[Spark] 08 - Structured Streaming
基本了解
响应更快,对过去的架构进行了全新的设计和处理。
核心思想:将实时数据流视为一张正在不断添加数据的表,参见Spark SQL's DataFrame。
一、微批处理(默认)
写日志操作 保证一致性。
因为要写入日志操作,每次进行微批处理之前,都要先把当前批处理的数据的偏移量要先写到日志里面去。
如此,就带来了微小的延迟。
数据到达 和 得到处理 并输出结果 之间的延时超过100毫秒。
二、持续批处理
例如:"欺诈检测",在100ms之内判断盗刷行为,并给予制止。
因为 “异步” 写入日志,所以导致:至少处理一次,不能保证“仅被处理一次”。
Spark SQL 只能处理静态处理。
Structured Streaming 可以处理数据流。
三、与spark streaming的区别
过去的方式,如下。Structured Streaming则采用统一的 spark.readStream.format()。
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') # <---- 这是文件夹!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
inputStream = ssc.queueStream(rddQueue)
Structured Streaming 编程
一、基本步骤
二、demo 示范
代码展示
统计每个单词出现的频率。
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode if __name__ == "__main__":
spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
spark.sparkContext.setLogLevel('WARN')
# 创建一个输入数据源,类似"套接子流",只是“类似”。
lines = spark.readStream.format("socket").option("host”, “localhost").option("port", 9999).load()
# Explode得到一个DataFrame,一个单词变为一行;
# 再给DataFrame这列的title设置为 "word";
# 根据word这一列进行分组词频统计,得到“每个单词到底出现了几次。
words = lines.select( explode( split( lines.value, " " ) ).alias("word") )
wordCounts = words.groupBy("word").count() # <--- 得到结果
# 启动流计算并输出结果
query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start()
query.awaitTermination()
程序要依赖于Hadoop HDFS。
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
新建”数据源“终端
$ nc -lk 9999
新建”流计算“终端
$ /usr/local/spark/bin/spark-submit StructuredNetworkWordCount.py
输入源
一、File 输入源
(1) 创建程序生成JSON格式的File源测试数据
例如,对Json格式文件进行内容统计。目录下面有1000 json files,格式如下:

(2) 创建程序对数据进行统计
import os
import shutil
from pprint import pprint from pyspark.sql import SparkSession
from pyspark.sql.functions import window, asc
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType TEST_DATA_DIR_SPARK = 'file:///tmp/testdata/' if __name__ == "__main__": # 定义模式
schema = StructType([
StructField("eventTime" TimestampType(), True),
StructField("action", StringType(), True),
StructField("district", StringType(), True) ]) spark = SparkSession.builder.appName("StructuredEMallPurchaseCount").getOrCreate()
spark.sparkContext.setLogLevel("WARN") lines = spark.readStream.format("json").schema(schema).option("maxFilesPerTrigger", 100).load(TEST_DATA_DIR_SPARK) # 定义窗口
windowDuration = '1 minutes'
windowedCounts = lines.filter("action = 'purchase'") \
.groupBy('district', window('eventTime', windowDuration)) \
.count() \
.sort(asc('window''))
# 启动流计算
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.option('truncate', 'false') \
.trigger(processingTime = "10 seconds") \ # 每隔10秒,执行一次流计算
.start() query.awaitTermination()
(3) 测试运行程序
a. 启动 HDFS
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
b. 运行数据统计程序
/usr/local/spark/bin/spark-submit spark_ss_filesource.py
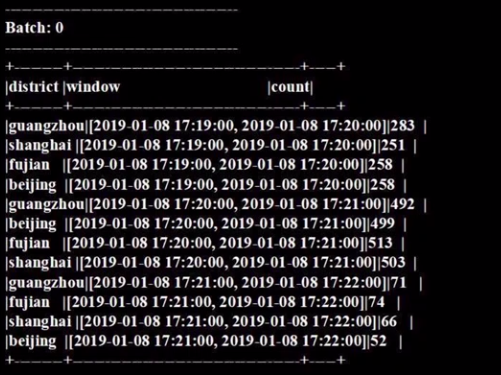
c. 运行结果
二、Socket源和 Rate源
(因为只能r&d,不能生产时间,故,这里暂时略)
一般不用于生产模式,实验测试模式倒是可以。
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("TestRateStreamSource").getOrCreate()
spark.sparkContext.setLogLevel('WARN')
紧接着是下面的程序:

