Pyspider的基本使用 -- 入门
简介
- 一个国人编写的强大的网络爬虫系统并带有强大的WebUI
- 采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
- 官方文档:http://docs.pyspider.org/en/latest/
安装
- pip install pyspider
- 安装失败的解决方法
启动服务
- 命令窗口输入pyspider
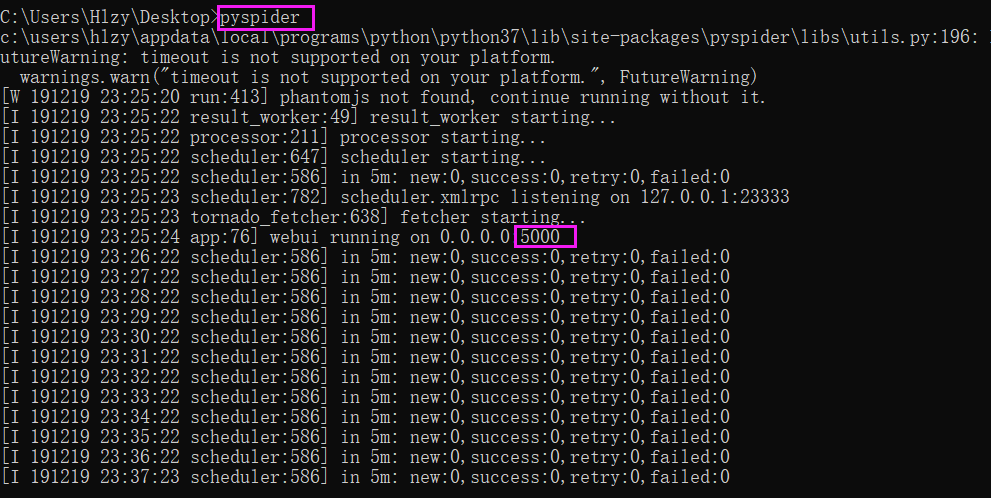
打开Web界面
- 浏览器输入localhost:5000

创建项目

删除项目
- 删除某个:设置 group 为 delete ,status 为 stop ,24小时之后自动删除

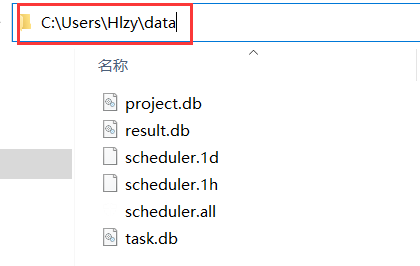
- 删除全部:在启动服务的路径下,找到它自己生成的data目录,直接删除目录里的所有文件
禁止证书验证

- 加上参数 validate_cert = False
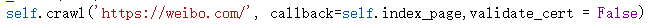
使用方法
- on_start(self)
- 入口方法,run的时候,默认会调用
- crawl()
- 生成一个新的爬取请求,类似于scrapy.Request,接受的参数是ur1和callback
- @every(minutes=2, seconds=30)
- 告诉scheduler两分30秒执行一次
- @config(age=10 * 24 * 60 * 60)
- 告诉调度器(单位:秒)、这个请求过期时间是10天、10天之内不会再次请求
- @config(priority=2)
- 优先级、数字越大越先执行
- age写在函数里面跟写在装饰器上的区别
- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒

- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒
执行任务
- 完成脚本编写,调试无误后,先save脚本,然后返回到控制台首页
- 直接点击项目状态status那栏,把状态由TODO改成DEBUG或RUNNING
- 最后点击项目最右边的Run按钮启动项目
对接phantomjs
- 将phantomjs.exe放在Python环境根目录下,或者将所在目录添加到系统的环境变量
- 添加成功,启动服务时,会显示如下信息
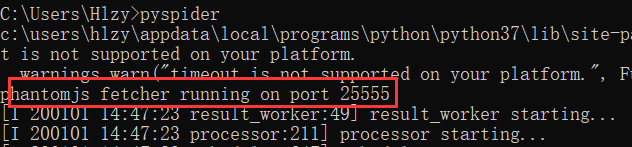
没使用js渲染
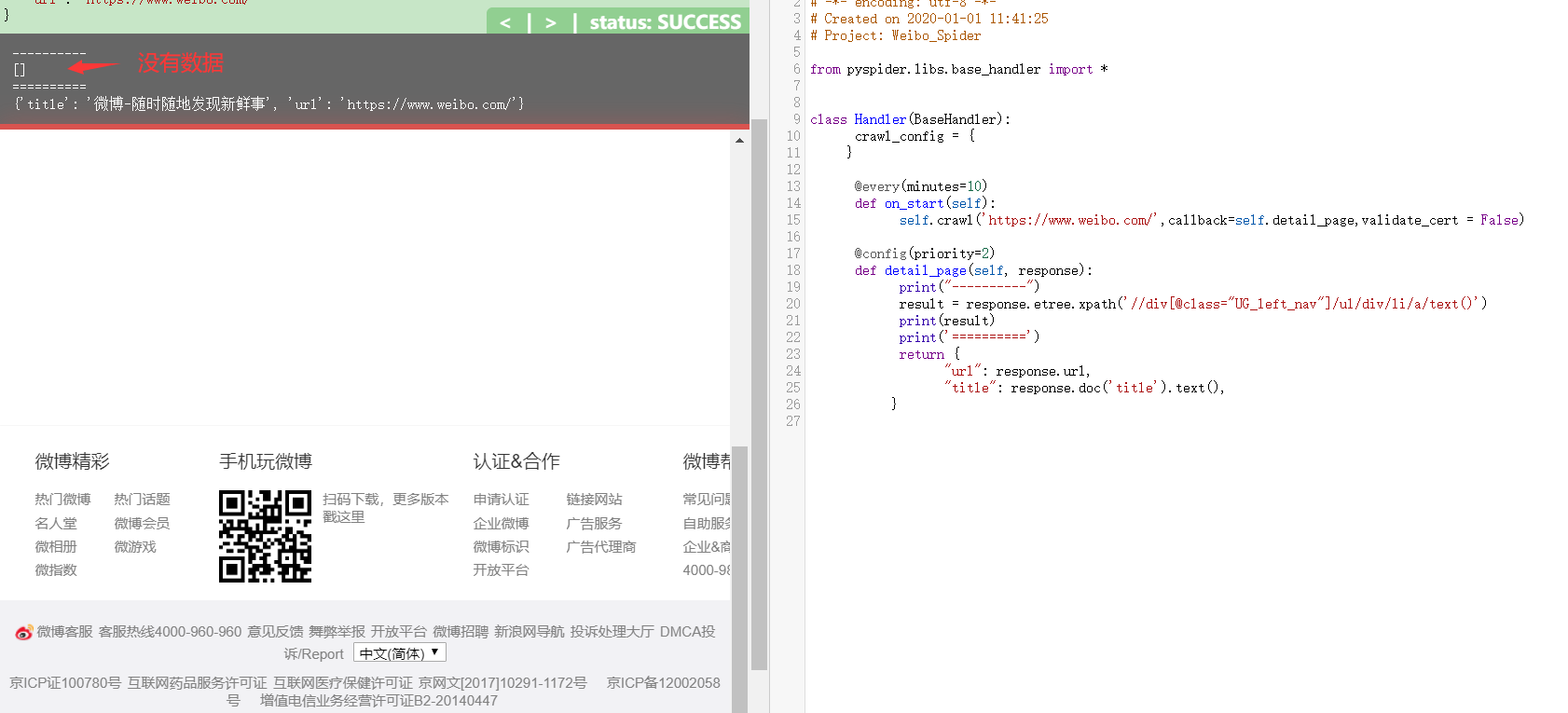
使用js渲染
- 添加参数 fetch_type = 'js'
其它
- rate/burst
- rate:一秒钟执行的请求个数
- burst:并发的数量
- 例如:2/5、每秒两个请求,并发数量为5,即每秒10个请求
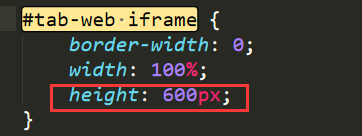
- 设置渲染的web页面的高度

