numpy+sklearn 手动实现逻辑回归【Python】
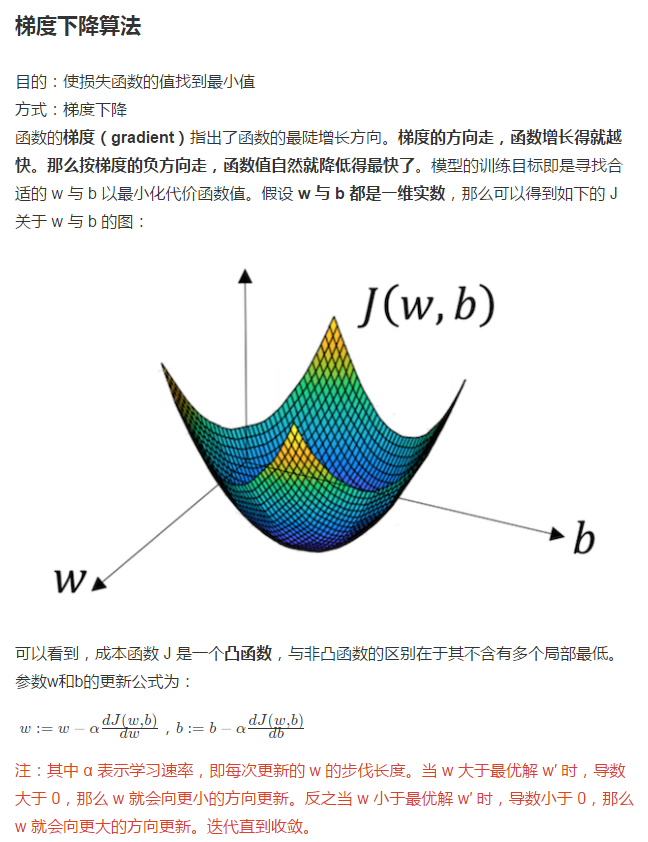
逻辑回归损失函数:
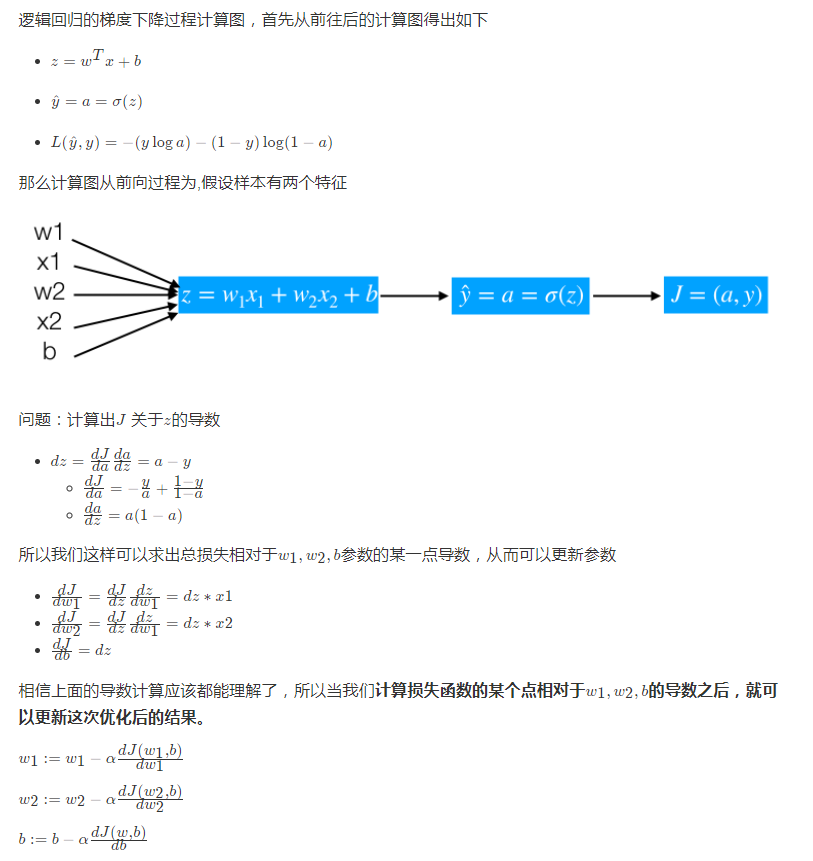
from sklearn.datasets import load_iris,make_classification
from sklearn.model_selection import train_test_split
import tensorflow as tf
import numpy as np X,Y = make_classification(n_samples=1000,n_features=5,n_classes=2)
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.3) def initialize_with_zeros(shape):
"""
创建一个形状为 (shape, 1) 的w参数和b=0.
