关于网站登录后的页面操作所携带的不同cookie值
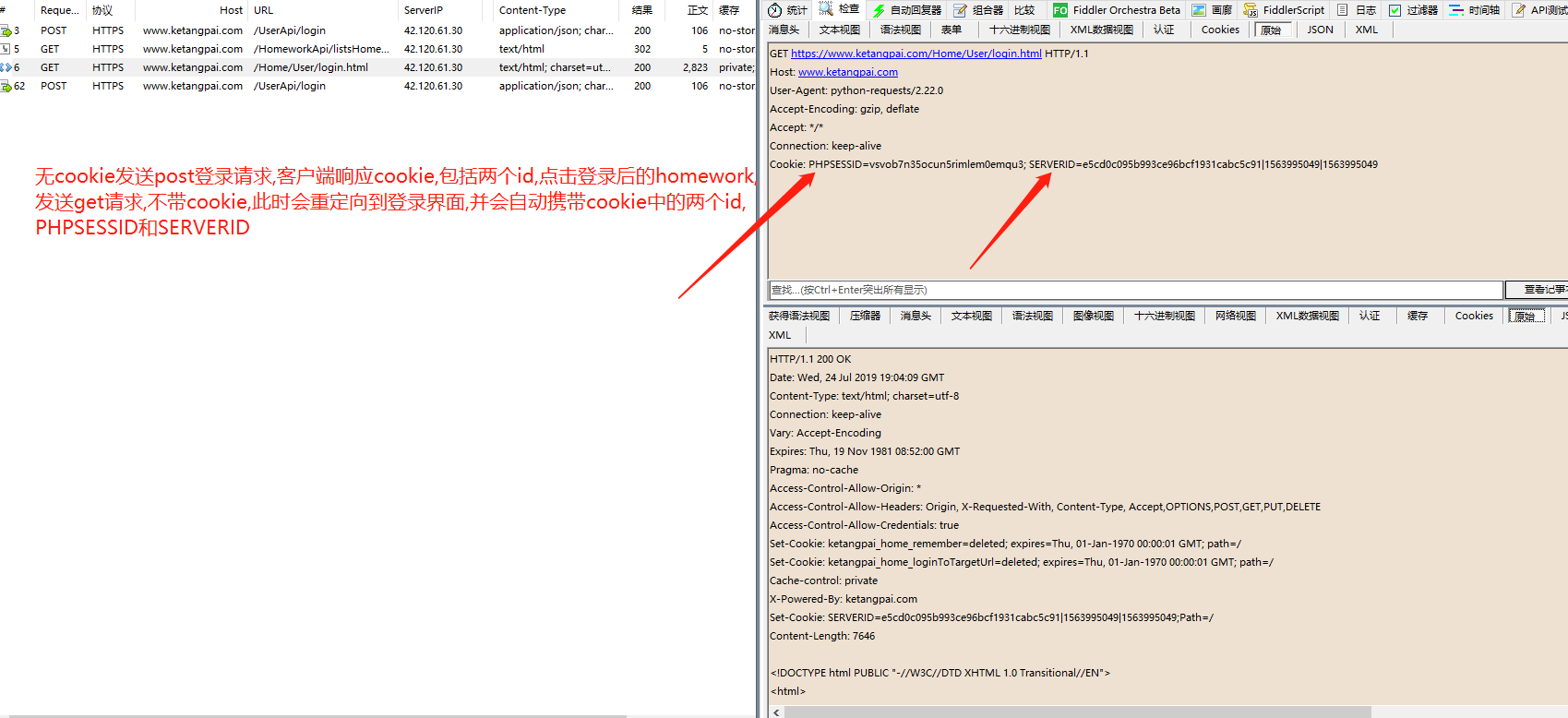

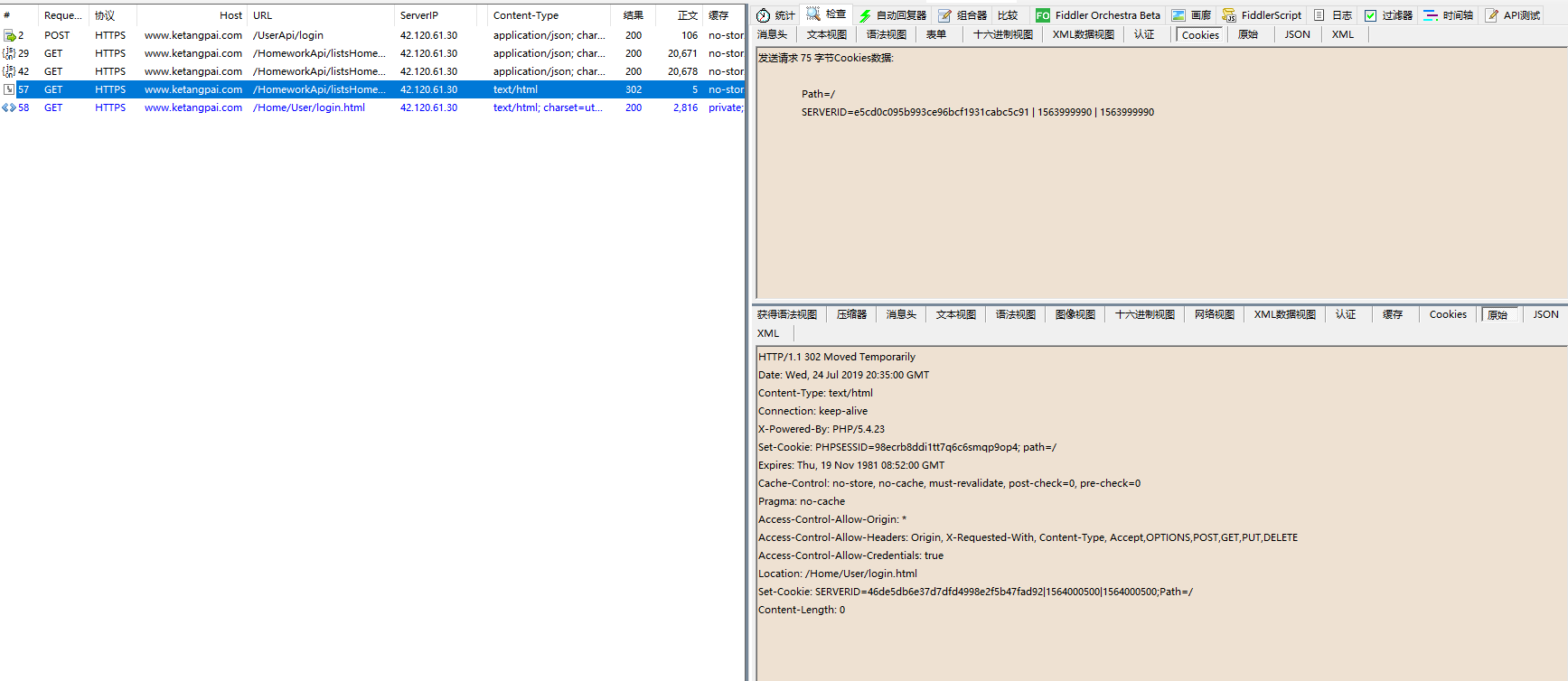

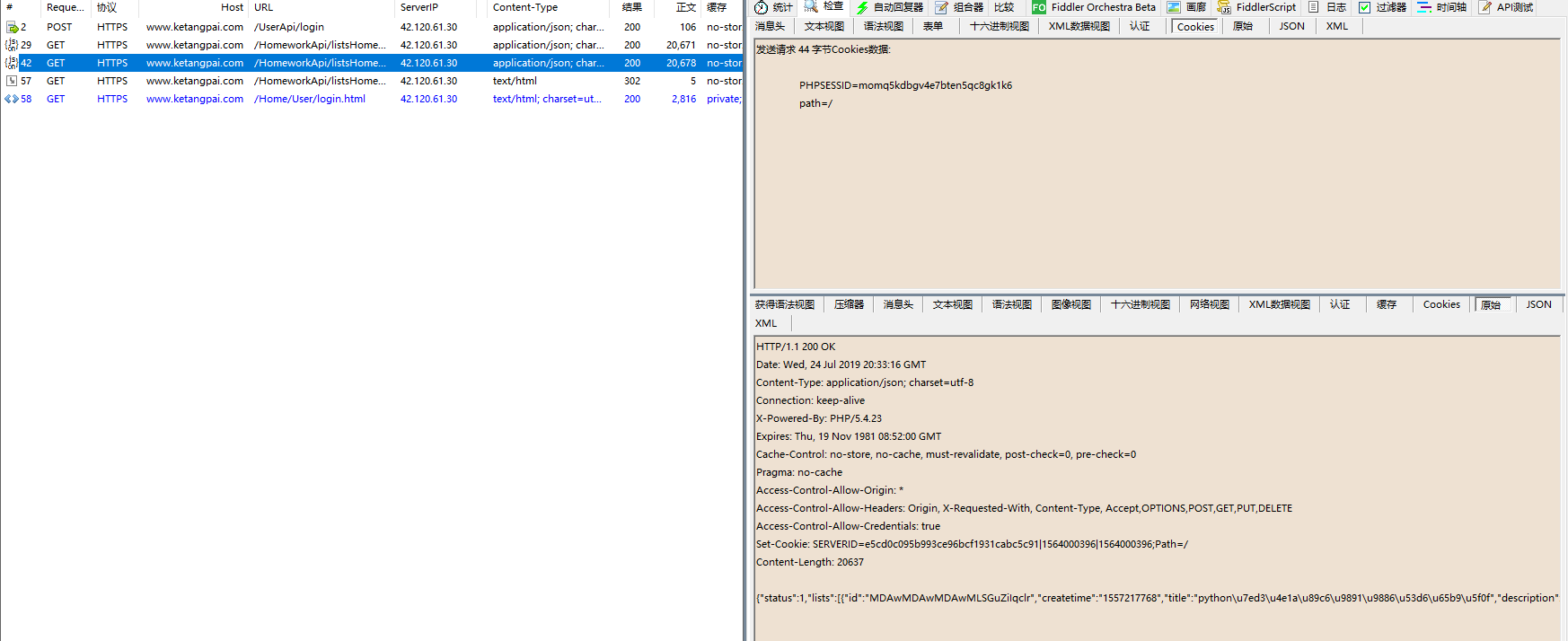
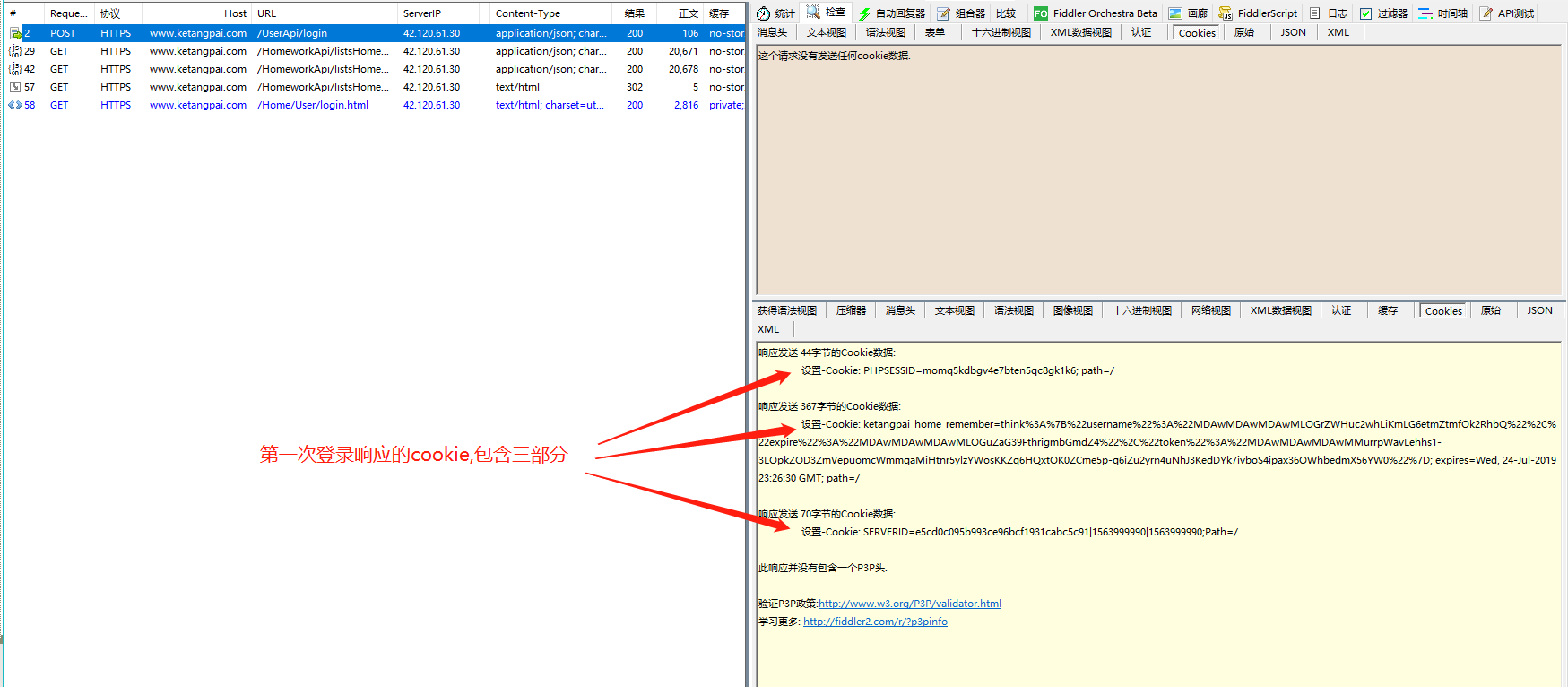
对于课堂派网站,登录后的页面操作只需要携带PHPSESSID或者cookie中间那部分即可,两个都带也可,SERVERID不知道是干啥的,每次响应的都会变.
代码实现:
cookie = None
class HttpRequest:
def __init__(self,method,url,data=None):
self.method=method
self.url=url
self.data=data
# def http_get(self):
# res=requests.get(self.url,params=self.data)
# print(res)
# print(res.text)
# def http_post(self):
# res = requests.post(self.url, data=self.data)
# print(res)
# print(res.text)
def send_request(self):
