42 在Raspberry Pi上安装dlib表情识别
1dlib获取关键点
https://www.jianshu.com/p/848014d8dea9
https://www.pyimagesearch.com/2017/05/01/install-dlib-raspberry-pi/
库下载
https://github.com/davisking/dlib
表情识别教程
https://www.cnblogs.com/qsyll0916/p/8893790.html

识别代码
https://gitee.com/Andrew_Qian/face/blob/master/from_video.py
依赖权重
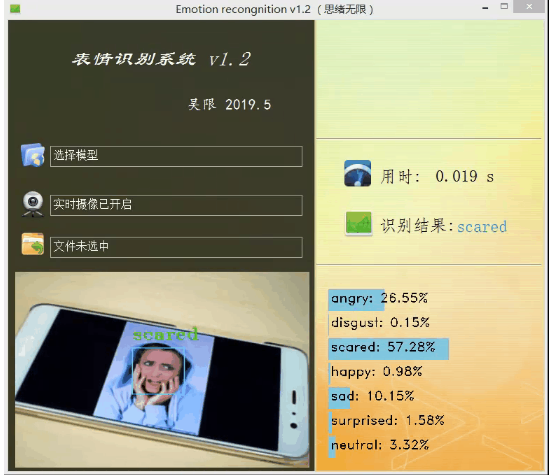
二人脸表情识别系统(含UI界面,python实现
https://blog.csdn.net/qq_32892383/article/details/91347164
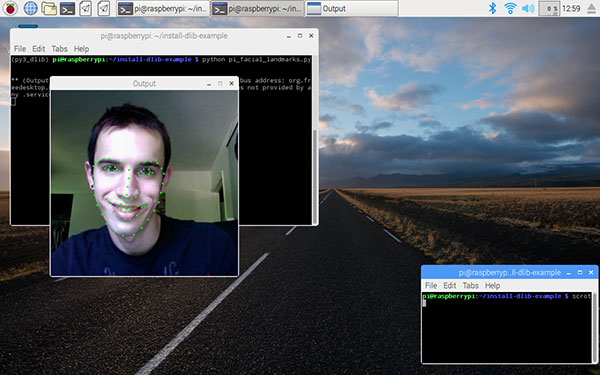
dilb程序实现
面部表情跟踪的原理就是检测人脸特征点,根据特定的特征点可以对应到特定的器官,比如眼睛、鼻子、嘴巴、耳朵等等,以此来跟踪各个面部器官的动作。
https://blog.csdn.net/hongbin_xu/article/details/79926839


三、安装依赖库
dlib需要以下依赖:
- Boost
- Boost.Python
- CMake
- X11
安装方法:
$ sudo apt-get update
$ sudo apt-get install build-essential cmake libgtk-3-dev libboost-all-dev -y
四、用pip3安装其他dlib运行依赖的库
$ pip3 install numpy
$ pip3 install scipy
$ pip3 install scikit-image
五、正式安装
解压下载好的dlib,进入dlib目录后
$ sudo python3 setup.py install
这一步耗时是最长的了,耐心等待。
六、验证
$ python3
Python 3.4.2 (default, Oct 19 2014, 13:31:11)
[GCC 4.9.1] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlib
>>>
七、把虚拟内存和GPU使用内存改回原始值
修改方法见“二、修改前的准备工作”
收工。
python代码
#!Anaconda/anaconda/python
#coding: utf-8 """
从视屏中识别人脸,并实时标出面部特征点
""" import dlib #人脸识别的库dlib
import numpy as np #数据处理的库numpy
import cv2 #图像处理的库OpenCv class face_emotion(): def __init__(self):
# 使用特征提取器get_frontal_face_detector
self.detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
self.predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") #建cv2摄像头对象,这里使用电脑自带摄像头,如果接了外部摄像头,则自动切换到外部摄像头
self.cap = cv2.VideoCapture(0)
# 设置视频参数,propId设置的视频参数,value设置的参数值
self.cap.set(3, 480)
# 截图screenshoot的计数器
self.cnt = 0 def learning_face(self): # 眉毛直线拟合数据缓冲
line_brow_x = []
line_brow_y = [] # cap.isOpened() 返回true/false 检查初始化是否成功
while(self.cap.isOpened()): # cap.read()
# 返回两个值:
# 一个布尔值true/false,用来判断读取视频是否成功/是否到视频末尾
# 图像对象,图像的三维矩阵
flag, im_rd = self.cap.read() # 每帧数据延时1ms,延时为0读取的是静态帧
k = cv2.waitKey(1) # 取灰度
img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY) # 使用人脸检测器检测每一帧图像中的人脸。并返回人脸数rects
faces = self.detector(img_gray, 0) # 待会要显示在屏幕上的字体
font = cv2.FONT_HERSHEY_SIMPLEX # 如果检测到人脸
if(len(faces)!=0): # 对每个人脸都标出68个特征点
for i in range(len(faces)):
# enumerate方法同时返回数据对象的索引和数据,k为索引,d为faces中的对象
for k, d in enumerate(faces):
# 用红色矩形框出人脸
cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0, 0, 255))
# 计算人脸热别框边长
self.face_width = d.right() - d.left() # 使用预测器得到68点数据的坐标
shape = self.predictor(im_rd, d)
# 圆圈显示每个特征点
for i in range(68):
cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8)
