使用R语言预测产品销量
使用R语言预测产品销量
通过不同的广告投入,预测产品的销量。因为响应变量销量是一个连续的值,所以这个问题是一个回归问题。数据集共有200个观测值,每一组观测值对应一种市场情况。
数据特征
- TV:对于一个给定市场的单一产品,用于电视上的广告费用(以千为单位)
- Radio:用于广告媒体上投资的广告费用
- Newspaper:用于报纸媒体上的广告费用
响应
- Sales:对应产品的销量
加载数据
> data <- read.csv("http://www-bcf.usc.edu/~gareth/ISL/Advertising.csv",colClasses=c("NULL",NA,NA,NA,NA))
> head(data)
TV Radio Newspaper Sales
1 230.1 37.8 69.2 22.1
2 44.5 39.3 45.1 10.4
3 17.2 45.9 69.3 9.3
4 151.5 41.3 58.5 18.5
5 180.8 10.8 58.4 12.9
6 8.7 48.9 75.0 7.2
# 显示Sales和TV的关系
> plot(data$TV, data$Sales, col="red", xlab='TV', ylab='sales')

# 用线性回归拟合Sales和TV广告的关系
> fit=lm(Sales~TV,data=data)
# 查看估算出来的系数
> coef(fit)
(Intercept) TV
7.03259355 0.04753664
# 显示拟合出来的模型的线
> abline(fit)

# 显示Sales和Radio的关系
> plot(data$Radio, data$Sales, col="red", xlab='Radio', ylab='Sales')
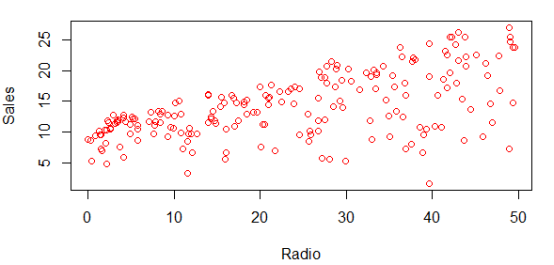
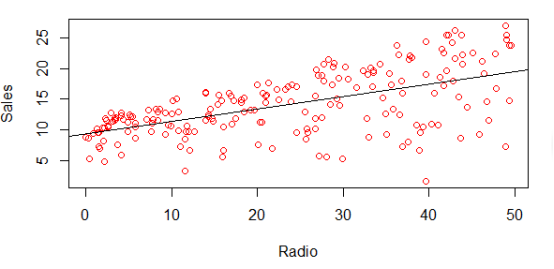
# 用线性回归拟合Sales和Radio广告的关系
> fit1=lm(Sales~Radio,data=data)
# 查看估算出来的系数
> coef(fit1)
(Intercept) Radio
9.3116381 0.2024958
# 显示拟合出来的模型的线
> abline(fit1)
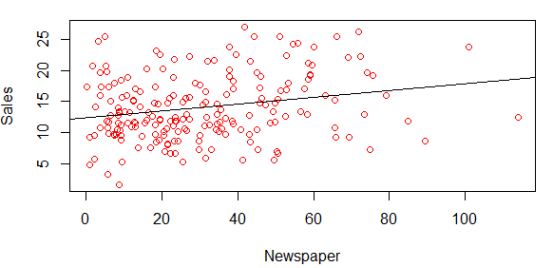
# 显示Sales和Newspaper的关系
> plot(data$Newspaper, data$Sales, col="red", xlab='Radio', ylab='Sales')

# 用线性回归拟合Sales和Radio广告的关系
> fit2=lm(Sales~Newspaper,data=data)
# 查看估算出来的系数
> coef(fit2)
(Intercept) Newspaper
12.3514071 0.0546931
# 显示拟合出来的模型的线
> abline(fit2)
# 创建散点图矩阵
> pairs(~Sales+TV+Radio+Newspaper,data=data, main="Scatterplot Matrix")

第一行图形显示TV,Radio,Newspaper对Sales的影响。纵轴为Sales,横轴分别为TV,Radio,Newspaper。从图中可以看出,TV特征和销量是有比较强的线性关系的。
划分训练集和测试集
> trainRowCount <- floor(0.8 * nrow(data))
> set.seed(1)
> trainIndex <- sample(1:nrow(data), trainRowCount)
> train <- data[trainIndex,]
> test <- data[-trainIndex,]
> dim(data)
[1] 200 4
> dim(train)
[1] 160 4
> dim(test)
[1] 40 4
拟合线性回归模型
> model <- lm(Sales~TV+Radio+Newspaper, data=train)
> summary(model)
Call:
lm(formula = Sales ~ TV + Radio + Newspaper, data = train) Residuals:
