入门大数据---ClouderaManager和CDH是什么?
1.CDH概述
CDH(Cloudra's Distribution Apache Of Hadoop)是Apache Hadoop和相关项目的最完整,经过测试和最流行的发行版。CDH提供Hadoop的核心要素–可扩展的存储和分布式计算–以及基于Web的用户界面和重要的企业功能。CDH是Apache许可的开源软件,并且是唯一提供统一批处理,交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。 一句话概括CDH就是集成多种技术的一个框架。
CDH提供
- 灵活性-存储任何类型的数据并使用各种不同的计算框架进行处理,包括批处理,交互式SQL,自由文本搜索,机器学习和统计计算。
- 集成-在可与广泛的硬件和软件解决方案一起使用的完整Hadoop平台上快速启动并运行。
- 安全性-处理和控制敏感数据。
- 可扩展性-启用广泛的应用程序并进行扩展,并扩展它们以满足您的要求。
- 高可用性-自信地执行关键任务业务任务。
- 兼容性-利用您现有的IT基础架构和投资。
Hadoop生态构成
- HDFS:分布式文件系统
- ZKFC:为实现NameNode高可用,在NameNode和Zookeeper之间传递信息,选举主节点工具。
- NameNode:存储文件元数据
- DateNode:存储具体数据
- JournalNode:同步主NameNode节点数据到从节点NameNode
- MapReduce:开源的分布式批处理计算框架
- Spark:分布式基于内存的批处理框架
- Zookeeper:分布式协调管理
- Yarn:调度资源管理器
- HBase:基于HDFS的NoSql列式数据库
- Hive:将SQL转换为MapReduce进行计算
- Hue:是CDH的一个UI框架
- Impala:是Cloudra公司开发的一个查询系统,类似于Hive,可以通过SQL执行任务,但是它不基于MapReduce算法,而是直接执行分布式计算,这样就提高了效率。
- oozie:是一个工作流调度引擎,负责将多个任务组合在一起按序执行。
- kudu:Apache Kudu是转为hadoop平台开发的列式存储管理器。和impala结合使用,可以进行增删改查。
- Sqoop:将hadoop和关系型数据库互相转移的工具。
- Flume:采集日志
- 还有一些其它的
CDH结构图
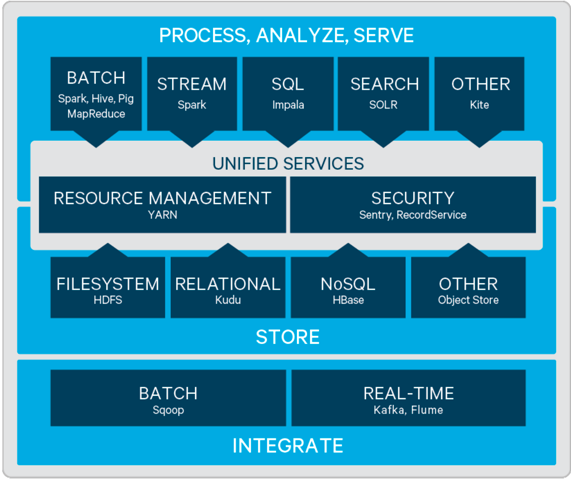
2.Cloudra Manager概述
Cloudra Manager简称CM,它是一个web操作平台,可以借助安装CDH然后安装多种Hadoop框架。
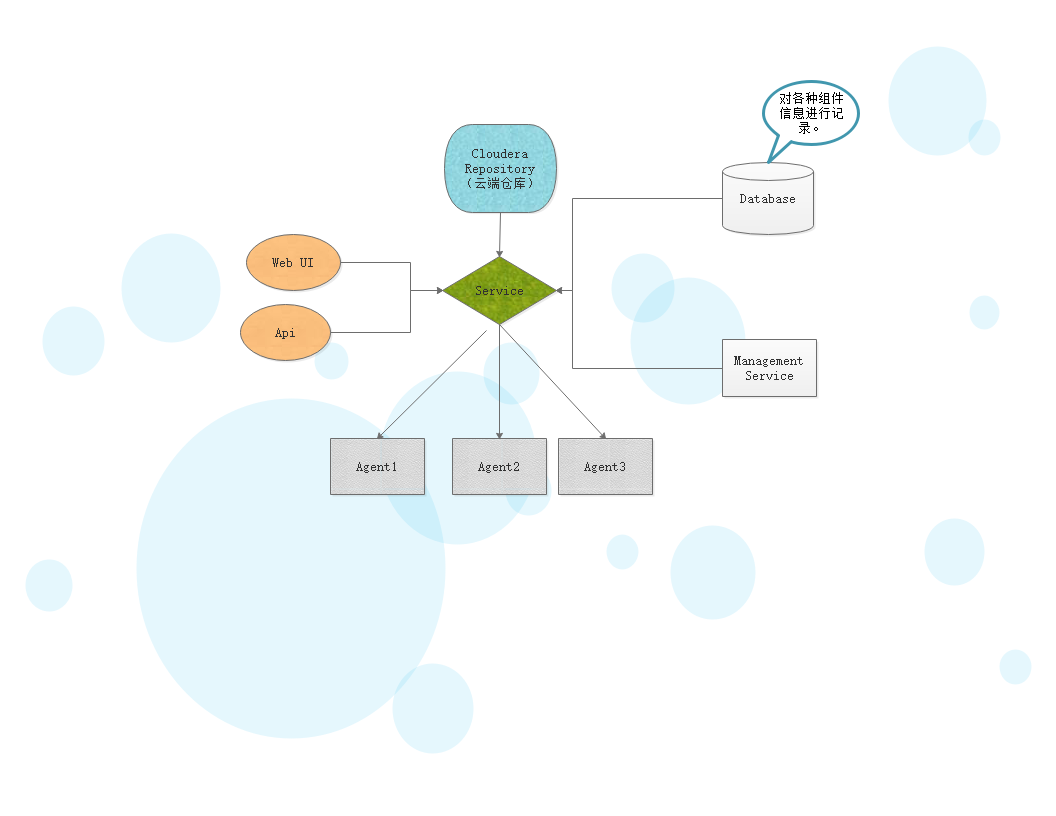
CloudraManager技术构成
Clients:客户端,通过web页面和ClouderaManager和服务器进行交互。
API:通过API和ClouderaManagement和服务器进行交互
Cloudera Repository:存储分发安装包
Management Server:进行监控和预警