#cv2.putText(im_rd, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
# (255, 255, 255)) # 分析任意n点的位置关系来作为表情识别的依据
mouth_width = (shape.part(54).x - shape.part(48).x) / self.face_width # 嘴巴咧开程度
mouth_higth = (shape.part(66).y - shape.part(62).y) / self.face_width # 嘴巴张开程度
# print("嘴巴宽度与识别框宽度之比:",mouth_width_arv)
# print("嘴巴高度与识别框高度之比:",mouth_higth_arv) # 通过两个眉毛上的10个特征点,分析挑眉程度和皱眉程度
brow_sum = 0 # 高度之和
frown_sum = 0 # 两边眉毛距离之和
for j in range(17, 21):
brow_sum += (shape.part(j).y - d.top()) + (shape.part(j + 5).y - d.top())
frown_sum += shape.part(j + 5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y) # self.brow_k, self.brow_d = self.fit_slr(line_brow_x, line_brow_y) # 计算眉毛的倾斜程度
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线
self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的 brow_hight = (brow_sum / 10) / self.face_width # 眉毛高度占比
brow_width = (frown_sum / 5) / self.face_width # 眉毛距离占比
# print("眉毛高度与识别框高度之比:",round(brow_arv/self.face_width,3))
# print("眉毛间距与识别框高度之比:",round(frown_arv/self.face_width,3)) # 眼睛睁开程度
eye_sum = (shape.part(41).y - shape.part(37).y + shape.part(40).y - shape.part(38).y +
shape.part(47).y - shape.part(43).y + shape.part(46).y - shape.part(44).y)
eye_hight = (eye_sum / 4) / self.face_width
# print("眼睛睁开距离与识别框高度之比:",round(eye_open/self.face_width,3)) # 分情况讨论
# 张嘴,可能是开心或者惊讶
if round(mouth_higth >= 0.03):
if eye_hight >= 0.056:
cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
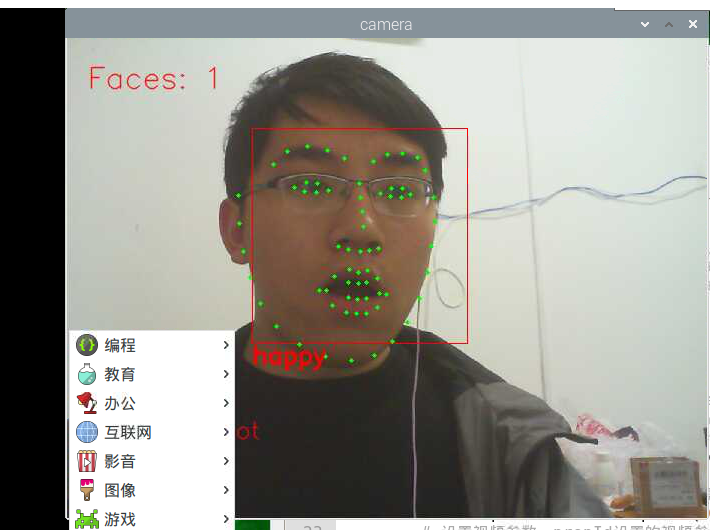
cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4) # 没有张嘴,可能是正常和生气
else:
if self.brow_k <= -0.3:
cv2.putText(im_rd, "angry", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4) # 标出人脸数
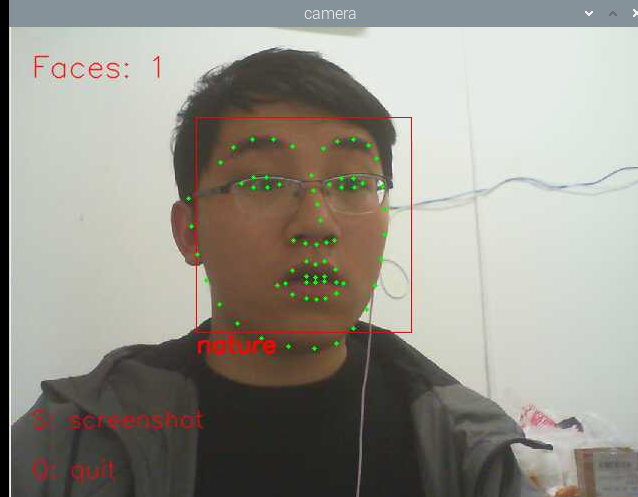
cv2.putText(im_rd, "Faces: "+str(len(faces)), (20,50), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
else:
# 没有检测到人脸
cv2.putText(im_rd, "No Face", (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA) # 添加说明
im_rd = cv2.putText(im_rd, "S: screenshot", (20, 400), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
im_rd = cv2.putText(im_rd, "Q: quit", (20, 450), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA) # 按下s键截图保存
if (k == ord('s')):
self.cnt+=1
cv2.imwrite("screenshoot"+str(self.cnt)+".jpg", im_rd) # 按下q键退出
if(k == ord('q')):
break # 窗口显示
cv2.imshow("camera", im_rd) # 释放摄像头
self.cap.release() # 删除建立的窗口
cv2.destroyAllWindows() if __name__ == "__main__":
my_face = face_emotion()
my_face.learning_face()
# *_*coding:utf-8 *_*
# author: 许鸿斌 import sys
import cv2
import dlib
import os
import logging
import datetime