- 在源代码里修改css样式即可(#tab-web iframe)
- css文件路径:python安装目录下 Lib\site-packages\pyspider\webui\static 里的 debug.min.css
Pyspider的基本使用 -- 入门的更多相关文章
- Python爬虫入门教程 27-100 微医挂号网专家团队数据抓取pyspider
1. 微医挂号网专家团队数据----写在前面 今天尝试使用一个新的爬虫库进行数据的爬取,这个库叫做pyspider,国人开发的,当然支持一下. github地址: https://github.com ...
- 爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下: 1.可以在Python环境下写脚本 2.具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看. 3.支持多 ...
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
- pyspider入门
1.http://www.pyspider.cn/jiaocheng/pyspider-webui-12.html 2.https://blog.csdn.net/weixin_37947156/ar ...
- 2、Pyspider使用入门
1.接上一篇,在webui页面,点击右侧[Create]按钮,创建爬虫任务 2.输入[Project Name],[Start Urls]为爬取的起始地址,可以先不输入,点击[Create]进入: 3 ...
- 爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前 首先我们要安装好pyspider,可以参考上一篇文章. 从一个web页面抓取信息的过程包括: 1.找到页面上包含的URL信息,这个url包含我们想要的信息 2.通过HTTP来获取页面内容 3 ...
- 【Hawk】入门教程(1)——从URL开始
入门教程(1)--从URL开始 首先感谢辛苦的沙漠君 先把沙漠君的教程载过来:)可以先看一遍 Hawk-数据抓取工具:简明教程 Hawk 数据抓取工具 使用说明(二) 20分钟无编程抓取大众点评17万 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- CSS水平垂直居中常见方法总结
1.元素水平居中 当然最好使的是: margin: 0 auto; 居中不好使的原因: 1.元素没有设置宽度,没有宽度怎么居中嘛! 2.设置了宽度依然不好使,你设置的是行内元素吧,行内元素和块元素的区 ...
- Robot Framework 使用【1】-- 基于Python3.7 + RIDE 最新版本搭建
前言 Robot Framework作为公司能快速落地实现UI自动化测试的一款框架,同时也非常适合刚入门自动化测试的朋友们去快速学习自动化,笔者计划通过从搭建逐步到完成自动化测试的过程来整体描述它的使 ...
- Hive的mysql安装配置
一.MySQL的安装 Hive的数据,是存在HDFS里的.此外,hive有哪些数据库,每个数据库有哪些表,这样的信息称之为hive的元数据信息. 元数据信息不存在HDFS,而是存在关系型数据库里,hi ...
- 如何为开发项目编写规范的README文件
前言 了解一个项目,首先都是通过其Readme文件了解信息.如果你以为Readme文件都是随便写写的那你就错了.github,oschina git gitcafe的代码托管平台上的项目的Readme ...
- Centos10卸载nginx
1.停止服务 /usr/local/nginx/sbin/nginx -s stop yum remove nginx 2.查看Nginx相关文件 whereis nginx 删除:rm -rf /u ...
- Go安装gRPC
grpc-go的官方安装命令 go get google.golang.org/grpc 无法正常使用. 我们可以用以下的命令替代,达到同样的效果 git clone https://github.c ...
- 对于使用javaweb技术制作简单管理系统的学习
近期在老师的引导下我们学习了利用Javaweb技术制作简单的管理系统,其中涉及到的技术很多,由于大多都是自学 对这些技术的理解还太浅显但能实现一些相关功能的雏形. (一).登录功能 在登陆功能中通过与 ...
- 「学习笔记」FFT 快速傅里叶变换
目录 「学习笔记」FFT 快速傅里叶变换 啥是 FFT 呀?它可以干什么? 必备芝士 点值表示 复数 傅立叶正变换 傅里叶逆变换 FFT 的代码实现 还会有的 NTT 和三模数 NTT... 「学习笔 ...
- Solr搜索引擎服务器学习笔记
Solr简介 采用Java5开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能 ...
- 编写自己的JDBC框架
目的 简化代码,提高开发效率 设计模式 策略设计模式 代码 #连接设置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost ...