Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一、Zookeeper集群搭建
为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。
1.1 下载 & 解压
下载对应版本Zookeeper,这里我下载的版本3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
# 下载
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
# 解压
tar -zxvf zookeeper-3.4.14.tar.gz
1.2 修改配置
拷贝三份zookeeper安装包。分别进入安装目录的conf目录,拷贝配置样本zoo_sample.cfg为zoo.cfg并进行修改,修改后三份配置文件内容分别如下:
zookeeper01配置:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/01
dataLogDir=/usr/local/zookeeper-cluster/log/01
clientPort=2181
# server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里
# 指名集群间通讯端口和选举端口
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
如果是多台服务器,则集群中每个节点通讯端口和选举端口可相同,IP地址修改为每个节点所在主机IP即可。
zookeeper02配置,与zookeeper01相比,只有dataLogDir和dataLogDir不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/02
dataLogDir=/usr/local/zookeeper-cluster/log/02
clientPort=2182
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
zookeeper03配置,与zookeeper01,02相比,也只有dataLogDir和dataLogDir不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/03
dataLogDir=/usr/local/zookeeper-cluster/log/03
clientPort=2183
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
配置参数说明:
- tickTime:用于计算的基础时间单元。比如session超时:N*tickTime;
- initLimit:用于集群,允许从节点连接并同步到 master节点的初始化连接时间,以tickTime的倍数来表示;
- syncLimit:用于集群, master主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);
- dataDir:数据存储位置;
- dataLogDir:日志目录;
- clientPort:用于客户端连接的端口,默认2181
1.3 标识节点
分别在三个节点的数据存储目录下新建myid文件,并写入对应的节点标识。Zookeeper集群通过myid文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出leader节点。
创建存储目录:
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/01
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/02
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/03
创建并写入节点标识到myid文件:
#server1
echo "1" > /usr/local/zookeeper-cluster/data/01/myid
#server2
echo "2" > /usr/local/zookeeper-cluster/data/02/myid
#server3
echo "3" > /usr/local/zookeeper-cluster/data/03/myid
1.4 启动集群
分别启动三个节点:
# 启动节点1
/usr/app/zookeeper-cluster/zookeeper01/bin/zkServer.sh start
# 启动节点2
/usr/app/zookeeper-cluster/zookeeper02/bin/zkServer.sh start
# 启动节点3
/usr/app/zookeeper-cluster/zookeeper03/bin/zkServer.sh start
1.5 集群验证
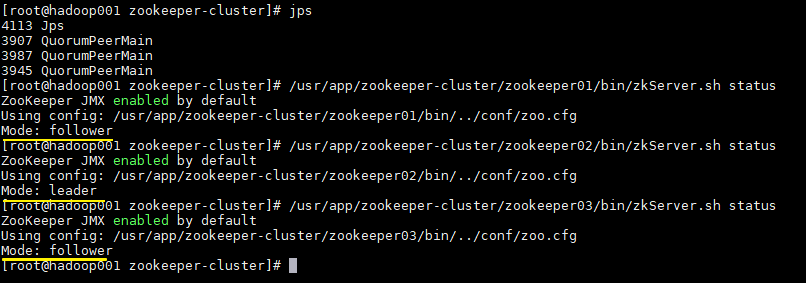
使用jps查看进程,并且使用zkServer.sh status查看集群各个节点状态。如图三个节点进程均启动成功,并且两个节点为follower节点,一个节点为leader节点。
二、Kafka集群搭建
2.1 下载解压
Kafka安装包官方下载地址:http://kafka.apache.org/downloads ,本用例下载的版本为2.2.0,下载命令:
# 下载
wget https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
# 解压
tar -xzf kafka_2.12-2.2.0.tgz
这里j解释一下kafka安装包的命名规则:以
kafka_2.12-2.2.0.tgz为例,前面的2.12代表Scala的版本号(Kafka采用Scala语言进行开发),后面的2.2.0则代表Kafka的版本号。
2.2 拷贝配置文件
进入解压目录的config目录下 ,拷贝三份配置文件:
# cp server.properties server-1.properties
# cp server.properties server-2.properties
# cp server.properties server-3.properties
2.3 修改配置