Min 1Q Median 3Q Max
-8.7734 -0.9290 0.2475 1.2213 2.8971 Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.840243 0.353175 8.042 2.07e-13 ***
TV 0.046178 0.001579 29.248 < 2e-16 ***
Radio 0.189668 0.009582 19.795 < 2e-16 ***
Newspaper -0.001156 0.006587 -0.176 0.861
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 1.745 on 156 degrees of freedom
Multiple R-squared: 0.8983, Adjusted R-squared: 0.8963
F-statistic: 459.2 on 3 and 156 DF, p-value: < 2.2e-16
预测和计算均方根误差
> predictions <- predict(model, test)
> mean((test["Sales"] - predictions)^2)
[1] 2.050666
特征选择
在之前的各变量和销量之间关系中,我们看到Newspaper和销量之间的线性关系比较弱,并且上面模型中Newspaper的系数为负数,现在去掉这个特征,看看线性回归预测的结果的均方根误差。
> model1 <- lm(Sales~TV+Radio, data=train)
> summary(model1)
Call:
lm(formula = Sales ~ TV + Radio, data = train) Residuals:
Min 1Q Median 3Q Max
-8.7434 -0.9121 0.2538 1.1900 2.9009 Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.821417 0.335455 8.411 2.35e-14 ***
TV 0.046157 0.001569 29.412 < 2e-16 ***
Radio 0.189132 0.009053 20.891 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 1.74 on 157 degrees of freedom
Multiple R-squared: 0.8983, Adjusted R-squared: 0.897
F-statistic: 693 on 2 and 157 DF, p-value: < 2.2e-16 > predictions1 <- predict(model1, test)
> mean((test["Sales"] - predictions1)^2)
[1] 2.050226
从上可以看到2.050226<2.050666,将Newspaper这个特征移除后,得到的均方根误差变小了,说明Newspaper不适合作为预测销量的特征,则去掉Newspaper特征后得到了新的模型。
使用R语言预测产品销量的更多相关文章
- R语言预测实战(游浩麟)笔记1
预测流程 确定主题.指标.主体.精度.周期.用户.成本和数据七要素. 收集数据.内容划分.收集原则. 选择方法.主要方法有自相关分析.偏相关分析.频谱分析.趋势分析.聚类分析.关联分析.相关分析.互相 ...
- R语言预测实战(第一章)
本例使用forecast包中自带的数据集wineind,它表示从1980年1月到1994年8月, 由葡萄酒生产商销售的容量不到1升的澳大利亚酒的总量.数据示意如下: #观察曲线簇 len=1993-1 ...
- R语言预测实战(第二章--预测方法论)
2.1预测流程 从确定预测主题开始,一次进行数据收集.选择方法.分析规律.建立模型.评估效果直到发布模型. 2.2.1确定主题 (1)指标:表达的是数量特征,预测的结果也通常是通过指标的取值来体现. ...
- R语言预测实战(游浩麟)笔记2
特征构建技术 特征变换,对原始的某个特征通过一定的规则或映射得到新特征的方法,主要方法包括概念分层.标准化.离散化.函数变换以及深入表达.特征变换主要由人工完成,属于比较基础的特征构建方法. 概念分层 ...
