Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上)
- 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cookie和session机制
Python爬虫爬取登录后的页面
所以怎样让爬虫使用验证用户身份信息的cookie呢,换句话说,怎样在使用爬虫的时候爬取已经登录的页面呢,这就是本篇的重点
cookie和session介绍
- cookie是发给用户的(即http浏览器)的一段信息
- session是保存在服务器上的对应的另一半信息,用来记录记录用户信息
- cookie和session区别和联系:
- 1.存放位置不同:cookie保存在本地,session保存在服务器
- 2.cookie不安全
- 为什么不安全,因为cookie是保存在本地的,也就是说用户可以就本地找到后进行修改
- 所以一般用来存放用户身份信息,常用来识别用户身份,比如用户名+登录密码(站点也就不怕被修改了)
- 当我们关闭浏览器后,再次打开一些网站,不用再次登录,也正是因为使用了保存在本地浏览器的cookie
- 3.session会保存在服务器上有过期时间,cookie也有
- 4.单个cookie保存数据不超过4k,部分浏览器会限制一个站点最多保存20个
- 5.session保存在服务器
- 一般情况下,session是放在内存中或者数据库中
使用cookie登录的网站
例如人人网:
第一步:Chrome打开登录
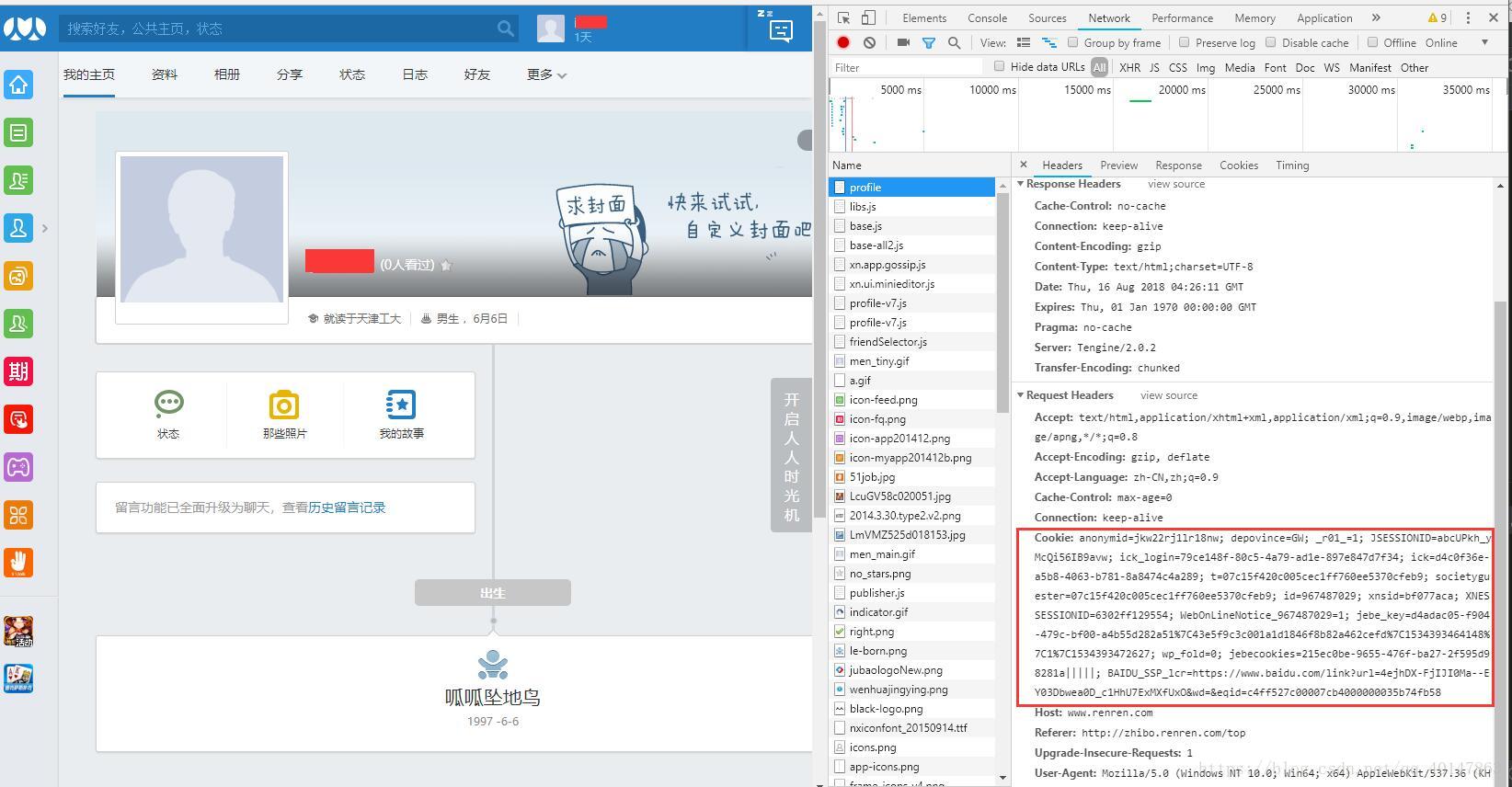
第二步:拷贝Chrome登录后的地址,使用火狐浏览器打开
这可以看到报错302
原因就是火狐浏览器的cookie和Chrome保存的cookie不一样,站点判断用户身份改变,所以不允许登录,另一方面,也就说明我们使用 cookie 验证身份是成功的
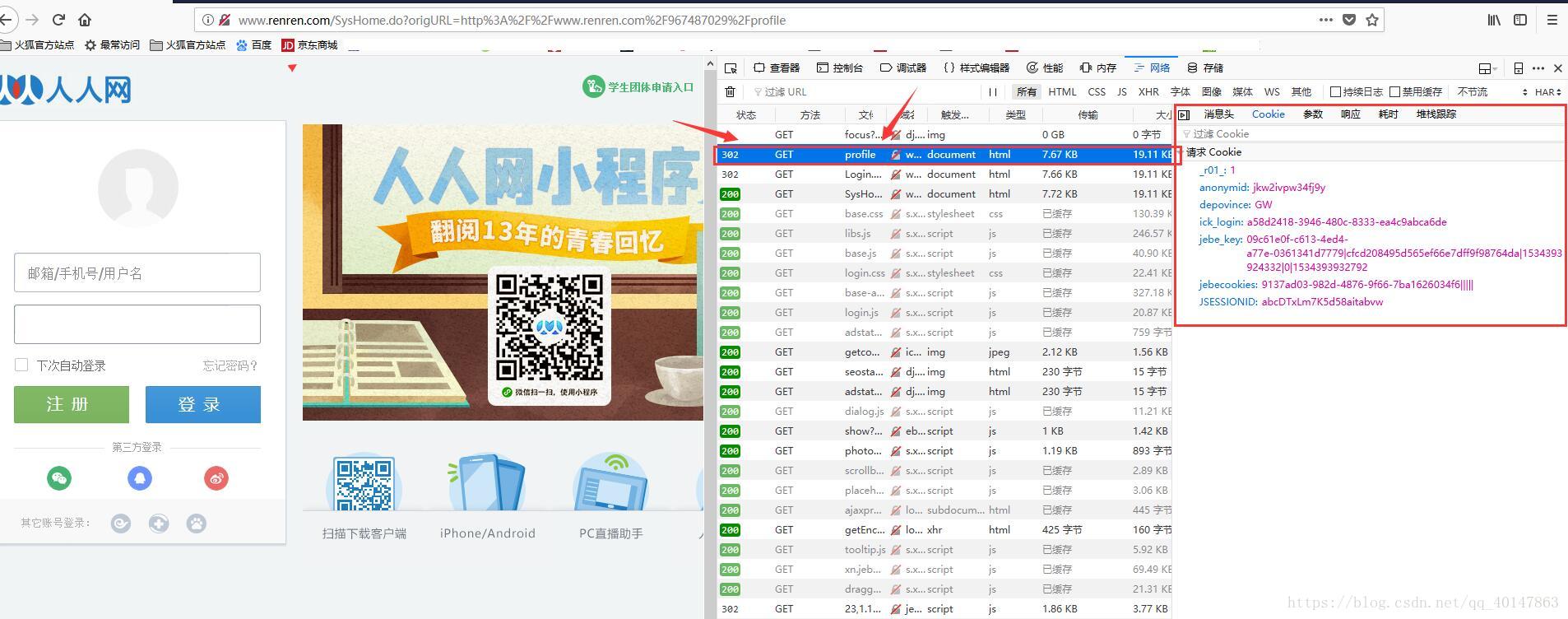
主角登场-爬虫使用cookie
既然其他浏览器不能直接访问网站,我们的爬虫就更不能了,所以怎样让爬虫使用验证用户身份信息的cookie呢?马上揭晓:
编写爬虫代码
- 案例v12cookie2文件:https://xpwi.github.io/py/py爬虫/py12cookie2.py
- 想要未使用cookie的对照案例,可以直接下载:
案例v12cookie1文件:https://xpwi.github.io/py/py爬虫/py12cookie1.py
# 爬虫使用cookie
from urllib import request
if __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