分别修改三份配置文件中的部分配置,如下:
server-1.properties:
# The id of the broker. 集群中每个节点的唯一标识
broker.id=0
# 监听地址
listeners=PLAINTEXT://hadoop001:9092
# 数据的存储位置
log.dirs=/usr/local/kafka-logs/00
# Zookeeper连接地址
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
server-2.properties:
broker.id=1
listeners=PLAINTEXT://hadoop001:9093
log.dirs=/usr/local/kafka-logs/01
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
server-3.properties:
broker.id=2
listeners=PLAINTEXT://hadoop001:9094
log.dirs=/usr/local/kafka-logs/02
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
这里需要说明的是log.dirs指的是数据日志的存储位置,确切的说,就是分区数据的存储位置,而不是程序运行日志的位置。程序运行日志的位置是通过同一目录下的log4j.properties进行配置的。
2.4 启动集群
分别指定不同配置文件,启动三个Kafka节点。启动后可以使用jps查看进程,此时应该有三个zookeeper进程和三个kafka进程。
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
bin/kafka-server-start.sh config/server-3.properties
2.5 创建测试主题
创建测试主题:
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 \
--replication-factor 3 \
--partitions 1 --topic my-replicated-topic
创建后可以使用以下命令查看创建的主题信息:
bin/kafka-topics.sh --describe --bootstrap-server hadoop001:9092 --topic my-replicated-topic
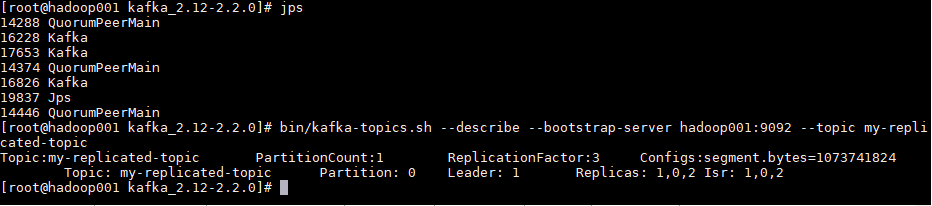
可以看到分区0的有0,1,2三个副本,且三个副本都是可用副本,都在ISR(in-sync Replica 同步副本)列表中,其中1为首领副本,此时代表集群已经搭建成功。
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群的更多相关文章
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- TCP/UDP 报头格式
参考:https://www.cnblogs.com/MRRAOBX/articles/4540228.html TCP: 源端口号 以及 目的端口号 32位 序列号 seq 确认号 ACK ...
- Python 产生两个方法将不被所述多个随机数的特定范围内反复
在最近的实验中进行.通过随机切割一定比例所需要的数据这两个部分.事实上这个问题的核心是生成随机数的问题将不再重复.递归方法,首先想到的,然后我们发现Python中竟然已经提供了此方法的函数,能够直接使 ...
- VS2005下如何安装配置编译Qt4.6
本文将使用简单的几个步骤说明在VC 2005下如何编译安装并开发Qt4.6应用程序,其实大部分方法和Qt4.6.0是一样的,不过Qt4.6.0集成了Qt Creater,目录的形式有点改变了,现在我就 ...
- HDU 4861(多校)1001 Couple doubi
Problem Description DouBiXp has a girlfriend named DouBiNan.One day they felt very boring and decide ...
- UVa 11400 Lighting System Design(DP 照明设计)
意甲冠军 地方照明系统设计 总共需要n不同类型的灯泡 然后进入 每个灯电压v 相应电压电源的价格k 每一个灯泡的价格c 须要这样的灯泡的数量l 电压低的灯泡能够用电压高的灯泡替换 ...
- [Unity3D]Unity3D叙利亚NGUI血液和技能的冷却效果
---------------------------------------------------------------------------------------------------- ...
- uwp 沉浸式状态栏
//隐藏状态栏if (ApiInformation.IsTypePresent(typeof(StatusBar).ToString())) { StatusBar statusBar = Statu ...
- python_matplotlib cannot import name _thread on mac
最后的2行错误信息是 from six.moves import _thread ImportError: cannot import name _thread 1 2 发现是six出现了问题,用pi ...
- apache本地服务器的配置流程
安装Apache 一.目的: 1. 能够有一个测试的服务器,不是所有的特殊网络服务都能找到免费的! 二.为什么是 "Apache" 1. 使用最广的 Web 服务器 2. Mac自 ...
- ArcGIS 10.3 for Server 在windows下的安装教程
原文:ArcGIS 10.3 for Server 在windows下的安装教程 以下是10.2的教程,10.3同样适用. 许可文件: ArcGIS For Server10.3许可文件 - 下载频道 ...