入门大数据---ClouderaManager和CDH是什么?
1.CDH概述
CDH(Cloudra's Distribution Apache Of Hadoop)是Apache Hadoop和相关项目的最完整,经过测试和最流行的发行版。CDH提供Hadoop的核心要素–可扩展的存储和分布式计算–以及基于Web的用户界面和重要的企业功能。CDH是Apache许可的开源软件,并且是唯一提供统一批处理,交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。 一句话概括CDH就是集成多种技术的一个框架。
CDH提供
- 灵活性-存储任何类型的数据并使用各种不同的计算框架进行处理,包括批处理,交互式SQL,自由文本搜索,机器学习和统计计算。
- 集成-在可与广泛的硬件和软件解决方案一起使用的完整Hadoop平台上快速启动并运行。
- 安全性-处理和控制敏感数据。
- 可扩展性-启用广泛的应用程序并进行扩展,并扩展它们以满足您的要求。
- 高可用性-自信地执行关键任务业务任务。
- 兼容性-利用您现有的IT基础架构和投资。
Hadoop生态构成
- HDFS:分布式文件系统
- ZKFC:为实现NameNode高可用,在NameNode和Zookeeper之间传递信息,选举主节点工具。
- NameNode:存储文件元数据
- DateNode:存储具体数据
- JournalNode:同步主NameNode节点数据到从节点NameNode
- MapReduce:开源的分布式批处理计算框架
- Spark:分布式基于内存的批处理框架
- Zookeeper:分布式协调管理
- Yarn:调度资源管理器
- HBase:基于HDFS的NoSql列式数据库
- Hive:将SQL转换为MapReduce进行计算
- Hue:是CDH的一个UI框架
- Impala:是Cloudra公司开发的一个查询系统,类似于Hive,可以通过SQL执行任务,但是它不基于MapReduce算法,而是直接执行分布式计算,这样就提高了效率。
- oozie:是一个工作流调度引擎,负责将多个任务组合在一起按序执行。
- kudu:Apache Kudu是转为hadoop平台开发的列式存储管理器。和impala结合使用,可以进行增删改查。
- Sqoop:将hadoop和关系型数据库互相转移的工具。
- Flume:采集日志
- 还有一些其它的
CDH结构图
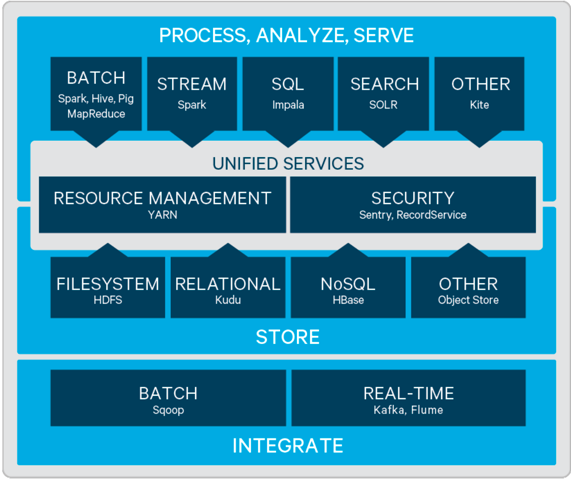
2.Cloudra Manager概述
Cloudra Manager简称CM,它是一个web操作平台,可以借助安装CDH然后安装多种Hadoop框架。
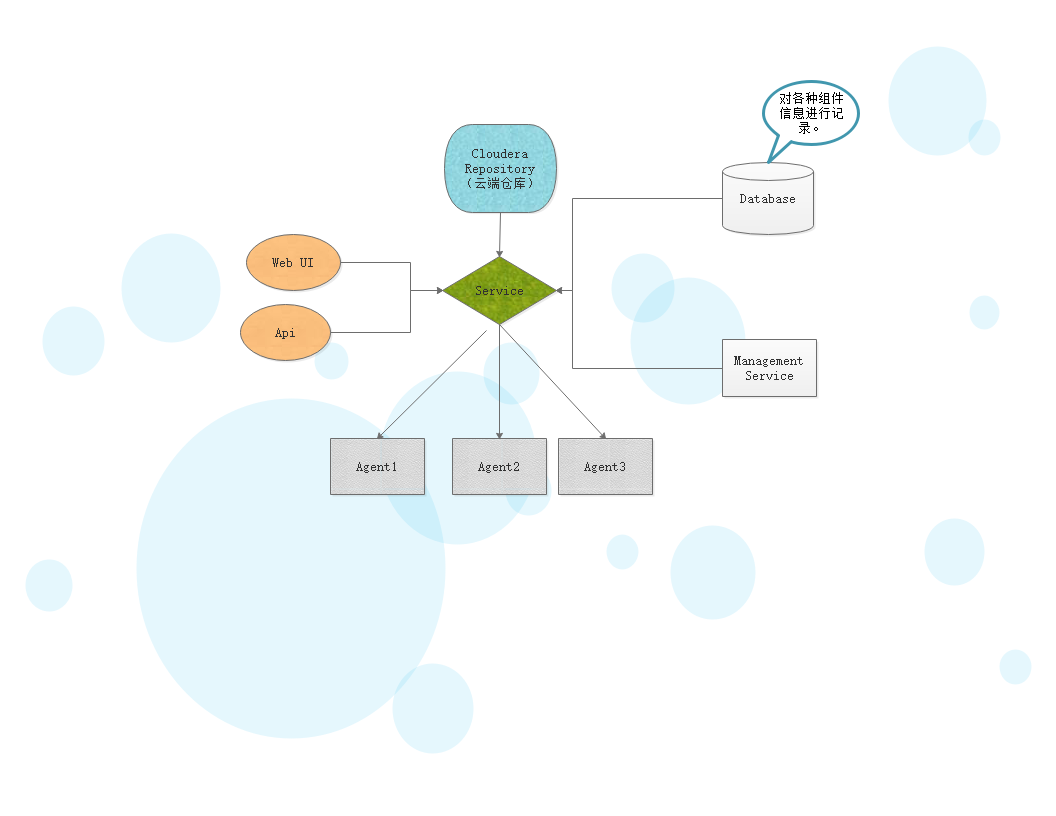
CloudraManager技术构成
Clients:客户端,通过web页面和ClouderaManager和服务器进行交互。
API:通过API和ClouderaManagement和服务器进行交互
Cloudera Repository:存储分发安装包
Management Server:进行监控和预警
Database:存储预警信息和配置信息。