- 手把手教你学习R语言
本文为带大家了解R语言以及分段式的步骤教程! 人们学习R语言时普遍存在缺乏系统学习方法的问题.学习者不知道从哪开始,如何进行,选择什么学习资源.虽然网络上有许多不错的免费学习资源,然而它们多过了头,反 ...
- R语言︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
XGBoost不仅仅可以用来做分类还可以做时间序列方面的预测,而且已经有人做的很好,可以见最后的案例. 应用一:XGBoost用来做预测 ------------------------------- ...
- 基于R语言的时间序列分析预测
数据来源: R语言自带 Nile 数据集(尼罗河流量) 分析工具:R-3.5.0 & Rstudio-1.1.453 #清理环境,加载包 rm(list=ls()) library(forec ...
- 预测分析建模 Python与R语言实现
预测分析建模 Python与R语言实现 目录 前言 第1章 分析与数据科学1第2章 广告与促销10第3章 偏好与选择24第4章 购物篮分析31第5章 经济数据分析42第6章 运营管理56第7章 文本分 ...
- R语言利用ROCR评测模型的预测能力
R语言利用ROCR评测模型的预测能力 说明 受试者工作特征曲线(ROC),这是一种常用的二元分类系统性能展示图形,在曲线上分别标注了不同切点的真正率与假正率.我们通常会基于ROC曲线计算处于曲线下方的 ...
随机推荐
- C#基础加强篇---委托、Lamada表达式和事件(中)
2.Lamada表达式 C#共有两种匿名函数:匿名方法和Lamada表达式.在2.0之前的C#版本中,创建委托的唯一方法是使用命名方法.C#2.0中引入了匿名方法,匿名方法就是没有名称的方法. ...
- 微信小程序把玩(三十四)Audio API
原文:微信小程序把玩(三十四)Audio API 没啥可值得太注意的地方 重要属性: 1. wx.getBackgroundAudioPlayerState(object) 获取播放状态 2.wx.p ...
- cn_sql_server_2012_enterprise_edition_x86_x64_dvd_813295 序列号
cn_sql_server_2012_enterprise_edition_x86_x64_dvd_813295 序列号 MICROSOFT SQL SERVER 2012 ENTERPRISE CO ...
- linux c 读写 ini 配置文件
.ini 文件格式如下: [section1] key1=value ... keyn=value [section2] key1=value ... keyn=value 代码如下: #define ...
- 进程交互还可以使用QSharedMemory
官方例子: http://doc.qt.io/qt-5/qtcore-ipc-sharedmemory-example.html 查了一下,QSharedMemory没有自带任何信号.我的想法: 1. ...
- PHP发送邮件功能实现(使用163邮箱)
第一步 我用的是163邮箱发送邮件,做一个尝试,在尝试之前,需要要开启163邮箱的授权码如图所示,请记住您的授权码,将在之后的步骤中用到 第二步 需要下载一个类PHPMailer,我有这个资源已经上传 ...
- Unity 入門 - 延遲解析
本文大纲: 小引 共享的范例代码 使用 Lazy<T> 使用自动工厂 注入自定义工厂 小引 当我们说「解析某个型别/组件」时,意思通常是呼叫某类别的建构函式,以建立其实例(instance ...
- LFS Linux From Scratch 笔记2(经验非教程)BLFS
LFS 完了. 其实还没完,还要装一些其他的组件,系统才算是对人类有用的系统. 正好这里有个BLFS Beyound Linux From Scratch 的教程. 其实,按照现有的可运行的LFS系统 ...
- [2017.02.05] 阅读《Efficient C++》思维导图
- kafka笔记2
Kafka是使用java开发的程序,所以它可以运行在多种操作系统上,安装Kafka之前,需要先安装Java环境,再安装zookeeper broker常规配置 1.broker.id 每个broker ...