Python做数据预处理
在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析(你愿意花十分钟系统了解数据分析方法吗?),对数据探索性分析之后要先进行一系列的数据预处理步骤。因为拿到的原始数据存在不完整、不一致、有异常的数据,而这些“错误”数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差,因此首先要数据清洗。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
1. 缺失值处理
由于人员录入数据过程中或者存储器损坏等原因,缺失值在一份数据中或多或少存在,所以首先就需要对缺失值进行处理,缺失值处理总的原则是:使用最可能的值代替缺失值,使缺失值与其他数值之间的关系保持最大。具体的常用方法如下:
- 删除缺失值(缺失值占比很小的情况)
- 人工填充 (数据集小,缺失值少)
- 用全局变量填充(将缺失值填充一常数如“null”)
- 使用样本数据的均值或中位数填充
- 用插值法(如拉格朗日法、牛顿法)
Python缺失值处理实例代码:
a、判断删除缺失值- -isnull,notnull
- 判断缺失值可以用来计算缺失值占比整个数据的大小,如果占比很小可以删除缺失值。
b、填充替换缺失值--fillna
- 如果缺失值不可以占比很多,就不能能够轻易的删除缺失值,可以用上述的插值方法填充缺失值。
c、核心代码和结果图:

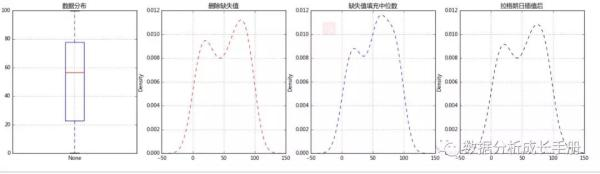
2. 异常值处理
异常值是数据集中偏离大部分数据的数据。从数据值上表现为:数据集中与平均值的偏差超过两倍标准差的数据,其中与平均值的偏差超过三倍标准差的数据(3σ原则),称为高度异常的异常值。
- 异常值分析方法
- 3σ原则 (数据分布为正态分布)
- 箱型图分析(内限or外限)。
常用处理方法如下:
- 直接删除 (异常值占比小)
- 暂且保留,待结合整体模型综合分析
- 利用现有样本信息的统计量填充(均值等)
Python异常值处理实例代码:
- 检验是否符合正态分布,符合用3σ原则判断并处理,核心代码结果如下:

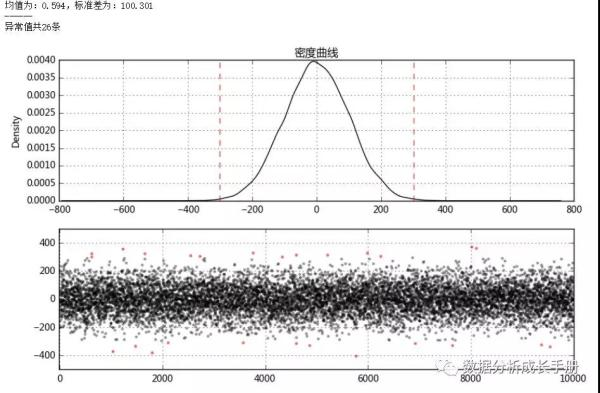
2. 当不符合正态分布时可用箱型图分析处理,核心结果代码如下:
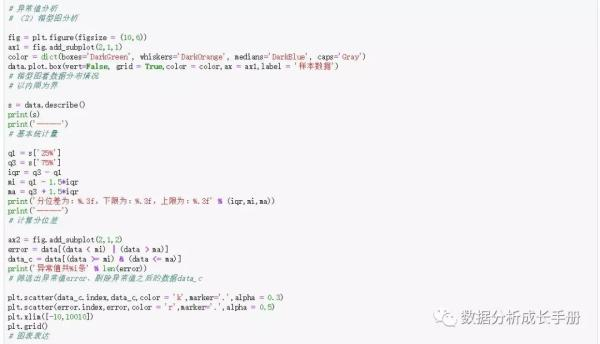