import numpy as np def cal_face_boundary(img, shape):
for index_, pt in enumerate(shape.parts()):
if index_ == 0:
x_min = pt.x
x_max = pt.x
y_min = pt.y
y_max = pt.y
else:
if pt.x < x_min:
x_min = pt.x if pt.x > x_max:
x_max = pt.x if pt.y < y_min:
y_min = pt.y if pt.y > y_max:
y_max = pt.y # print('x_min:{}'.format(x_min))
# print('x_max:{}'.format(x_max))
# print('y_min:{}'.format(y_min))
# print('y_max:{}'.format(y_max)) # 如果出现负值,即人脸位于图像框之外的情况,应当忽视图像外的部分,将负值置为0
if x_min < 0:
x_min = 0 if y_min < 0:
y_min = 0 if x_min == x_max or y_min == y_max:
return None
else:
return img[y_min:y_max, x_min:x_max] def draw_left_eyebrow(img, shape):
# 17 - 21
pt_pos = []
for index, pt in enumerate(shape.parts()[17:21 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos)-1):
cv2.line(img, pt_pos[num], pt_pos[num+1], 255, 2) def draw_right_eyebrow(img, shape):
# 22 - 26
pt_pos = []
for index, pt in enumerate(shape.parts()[22:26 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) def draw_left_eye(img, shape):
# 36 - 41
pt_pos = []
for index, pt in enumerate(shape.parts()[36:41 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) cv2.line(img, pt_pos[0], pt_pos[-1], 255, 2) def draw_right_eye(img, shape):
# 42 - 47
pt_pos = []
for index, pt in enumerate(shape.parts()[42:47 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) cv2.line(img, pt_pos[0], pt_pos[-1], 255, 2) def draw_nose(img, shape):
# 27 - 35
pt_pos = []
for index, pt in enumerate(shape.parts()[27:35 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) cv2.line(img, pt_pos[0], pt_pos[4], 255, 2)
cv2.line(img, pt_pos[0], pt_pos[-1], 255, 2)
cv2.line(img, pt_pos[3], pt_pos[-1], 255, 2) def draw_mouth(img, shape):
# 48 - 59
pt_pos = []
for index, pt in enumerate(shape.parts()[48:59 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) cv2.line(img, pt_pos[0], pt_pos[-1], 255, 2) # 60 - 67
pt_pos = []
for index, pt in enumerate(shape.parts()[60:]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) cv2.line(img, pt_pos[0], pt_pos[-1], 255, 2) def draw_jaw(img, shape):
# 0 - 16
pt_pos = []
for index, pt in enumerate(shape.parts()[0:16 + 1]):
pt_pos.append((pt.x, pt.y)) for num in range(len(pt_pos) - 1):
cv2.line(img, pt_pos[num], pt_pos[num + 1], 255, 2) # 获取logger实例,如果参数为空则返回root logger
logger = logging.getLogger("PedestranDetect")
# 指定logger输出格式
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')
# 文件日志
# file_handler = logging.FileHandler("test.log")
# file_handler.setFormatter(formatter) # 可以通过setFormatter指定输出格式
# 控制台日志
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter # 也可以直接给formatter赋值