headers = {
# Cookie值从登录后的浏览器,拷贝,方法文章上面有介绍
"Cookie": "anonymid=jkw22rj1lr18nw; depovince=GW; _r01_=1; JSESSIONID=abcUPkh_yMcQi56IB9avw; ick_login=79ce148f-80c5-4a79-ad1e-897e847d7f34; ick=d4c0f36e-a5b8-4063-b781-8a8474c4a289; t=07c15f420c005cec1ff760ee5370cfeb9; societyguester=07c15f420c005cec1ff760ee5370cfeb9; id=967487029; xnsid=bf077aca; XNESSESSIONID=6302ff129554; BAIDU_SSP_lcr=https://www.baidu.com/link?url=4ejhDX-FjIJI0Ma--EY03Dbwea0D_c1HhU7ExMXfUxO&wd=&eqid=c4ff527c00007cb4000000035b74fb58; wp_fold=0; jebe_key=d4adac05-f904-479c-bf00-a4b55d282a51%7C43e5f9c3c001a1d1846f8b82a462cefd%7C1534398658919%7C1; jebecookies=6031f512-d289-4dff-b1d6-aaa7849bd1ff|||||"
}
req = request.Request(url=url,headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
with open("rsp.html","w",encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
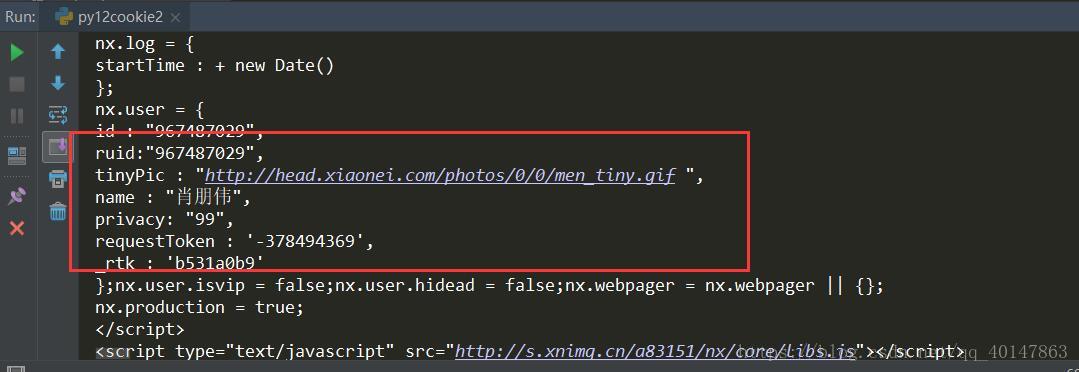
运行结果
现在我们可以在返回的html页面看到自己的登录信息了,也就说明cookie使用成功了
今天介绍的是手动拷贝cookie,后面会介绍如何自动的使用!
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)的更多相关文章
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
随机推荐
- JAVA数据结构--二叉查找树
二叉查找树定义 二叉查找树(英语:Binary Search Tree),也称二叉搜索树.有序二叉树(英语:ordered binary tree),排序二叉树(英语:sorted binary tr ...