global cookie
if self.method=='get':
coo={'ketangpai_home_remember':'think%3A%7B%22username%22%3A%22MDAwMDAwMDAwMLOGrZWHuc2whLiKmLG6etmZtmfOk2RhbQ%22%2C%22expire%22%3A%22MDAwMDAwMDAwMLOGuZaG39FthrigmbGmdZ4%22%2C%22token%22%3A%22MDAwMDAwMDAwMMurrpWavLehhs1-3LOpkZOD3ZmVepuomcWmmqaMiHtnr5ylzYWosKKZq6HQxtOK0ZCme5p-q6iZu2yrn4uNhJ3KedDYk7ivboS4ipax36OWhbedmX56YW0%22%7D', 'expires':'Wed, 24-Jul-2019 23:26:30 GMT','path':'/'}
res=requests.get(self.url, params=self.data,verify=False,cookies=coo)
cookie = res.cookies # 更新cookie
else:
res=requests.post(self.url, data=self.data,verify=False,cookies=cookie)
cookie = res.cookies
return res if __name__ == '__main__': url='https://www.ketangpai.com/UserApi/login'
data={'email':'1255811581@qq.com','password':'huahua90!@'}
# h=HttpRequest('post',url,data)
# res = h.send_request()
# print(res)
# print(res.cookies) # print(res.cookies.items())
# print(type(res.cookies.items()))
# cookie_str=''
# cookie_dict = {}
# cookie_list = []
# for key, value in res.cookies.items():
# cookie_str += key + '=' + value + ';'
# cookie_dict[key]=value
# cookie_list.append(key+'='+value)
# print(cookie_str)
# print(cookie_dict)
# print(cookie_list) h=HttpRequest('get','https://www.ketangpai.com/HomeworkApi/listsHomework?courseid=MDAwMDAwMDAwMLOcqZWH37Np')
res2 = h.send_request()
print('访问作业接口的结果是:',res2)
print(res2.cookies)
print(res2.text) print(res2.json())
关于网站登录后的页面操作所携带的不同cookie值的更多相关文章
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- Vuex 页面刷新后store保存的数据会丢失 取cookie值
在store.js中 export default new vuex.Store({ // 首先声明一个状态 state state:{ pcid: '', postList: [], } //更新状 ...
- laravel登录后其他页面拿不到登录信息
登录本来是用表单的,我自作聪明的使用ajax提交 public function login(Request $request){ $data = $request->input(); $dat ...
- 网站登录后会话无法保存。php环境
在php 页面中phpinfo() 看下session 是否存在.session 的path 是否设置.具体的还要自己检查. 1.php.ini中的output_buffering=off 改成out ...
- 关于WordPress登录后跳转到指定页面
前面在写模版的时候,有朋友要求网站登录后要跳转的到指定的页面.这个从前还真没遇到过.于是就用万能的搜索(很少百度)找了下,方法基本上就是一个,代码如下: <?php // Fields f ...
- Spring Security入门(2-3)Spring Security 的运行原理 4 - 自定义登录方法和页面
参考链接,多谢作者: http://blog.csdn.net/lee353086/article/details/52586916 http元素下的form-login元素是用来定义表单登录信息的. ...
- 一个网站同一域名不同目录下的文件访问到的cookie值不同是什么原因?
一个网站(e:\test):里面包含多个目录如: html css js php img ..... 等等.然后,我在js目录里面的js文件中设置了cookie:同样也在php目录中的php文件中设置 ...
- Python手动构造Cookie模拟登录后获取网站页面内容
最近有个好友让我帮忙爬取个小说,这个小说是前三十章直接可读,后面章节需要充值VIP可见.所以就需要利用VIP账户登录后,构造Cookie,再用Python的获取每章节的url,得到内容后再使用 PyQ ...
随机推荐
- vc6.0 绿色版 下载地址
最新版的vs2019已经完全不支持生成运行在xp下的应用程序 每次在xp下测试,都需要配置好vc6.0,但乱七八糟的太多了,给出地址,绿色版可用 http://www.downcc.com/soft/ ...
- 爬虫(二):抓包工具Fiddler
1. 抓包工具Fiddler 1.1 Fiddler下载与安装 最简单的方法,打开百度,搜索fiddler下载. 下载完毕解压即可,此版本为绿色版. 点击这个即可运行抓包软件. 1.2 Fiddler ...
- python网络编程:UDP方式传输数据
UDP --- 用户数据报协议(User Datagram Protocol),是一个无连接的简单的面向数据报的运输层协议. UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能 ...
- Linux系统学习 十九、VSFTP服务—虚拟用户访问—为每个虚拟用户建立自己的配置文件,单独定义权限
为每个虚拟用户建立自己的配置文件,单独定义权限 可以给每个虚拟用户单独建立目录,并建立自己的配置文件.这样方便单独配置权限,并可以单独指定上传目录 1.修改配置文件 vi /etc/vsftpd/vs ...
- Win10锁屏壁纸位置
C:\Users\MIS\AppData\Local\Packages\Microsoft.Windows.ContentDeliveryManager_cw5n1h2txyewy\LocalStat ...
- mysql实践:sql优化
---恢复内容开始--- 设计表的时候 1. 不同的表涉及同一个公共意义字段不要使用不同的数据类型(可能导致索引不可用,查询结果有偏差) 2. 不要一张表放太多的数据 主表20~30个字段 ...
- 谷歌chrome浏览器被毒霸上网导航www.uu114.cn劫持 chrome://version命令行被篡改
问题描述 win10系统更新, 谷歌chrome浏览器打开后自动跳转到被劫持的网站.我的被hao123劫持, 瞬间对hao123的好感度下降浏览器输入chrome://version 可以看到“命令行 ...
- 批量修改含空格的文件名「Linux」
1.问题:文件批量重命名和处理文件名中的空格 如果文件名中有空格,在执行以下shell脚本的时候会出错. shell 脚本 for filename in `ls` do echo $filename ...
- python访问Apollo获取配置
操作系统 : CentOS7.3.1611_x64 Python 版本 : 3.6.8 Apollo源码地址: https://github.com/ctripcorp/apollo 访问Apollo ...
- ubuntu上编译和使用easy_profiler对C++程序进行性能分析
本文首发于个人博客https://kezunlin.me/post/91b7cf13/,欢迎阅读最新内容! tutorial to compile and use esay profiler with ...