return:w, b
"""
w = np.zeros((shape, 1))
b = 0
return w, b def basic_sigmoid(x):
"""
计算sigmoid函数
""" s = 1 / (1 + np.exp(-x)) return s def propagate(w, b, X, Y):
"""
参数:w,b,X,Y:网络参数和数据
Return:
损失cost、参数W的梯度dw、参数b的梯度db
"""
m = X.shape[1] # w (n,1), x (n, m)
A = basic_sigmoid(np.dot(w.T, X) + b)
# 计算损失
cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
dz = A - Y
dw = 1 / m * np.dot(X, dz.T)
db = 1 / m * np.sum(dz)
cost = np.squeeze(cost) # 从数组的形状中删除单维条目,即把shape中为1的维度去掉
grads = {"dw": dw,
"db": db} return grads, cost def optimize(w, b, X, Y, num_iterations, learning_rate):
"""
参数:
w:权重,b:偏置,X特征,Y目标值,num_iterations总迭代次数,learning_rate学习率
Returns:
params:更新后的参数字典
grads:梯度
costs:损失结果
""" costs = [] for i in range(num_iterations): # 梯度更新计算函数
grads, cost = propagate(w, b, X, Y) # 取出两个部分参数的梯度
dw = grads['dw']
db = grads['db'] # 按照梯度下降公式去计算
w = w - learning_rate * dw
b = b - learning_rate * db if i % 100 == 0:
costs.append(cost)
if i % 100 == 0:
print("损失结果 %i: %f" %(i, cost))
print(b) params = {"w": w,
"b": b} grads = {"dw": dw,
"db": db} return params, grads, costs def predict(w, b, X):
'''
利用训练好的参数预测
return:预测结果
''' m = X.shape[1]
y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1) # 计算结果
A = basic_sigmoid(np.dot(w.T, X) + b) for i in range(A.shape[1]): if A[0, i] <= 0.5:
y_prediction[0, i] = 0
else:
y_prediction[0, i] = 1 return y_prediction def model(x_train, y_train, x_test, y_test, num_iterations=2000, learning_rate=0.0001):
"""
""" # 修改数据形状
x_train = x_train.reshape(-1, x_train.shape[0])
x_test = x_test.reshape(-1, x_test.shape[0])
y_train = y_train.reshape(1, y_train.shape[0])
y_test = y_test.reshape(1, y_test.shape[0])
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape) # 1、初始化参数
w, b = initialize_with_zeros(x_train.shape[0]) # 2、梯度下降
# params:更新后的网络参数
# grads:最后一次梯度(下降损失)
# costs:每次更新的损失列表
params, grads, costs = optimize(w, b, x_train, y_train, num_iterations, learning_rate) # 获取训练的参数
# 预测结果
w = params['w']
b = params['b']
y_prediction_train = predict(w, b, x_train)
y_prediction_test = predict(w, b, x_test) # 打印准确率
print("训练集准确率: {} ".format(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
print("测试集准确率: {} ".format(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100)) return None if __name__ == '__main__':
model(x_train, y_train, x_test, y_test, num_iterations=500, learning_rate=0.01)
numpy+sklearn 手动实现逻辑回归【Python】的更多相关文章
- python sklearn库实现逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Red ...