Agent:分布在多台服务器,负责配置,启动和停止进程。监控主机。
结构图如下:
入门大数据---ClouderaManager和CDH是什么?的更多相关文章
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
随机推荐
- Ratel源码-C/S事件梳理
一.Ratel介绍 Ratel 是一个可以在命令行中玩斗地主的项目,可以使用小巧的jar包在拥有JVM环境的终端中进行游戏,同时支持人人对战和人机对战两种模式,丰富你的空闲时间! 二.玩法Demo 三 ...
- Rocket - diplomacy - wirePrefix
https://mp.weixin.qq.com/s/DVcA2UixnB_6vgI3SjZGyQ 调试wirePrefix方法. 1. 实现 wirePrefix用于调整名称格式,其实现 ...
- Chisel3 - Tutorial - FullAdder
https://mp.weixin.qq.com/s/Aye-SrUUuIP6_o67Rlt5OQ 全加器 逻辑图如下: 参考链接: https://github.com/ucb-b ...
- Java实现派(Pie, NWERC 2006, LA 3635)
题目 有F+1个人来分N个圆形派,每个人得到的必须是一整块派,而不是几块拼在一起,且面积要相同.求每个人最多能得到多大面积的派(不必是圆形). 输入的第一行为数据组数T.每组数据的第一行为两个整数N和 ...
- Java实现 LeetCode 275 H指数 II
275. H指数 II 给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列.编写一个方法,计算出研究者的 h 指数. h 指数的定义: "h 代表"高 ...
- 纯正中文版本pi-star系统下载
基于3.4.17修改(稳定,发热量少) 不支持RPI 4 a/b+ 完美支持树莓派0,1,2,3 默认刷好卡,启动已经设置好所有参数(选好TFT屏幕,调制解调器类型GPIO,打开了DMR服务器(460 ...
- Java线程池简聊
在Java中,已经实现了4中内置的线程池,这四种我不多聊. 大家各种网站论坛都能查得到. 现在说一下这四种线程池的基类: ThreadPoolExecutor在ThreadPoolExecutor中你 ...
- Python惯用法
目录 1. 不要使用可变类型作为参数的默认值 1. 不要使用可变类型作为参数的默认值 摘自<流畅的Python>8.4.1 class HauntedBus: ""&q ...
- DS-4-单链表的各种插入与删除的实现
typedef struct LNode { int data; struct LNode *next; }LNode, *LinkList; 带头结点的按位序插入: //在第i个位置插入元素e bo ...
- cb45a_c++_STL_算法_删除_(3)_unique(唯一的意思)删除连续性的重复的数据
cb45a_c++_STL_算法_删除_(3)_unique(唯一的意思)删除连续性的重复的数据unique(b,e),删除连续性的,删除重复的数据,比如如果有两个连续的5,5,则留下一个.uniqu ...