# 为logger添加的日志处理器
# logger.addHandler(file_handler)
logger.addHandler(console_handler)
# 指定日志的最低输出级别,默认为WARN级别
logger.setLevel(logging.INFO) pwd = os.getcwd()
predictor_path = os.path.join(pwd, 'shape_predictor_68_face_landmarks.dat') logger.info(u'导入人脸检测器')
detector = dlib.get_frontal_face_detector()
logger.info(u'导入人脸特征点检测器')
predictor = dlib.shape_predictor(predictor_path) cap = cv2.VideoCapture(0)
cnt = 0
total_time = 0
start_time = 0
while(1): ret, frame = cap.read()
# cv2.imshow("window", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
dets = detector(img, 1)
if dets:
logger.info('Face detected')
else:
logger.info('No face detected')
for index, face in enumerate(dets):
# print('face {}; left {}; top {}; right {}; bottom {}'.format(index, face.left(), face.top(), face.right(),
# face.bottom()))
shape = predictor(img, face) # for index_, pt in enumerate(shape.parts()):
# pt_pos = (pt.x, pt.y)
# cv2.circle(frame, pt_pos, 2, (255, 0, 0), 1) features = np.zeros(img.shape[0:-1], dtype=np.uint8)
for index_, pt in enumerate(shape.parts()):
pt_pos = (pt.x, pt.y)
cv2.circle(features, pt_pos, 2, 255, 1) draw_left_eyebrow(features, shape)
draw_right_eyebrow(features, shape)
draw_left_eye(features, shape)
draw_right_eye(features, shape)
draw_nose(features, shape)
draw_mouth(features, shape)
draw_jaw(features, shape) logger.info('face shape: {} {}'.format(face.right()-face.left(), face.bottom()-face.top()))
faceROI = cal_face_boundary(features, shape)
logger.info('ROI shape: {}'.format(faceROI.shape))
# faceROI = features[face.top():face.bottom(), face.left():face.right()]
faceROI = cv2.resize(faceROI, (500, 500), interpolation=cv2.INTER_LINEAR)
# logger.info('face {}'.format(index))
cv2.imshow('face {}'.format(index), faceROI) if cnt == 0:
start_time = datetime.datetime.now()
cnt += 1
elif cnt == 100:
end_time = datetime.datetime.now()
frame_rate = float(100) / (end_time-start_time).seconds
# logger.info(start_time)
# logger.info(end_time)
logger.info(u'帧率:{:.2f}fps'.format(frame_rate))
cnt = 0
else:
cnt += 1 # logger.info(cnt)
42 在Raspberry Pi上安装dlib表情识别的更多相关文章
- 在Raspberry Pi上安装XBMC
2013-05-22 XBMC is a free and open source media player application developed by the XBMC Foundation, ...
- 在Archlinux ARM - Raspberry Pi上安装Google coder
升级软件包 一个 pacman 命令就可以升级整个系统.花费的时间取决于系统有多老.这个命令会同步非本地(local)软件仓库并升级系统的软件包: # pacman -Syu 提示:确保make以及g ...
- live555在Raspberry Pi上的点播/直播
1.live555在Raspberry Pi上的点播 live555MediaServer这个实例是个简单的服务器,支持多媒体点播,直接在Raspberry Pi上编译运行,或者通过交叉编译出ARM核 ...
