偏置方差分解Bias-variance Decomposition
http://blog.csdn.net/pipisorry/article/details/50638749
偏置-方差分解(Bias-Variance Decomposition)
偏置-方差分解(Bias-Variance Decomposition)是统计学派看待模型复杂度的观点。Bias-variance 分解是机器学习中一种重要的分析技术。给定学习目标和训练集规模,它可以把一种学习算法的期望误差分解为三个非负项的和,即本真噪音noise、bias和 variance。
noise 本真噪音是任何学习算法在该学习目标上的期望误差的下界;( 任何方法都克服不了的误差)
bias 度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(独立于训练样本的误差,刻画了匹配的准确性和质量:一个高的偏置意味着一个坏的匹配)
variance 则度量了在面对同样规模的不同训练集时,学习算法的估计结果发生变动的程度。(相关于观测样本的误差,刻画了一个学习算法的精确性和特定性:一个高的方差意味着一个弱的匹配)
偏差度量了学习算法期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度……泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。-周志华《机器学习》

假设我们有K个数据集,每个数据集都是从一个分布p(t,x)中独立的抽取出来的(t代表要预测的变量,x代表特征变量)。对于每个数据集D,我们都可以在其基础上根据学习算法来训练出一个模型y(x;D)来。在不同的数据集上进行训练可以得到不同的模型。学习算法的性能是根据在这K个数据集上训练得到的K个模型的平均性能来衡量的,亦即:

其中的h(x)代表生成数据的真实函数,亦即t=h(x)。
我们可以看到,给定学习算法在多个数据集上学到的模型的和真实函数h(x)之间的误差,是由偏置(Bias)和方差(Variance)两部分构成的。
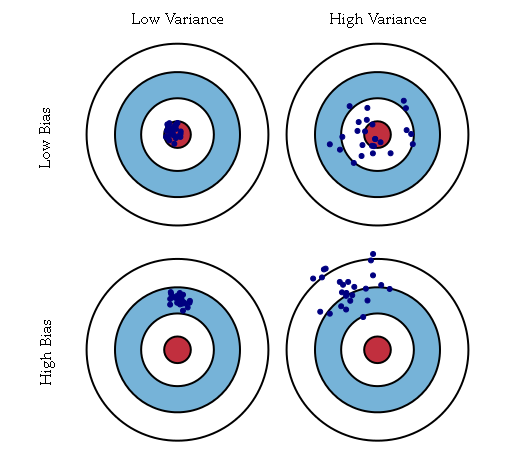
其中偏置描述的是学到的多个模型和真实的函数之间的平均误差,而方差描述的是学到的某个模型和多个模型的平均之间的平均误差(PRML上的原话是variance measures the extent to which the solutions for individual data sets vary around their average)。偏置刻画的是构建的模型和真实模型之间的差异。例如数据集所反映的真实模型为二次模型,但是构建的是线性模型,则该模型的结果总是和真实值结果直接存在差异,这种差异是有构建的模型的不准确所导致的,即为偏置bias;如上图中的下面两个图,真实的模型是红心(即每次都是要瞄准红心的),但是构建的模型是偏离红心的(即在射击时瞄准的是红心偏上方向)。方差刻画的是构建的模型自身的稳定性。例如数据集本身是二次模型,但是构建的是三次模型,对于多个不同的训练集,可以得到多个不同的三次模型,那么对于一个固定的测试点,这多个不同的三次模型得到多个估计值,这些估计值之间的差异即为模型的方差;如上图中的右侧两图,不论构建的模型是否是瞄准红心,每个模型的多次结果之间存在较大的差异。
偏置和方差之间的权衡
所以在进行学习时,就会存在偏置和方差之间的平衡。灵活的模型(次数比较高的多项式)会有比较低的偏置和比较高的方差,而比较严格的模型(比如一次线性回归)就会得到比较高的偏置和比较低的方差。下图形象的说明了以上两种情况:
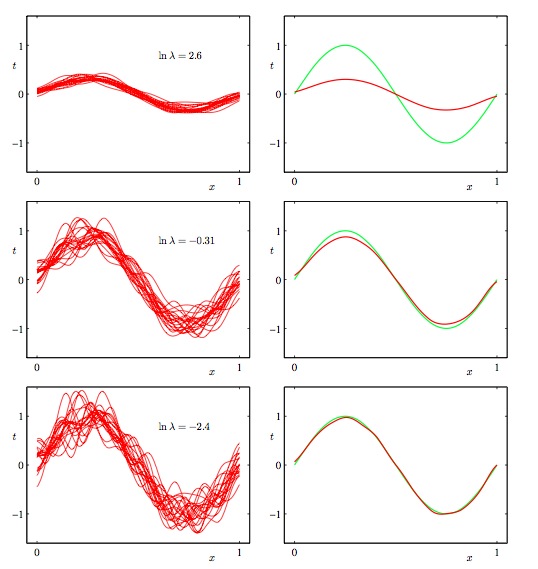
用于训练的是100个数据集,每个数据集包含25个由h(x)=sin(2πx)[右图中的绿线]随机生成的点的。 参数λ控制模型的灵活性(复杂度),λ越大,模型越简单(严格),反之越复杂(灵活)。我们生成多个模型(左图中的红线),并区多个模型的平均值(右图中的红线)。我们可以看到,当λ较大时(最上面的两个图),平均模型比较简单(最上面的右图),不能很好的拟合真实函数h(x),亦即偏差较大,但是多个模型之间比较相似,差距不大,方差较小(最上面的左图)。当λ较小时(最下面的两个图),平均模型能够非常好的拟合真实函数h(x),亦即偏差较小(最下面的右图),但是多个模型之间差距很大,方差比较大(最下面的左图)。
使用Bagging方法可以有效地降低方差。Bagging是一种再抽样方法(resampling),对训练数据进行有放回的抽样K次,生成K份新的训练数据,在这K个新的训练数据上训练得到K个模型,然后使用K个模型的平均来作为新的模型。随机森林(Random
Forest)是一种基于Bagging的强大的算法。
造成偏置和方差的原因除了学习方法的不同和参数的不同(比如λ)之外,数据集本身也会对其造成影响。如果训练数据集和新数据集的分布是不同的,会增大偏置。如果训练数据集过少,会增大方差。
偏置-方差分解是统计学派解释模型复杂度的观点,但是其实用价值不大(Bagging也许是一个例外吧~),因为偏置-方差分解是基于多个数据集的,而实际中只会有一个训练数据集,将这个数据集作为一个整体进行训练会比将其划分成多个固定大小的数据集进行训练再取平均的效果要好。




Bias-variance decomposition推导

Note:ED是对所有数据集D求期望,而不是对x或者y。


[word文档下载]
from:http://blog.csdn.net/pipisorry/article/details/50638749
ref:Bishop. PRML(Pattern Recognization and Machine Learning). p11-16
Understanding the Bias-Variance Decomposition.
偏置方差分解Bias-variance Decomposition
偏置-方差分解(Bias-Variance Decomposition)*
Andrew NG. CS229 Lecture Note1: Supervised Learning, Discrimitive Algorithms
偏置方差分解Bias-variance Decomposition的更多相关文章
- 偏置-方差分解(Bias-Variance Decomposition)
本文地址为:http://www.cnblogs.com/kemaswill/,作者联系方式为kemaswill@163.com,转载请注明出处. 机器学习的目标是学得一个泛化能力比较好的模型.所谓泛 ...
- 【笔记】偏差方差权衡 Bias Variance Trade off
偏差方差权衡 Bias Variance Trade off 什么叫偏差,什么叫方差 根据下图来说 偏差可以看作为左下角的图片,意思就是目标为红点,但是没有一个命中,所有的点都偏离了 方差可以看作为右 ...
- 训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合
1. 训练.验证.测试集 对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分: 训练集(train set):用训练集对算法或模型进行训练过程: 验证集(d ...
- 偏差和方差以及偏差方差权衡(Bias Variance Trade off)
当我们在机器学习领域进行模型训练时,出现的误差是如何分类的? 我们首先来看一下,什么叫偏差(Bias),什么叫方差(Variance): 这是一张常见的靶心图 可以看左下角的这一张图,如果我们的目标是 ...
- Error=Bias+Variance
首先 Error = Bias + Variance Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输 ...
- 机器学习总结-bias–variance tradeoff
bias–variance tradeoff 通过机器学习,我们可以从历史数据学到一个\(f\),使得对新的数据\(x\),可以利用学到的\(f\)得到输出值\(f(x)\).设我们不知道的真实的\( ...
- 矩阵分解(rank decomposition)文章代码汇总
矩阵分解(rank decomposition)文章代码汇总 矩阵分解(rank decomposition) 本文收集了现有矩阵分解的几乎所有算法和应用,原文链接:https://sites.goo ...
- 2.9 Model Selection and the Bias–Variance Tradeoff
结论 模型复杂度↑Bias↓Variance↓ 例子 $y_i=f(x_i)+\epsilon_i,E(\epsilon_i)=0,Var(\epsilon_i)=\sigma^2$ 使用knn做预测 ...
- 机器学习:偏差方差权衡(Bias Variance Trade off)
一.什么是偏差和方差 偏差(Bias):结果偏离目标位置: 方差(Variance):数据的分布状态,数据分布越集中方差越低,越分散方差越高: 在机器学习中,实际要训练模型用来解决一个问题,问题本身可 ...
随机推荐
- Docker 基础 : Dockerfile
Dockerfile 是一个文本格式的配置文件,用户可以使用 Dockerfile 快速创建自定义的镜像.我们会先介绍 Dockerfile 的基本结构及其支持的众多指令,并具体讲解通过执行指令来编写 ...
- 【图文详解】linux下配置远程免密登录
linux下各种集群搭建往往需要配置远程免密登录,本文主要描述了CentOs6.3系统下配置免密登录的详细过程. ssh远程登录,两种身份验证: 用户名+密码 密钥验证 机器1生成密钥对并将公钥发给机 ...
- IOI2016Day2. paint
题目链接:http://uoj.ac/problem/238 题目大意: 有一个长度为n的黑白序列,告诉你所以k个极长连续黑段长度和顺序.有一些位置的颜色已知,需要判断剩下未知的位置哪些颜色 一定是白 ...
- 阿里架构师带你深入浅出jvm
本文跟大家聊聊JVM的内部结构,从组件中的多线程处理,JVM系统线程,局部变量数组等方面进行解析 JVM JVM = 类加载器(classloader) + 执行引擎(execution engine ...
- C++ 实现俄罗斯方块
C++ 实现俄罗斯方块 一.实验介绍 1.1 实验内容 本节实验我们进行设计俄罗斯方块前的思路分析,以及介绍ncurses 库的使用方法. 1.2 实验知识点 C++ 编程基础 ncurses 库的使 ...
- for循环&len函数和range函数的运用
函数:len() 作用:返回字符串.列表.字典.元组等长度 语法:len(str) 参数: str:要计算的字符串.列表.字典.元组等 返回值:字符串.列表.字典.元组等元素的长度 实例 1.计算字 ...
- JS实现2048代码
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- ACM Strange fuction
现在,这里有一个功能: F(x) = 6 * x^7+8*x^6+7*x^3+5*x^2-y*x (0 <= x <=100) 当x在0到100之间时,你能找到最小值吗? 输入 第一行包 ...
- 介绍Docker容器
容器是 Docker 又一核心概念. 简单的说,容器是独立运行的一个或一组应用,以及它们的运行态环境.对应的,虚拟机可以理解为模拟运行的一整套操作系统(提供了运行态环境和其他系统环境)和跑在上面的应用 ...
- 在查询语句中使用 NOLOCK 和 READPAST
对于非银行等严格要求事务的行业,搜索记录中出现或者不出现某条记录,都是在可容忍范围内,所以碰到死锁,应该首先考虑,我们业务逻辑是否能容忍出现或者不出现某些记录,而不是寻求对双方都加锁条件下如何解锁的问 ...