# 每秒钟发送五行,属于rate源;
# query 代表了流计算启动模式;
运行程序
$ /usr/local/spark/bin/spark-submit spark_ss_rate.py
输出操作
一、启动流计算
writeStream()方法将会返回DataStreamWrite接口。
query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start()

输出 outputMode 模式

接收器 format 类型
系统内置的输出接收器包括:File, Kafka, Foreach, Console (debug), Memory (debug), etc。
生成parquet文件
可以考虑读取后转化为DataFrame;或者使用strings查看文件内容。
代码展示:StructuredNetworkWordCountFileSink.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
from pyspark.sql.functions import length

只要长度为5的dataframe,也就是单词长度都是5。

"数据源" 终端
# input string to simulate stream.
nc -lk 9999
"流计算" 终端
/usr/local/spark/bin/spark-submit StructuredNetworkWordCountFileSink.py
End.
[Spark] 08 - Structured Streaming的更多相关文章
- Spark之Structured Streaming
目录 Part V. Streaming Stream Processing Fundamentals Structured Streaming Basics Event-Time and State ...
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- Structured Streaming编程 Programming Guide
Structured Streaming编程 Programming Guide Overview Quick Example Programming Model Basic Concepts Han ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)
本次此时是在SPARK2,3 structured streaming下测试,不过这种方案,在spark2.2 structured streaming下应该也可行(请自行测试).以下是我测试结果: ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
随机推荐
- SpringBoot:实现定时任务
一.定时任务实现的几种方式: Timer 这是java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务.使用这种方式可以让你的程序按照某一个频度执 ...
- Android Studio启动模拟器失败
启动Android Studio的模拟器报“Emulator: Process finished with exit code -1073741819 (0xC0000005)”错误教程: 1.进入该 ...
- DES加解密工具类
这两天在跟友商对接接口,在对外暴露接口的时候,因为友商不需要登录即可访问对于系统来说存在安全隐患,所以需要友商在调用接口的时候需要将数据加密,系统解密验证后才执行业务.所有的加密方式并不是万能的,只是 ...
- C++ 线程安全的单例模式总结
什么是线程安全? 在拥有共享数据的多条线程并行执行的程序中,线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,不会出现数据污染等意外情况. 如何保证线程安全? 给共享的资源加把锁,保证每 ...
- LightOJ - 1370 Bi-shoe and Phi-shoe 欧拉函数 题解
题目: Bamboo Pole-vault is a massively popular sport in Xzhiland. And Master Phi-shoe is a very popula ...
- Vmware启动ubuntu 出现错误。
Vmware启动ubuntu 出现错误“以独占方式锁定此配置文件失败. 可能其它正在运行VMware进程在使用此配置文件”. 在网上查找了很多方法,法(1)试过在启动任务管理器中“结束与VMware有 ...
- Spring框架的重要问题
这篇文章总结了一些关于Spring框架的重要问题,这些问题都是你在面试或笔试过程中可能会被问到的. 目录 Spring概述 依赖注入 Spring Beans Spring注解 Spring的对象访问 ...
- zookeeper快速上手
## # zookeeper的基本功能和应用场景 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件. ...
- 奶牛跟蜗牛,哪种动物智商更高?——T检验帮你找到答案
奶牛跟蜗牛,都是“牛”,那么哪种动物更“牛”,智商更高呢?此时就能用到T检验来找答案~ T 检验(独立样本 T 检验),用于分析定类数据与定量数据之间的关系情况.例如,在本研究中,我们想探究奶牛跟 ...
- 【selenium】-自动化测试的前提
本文由小编根据慕课网视频亲自整理,转载请注明出处和作者. 1.为什么要做自动化? 2.是否适合做自动化? 时间:时间如果很紧,连做功能测试的时间都很紧张,是没有时间做自动化的. 人员:如果都是初级的测 ...