- VLOG丨树莓派Raspberry Pi 3安装PLEX并挂载USB硬盘打造最牛的微型家庭影音服务器2018
视频介绍 树莓派3安装目前最流行的PLEX服务器,实现既能最大限度降低功耗,也能随时随地观看分享影片. 一.在树莓派下安装PLEX媒体服务器 1.在终端,将你的树莓派更新至最新 sudo apt up ...
- [深度学习工具]·极简安装Dlib人脸识别库
[深度学习工具]·极简安装Dlib人脸识别库 Dlib介绍 Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具.它广泛应用于工业界和学术界,包 ...
- 让Mono 4在Raspberry Pi上飞
最近公司有项目想要在树莓派上做,代替原来的工控机(我们是把工控主机当作小的主机用,一台小的工控主机最少也要600左右,而树莓派只要200多).于是,公司买了一个Raspberry Pi B+和一个Ra ...
- Raspberry Pi 4B 安装 CentOS 8
最近新入手一块Raspberry Pi 4B 8G的板子,想在这块板子上搭建CentOS 8的环境.经过数次采坑终于安装成功. 准备条件: 1.Raspberry Pi 4B 板子 + SD卡 2. ...
- Raspberry Pi 中安装Mono
摘自:http://www.phodal.com/blog/user-csharp-develop-raspberry-pi-application/ Raspberry Pi C# Mono Lin ...
- 树莓派(1)- Raspberry Pi 3B 安装系统并联网
一.背景 昨天到手淘宝买的3B,既然买了就不能让它吃灰,动起来. 二.物料 名称 说明 硬件 树莓派3B 主体 树莓派电源 5V 2A sd卡 4G低速(推荐是16G class10),我手头只有这 ...
随机推荐
- Android开发笔记:Android开发环境搭建
基于Eclipse开发 1. 安装JDK 首先进入JDK下载页面,选择需要的版本下载安装. JDK 下载地址:https://www.oracle.com/technetwork/java/javas ...
- 网络传播模型Python代码实现
SI模型 import numpy as np import matplotlib.pyplot as plt import smallworld as sw #邻接矩阵 a = sw.a # 感染率 ...
- [译]发布ABP v0.19包含Angular UI选项
发布ABP v0.19包含Angular UI选项 ABP v0.19已发布,包含解决的~90个问题和600+次提交. 新功能 Angular UI 终于,ABP有了一个SPA UI选项,使用最新的A ...
- Codeforces Round #602 (Div. 2, based on Technocup 2020 Elimination Round 3) E. Arson In Berland Forest 二分 前缀和
E. Arson In Berland Forest The Berland Forest can be represented as an infinite cell plane. Every ce ...
- flag 履行我的flag
以后数组开小就不吃饭!!!!!! 上午考试不吃午饭 下午考试不吃晚饭 晚上考试不吃早饭 我以后还能吃饭吗 11.12距离csp-s还有2天,我的数组开小了,履行承诺,不吃饭了
- pyqt添加启动等待界面
一.实验环境 1.Windows7x64_SP1 2.anaconda3.7 + python3.7(anaconda集成,不需单独安装) 3.pyinstaller3.5 #使用pyinstalle ...
- Zookeeper集群的"脑裂"问题处理 - 运维总结
关于集群中的"脑裂"问题,之前已经在这里详细介绍过,下面重点说下Zookeeper脑裂问题的处理办法.ooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调 ...
- 三、动态SQL
动态SQL MyBatis的动态SQL是基于OGNL表达式的,它可以帮助我们方便的在SQL语句中实现某些逻辑. 动态SQL的元素 元素 作用 备注 if 判断语句 单条件分支判断 choose.whe ...
- 二、Mapper映射文件
Mapper映射文件 mapper.xml映射文件主要是用来编写SQL语句的,以及一些结果集的映射关系的编写,还有就是缓存的一些配置等等. 在映射文件里面可以配置以下标签: 元素名称 描述 备注 se ...
- QOS限速
XX涉及的QOS限速主要有两种: 第一种是针对一个端口下双向IP互访: 第二种是针对多个端口下双向IP互访:(聚合car) 聚合car:是指能够对多个业务使用同一个car进行流量监控,即如果多个端口应 ...