linux的文件权限与目录配置<----->第二章
1.Linux文件属性 [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] ...
- 初识RabbitMQ系列之一:简单介绍
一:RabbitMQ是什么? 众所周知,MQ是Message Queue(消息队列)的意思,RabbitMQ就是众多MQ框架其中的一款,开源实现了AMQP协议(官网:http://www.amqp. ...
- Stacked Regression的详细步骤和使用注意事项
声明:这篇博文是我基于一篇网络文章翻译的,并结合了自己应用中的一些心得,如果有侵权,请联系本人删除. 最近做推荐的时候,开始接触到Stacking方法,在周志华老师的西瓜书中,Stacking方法是在 ...
- oracle 通过同义词建立视图
需要给予以下权限. GRANT CREATE VIEW TO tms;GRANT SELECT ANY table TO tms;GRANT SELECT ANY DICTIONARY TO tms;