- 2.阿里实人认证 .net 准备工作2 转换demo
1.引入阿里的SDK 2. 搬一下java 的代码 DefaultProfile profile = DefaultProfile.GetProfile( "cn-hangzhou" ...
- android 仿网易新闻首页框架
实现思路很简单左侧栏目是一个一个的 Fragment 的,点击时动态替换各个 Fragment 到当前 Activity 中. 关键代码: public void loadFragment(Ma ...
- loadView 与 viewDidLoad 和 didReceiveMemoryWarning与viewDidUnload 详解
首先试验下:viewController初始化 分两个支路:initWithNibName加载初始化 及 init 直接初始化: <1>调用initWithNibName加载一个xib界面 ...
- [LNMP]——LNMP环境配置
LNMP=Linux+Nginx+Mysql+PHP Install Nginx //安装依赖包 # yum install openssl openssl-devel zlib-devel //安装 ...
- 使用YUM安装MySQL 5.5(适用于CentOS6.2/5.8及Fedora 17/16平台)
目前CentOS/Red Hat (RHEL) 6.2官方自带的mysql版本为5.1,mysql5.5已经出来了. 相比mysql5.1,mysql5.5不仅在多个方面进行了改进: 性能上有了很大提 ...
- solr不是标准的java project解决方案
官方默认提供的源码包并不是一个标准的Eclipse Java - Project,需要使用ivy进行构建,通过ivy的构建可以将下载下来的源码包转换成一个标准的java Project,然后我们就能把 ...
- JSON跨域问题总结
一.跨域问题的原因: 1 浏览器的检查 2 跨域 3 XMLHttpRequest请求二.跨域问题的解决: 1 禁止浏览器检查:使用dos命令,在启动浏览器的时候,加一个参数:chrome --dis ...
- T-SQL语句创建表
USE E_Market --指定当前所操作的数据库 GO CREATE TABLE 表名 ( BID int identity (1,1)NOT NULL, BNAME varch ...
- 在 Azure WebApps 中运行64位 Asp.net Core 应用
作为微软下一代的开源的跨平台的开发框架, Asp.net core 正在吸引越来越多的开发者基于其构建现代 web 应用. 目前, Azure App Service 也实现了对 asp.net co ...