Database:存储预警信息和配置信息。
Agent:分布在多台服务器,负责配置,启动和停止进程。监控主机。
结构图如下:
入门大数据---ClouderaManager和CDH是什么?的更多相关文章
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
随机推荐
- golang内置类型和内置函数
golang内置类型和内置函数是不需要引入包直接可用的 golang内置类型: 数值类型 string int,unint float32,float64 bool array 有长度的 comple ...
- Beta冲刺 —— 5.31
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.讨论并解决每个人存在的问 ...
- rewrite和return的简单需求
Rewrite 需求作业 背景:现在我有一个网站,www.linux.com www.linux.com访问主页面 friend.linux.com访问交友页面 blog.linux.com访问博客页 ...
- Java实现 洛谷 P1909 买铅笔
import java.util.Arrays; import java.util.Scanner; public class Main { public static void main(Strin ...
- java实现填写算式
** 填写算式** 看这个算式: ☆☆☆ + ☆☆☆ = ☆☆☆ 如果每个五角星代表 1 ~ 9 的不同的数字. 这个算式有多少种可能的正确填写方法? 173 + 286 = 459 295 + 17 ...
- 从linux源码看socket的阻塞和非阻塞
从linux源码看socket的阻塞和非阻塞 笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情. 大部分高性能网络框架采用的是非阻塞模式.笔者这次就从linux ...
- Spring AOP学习笔记02:如何开启AOP
上文简要总结了一些AOP的基本概念,并在此基础上叙述了Spring AOP的基本原理,并且辅以一个简单例子帮助理解.从本文开始,我们要开始深入到源码层面来一探Spring AOP魔法的原理了. 要使用 ...
- Canvas绘制圆点线段
最近一个小伙遇到一个需求,客户需要绘制圆点样式的线条. 大致效果是这样的: 思路一:计算并使用arc填充 他自己实现了一种思路,然后咨询我有没有更好的思路. 先看看他的思路是如何实现的,大致代码如下: ...
- python2.7 正则表达式的学习
正则表达式是一种用来匹配字符串的强有力的武器.它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的. 因正则表达式也是用字符 ...
- Nice Jquery Validator 常用规则整理
一些简单规则 numeric: [/^[0-9]*$/, '请填写数值'], money: [/^(?:0|[1-9]\d*)(?:\.\d{1,2})?$/, "请填写有效的金额" ...