3. 数据标准化处理
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权,最典型的就是数据归一化处理就是将数据统一映射到[0,1]区间上 。
常用数据标准化方法:
- MIN- MAX标准化(x - x_min)/(x_max-x_min)
- z-score标准化(x-x_mean)/x_std
- 小数定标标准化
- 向量归一化
- 线性比例变换法
- 平均值法
- 指数转换法
归一化的目的:
- 使得预处理的数据被限定在一定的范围
- 消除奇异样本数据导致的不良影响
在大佬Ng的视频课中听过一句话,归一化会加快梯度下降的求解速度。
应用场景说明:
- SVM、线性回归之类的最优化问题需要归一化,是否归一化主要在于是否关心变量取值;
- 神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是为了弱化某些变量的值较大而对模型产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmod激活函数要好些,因为tanh双曲正切函数的取值[-1,1]之间,均值为0;
- 在K近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微。
注意:没有一种数据标准化的方法,放在每一个问题,放在每一个模型,都能提高算法精度和加快算法的收敛速度。所以对于不同的问题可能会有不同的归一化方法。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
4. 数据连续属性离散化
一些数据挖掘算法,特别是分类算法,要求数据是分类属性形式。常常需要将连续属性变换成分类属性,即连续属性离散化。 常用的离散化方法:
- 等宽法:将属性值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由用户指定,类似于制作频率分布表。
- 等频法:将相同数量的记录放进每个区间。
- 基于聚类分析的方法。 通过分箱离散化、通过直方图分析离散化、通过聚类、决策树和相关分析离散化、标称数据的概念分层产生
5. 总结
本文是笔者在学习数据分析过程中记录下来的一些通用的数据预处理步骤,并且用Numpy、Pandas、Matplotlib等实现了每一种处理方法并可视化了处理结果。
转载:http://bigdata.51cto.com/art/201901/591222.htm
Python做数据预处理的更多相关文章
- Python数据挖掘——数据预处理
Python数据挖掘——数据预处理 数据预处理 数据质量 准确性.完整性.一致性.时效性.可信性.可解释性 数据预处理的主要任务 数据清理 数据集成 数据归约 维归约 数值归约 数据变换 规范化 数据 ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 吴裕雄 python 机器学习——数据预处理二元化Binarizer模型
from sklearn.preprocessing import Binarizer #数据预处理二元化Binarizer模型 def test_Binarizer(): X=[[1,2,3,4,5 ...
随机推荐
- js——private 私有方法公有化
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- delete 和 splice 删除数组中元素的区别
delete 和 splice 删除数组中元素的区别 ` var arr1 = ["a","b","c","d"]; d ...
- Linux 线程Demo
#include <stdio.h> #include <pthread.h> struct char_print_params { char character; int c ...
- python安装 cvxpy 巨坑,一堆C++错误
https://www.lfd.uci.edu/~gohlke/pythonlibs/#ecos 下载scs,ecos,cvxpy的whl,一个个安装即可 之前被一堆C++错误搞晕了2小时
- c# api身份验证和授权
授权 1. 全局 config.Filters.Add(new AuthorizeAttribute()); 2.控制器级别 [Authorize] public class HelloControl ...
- (15)centos7 系统服务
centos7 服务启动脚本在 /usr/lib/systemd目录下 1.服务基本操作指令 systemclt [command] [unit] #其中command包括: #start 立即启动 ...
- ThinkPHP5验证码不显示的原因及解决方法
其实很久之前刚学习tp5框架的时候就遇到了这个问题,解决完后一直没再出过问题,今天用以前的框架做新项目时又碰到了这个问题,这里记录一下 问题原因: 1.TP5本就存在这个bug 2.数据库连接不正常( ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Unity中嵌入网页插件Embedded Browser2.1.0
背景 最近刚换了工作,新公司不是做手游的,一开始有点抵触,总觉得不是做游戏自己就是跨行了,认为自己不对口,但是慢慢发现在这可以学的东西面很广,所以感觉又到了打怪升级的时候了,老子就在这进阶了. 一进公 ...
- python接口自动化(post请求)
python接口自动化(post请求) 一.post请求的作用:新增资源 二.data格式的参数请求(data是字典对象) #1.导包 import requests #2.调用post方法 #请求的 ...