- 机器学习作业(二)逻辑回归——Python(numpy)实现
题目太长啦!文档下载[传送门] 第1题 简述:实现逻辑回归. 此处使用了minimize函数代替Matlab的fminunc函数,参考了该博客[传送门]. import numpy as np imp ...
- 机器学习算法整理(二)梯度下降求解逻辑回归 python实现
逻辑回归(Logistic regression) 以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ 用梯度下降求解逻辑回归 Logi ...
- sklearn实现多分类逻辑回归
sklearn实现多分类逻辑回归 #二分类逻辑回归算法改造适用于多分类问题1.对于逻辑回归算法主要是用回归的算法解决分类的问题,它只能解决二分类的问题,不过经过一定的改造便可以进行多分类问题,主要的改 ...
- sklearn调用逻辑回归算法
1.逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决. 2.决策边界是指不同分类结果之间的边界 ...
- 【笔记】逻辑回归中使用多项式(sklearn)
在逻辑回归中使用多项式特征以及在sklearn中使用逻辑回归并添加多项式 在逻辑回归中使用多项式特征 在上面提到的直线划分中,很明显有个问题,当样本并没有很好地遵循直线划分(非线性分布)的时候,其预测 ...
- 逻辑回归代码demo
程序所用文件:https://files.cnblogs.com/files/henuliulei/%E5%9B%9E%E5%BD%92%E5%88%86%E7%B1%BB%E6%95%B0%E6%8 ...
- python——sklearn完整例子整理示范(有监督,逻辑回归范例)(原创)
sklearn使用方法,包括从制作数据集,拆分数据集,调用模型,保存加载模型,分析结果,可视化结果 1 import pandas as pd 2 import numpy as np 3 from ...
- 逻辑回归--美国挑战者号飞船事故_同盾分数与多头借贷Python建模实战
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
随机推荐
- iOS pch
Xcode6 之前会在 Supporting Files 文件夹下自动生成一个"工程名-PrefixHeader.pch"的预编译头文件,pch 头文件的内容能被项目中的其他所有源 ...
- Spring Boot熟稔于心的20个常识
1.什么是 Spring Boot? Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供 ...
- MATLAB实现一个EKF-2D-SLAM(已开源)
1. SLAM问题定义 同时定位与建图(SLAM)的本质是一个估计问题,它要求移动机器人利用传感器信息实时地对外界环境结构进行估计,并且估算出自己在这个环境中的位置,Smith 和Cheeseman在 ...
- C++中的字符串切片操作
string str = "hello"; str.substr(0,2); //输出"he", 表示[0,2)
- Redis 笔记(四)—— SET 常用命令
常用命令 命令 用例和描述 SADD SADD key item [item ...] —— 将一个或多个元素添加到集合中,返回添加的数量 SREM SREM key item [item ...] ...
- mysql服务器内存使用情况总结
活动链接(动态)使用的内存数量如下所示: per_connection_memory = read_buffer_size //memory for sequential table scans +r ...
- JavaScript中||和&&的运算
一般来讲 && 运算和 | | 运算得到的结果都是 true 和 false ,但是 js 中的有点不太一样.当进行 a&&b 和 a| |b (如 1&&am ...
- 微信小程序页面跳转的三种方式总结
原文链接 https://blog.csdn.net/zgmu/article/details/72123329 首先我们了解到,小程序规定页面路径只能有五层,所以我们尽量避免多层级的页面跳转 页面跳 ...
- es elasticsearch 6/7 设置内存方法
es节点的默认的heap内存大小是 1G 大小,在实际生产中,很容易导致内存溢出而导致进程被kill掉.所以我们一般会自己配置自己的,2.x的版本可以通过export ES_HEAP_SIZE=10g ...
- Java第二十天,Map集合(接口)
Map接口 一.定义 Map集合是双列集合,即一个元素包含两个值(一个key,一个value),Collection集合是单列集合. 定义格式: public interface Map<K,V ...