吴裕雄--天生自然 R语言数据可视化绘图(2)
par(ask=TRUE)
opar <- par(no.readonly=TRUE) # save original parameter settings library(vcd)
counts <- table(Arthritis$Improved)
counts
# Listing 6.1 - Simple bar plot
# vertical barplot
barplot(counts,
main="Simple Bar Plot",
xlab="Improvement", ylab="Frequency")
# horizontal bar plot
barplot(counts,
main="Horizontal Bar Plot",
xlab="Frequency", ylab="Improvement",
horiz=TRUE)

# obtain 2-way frequency table
library(vcd)
counts <- table(Arthritis$Improved, Arthritis$Treatment)
counts # Listing 6.2 - Stacked and grouped bar plots
# stacked barplot
barplot(counts,
main="Stacked Bar Plot",
xlab="Treatment", ylab="Frequency",
col=c("red", "yellow","green"),
legend=rownames(counts))
# grouped barplot
barplot(counts,
main="Grouped Bar Plot",
xlab="Treatment", ylab="Frequency",
col=c("red", "yellow", "green"),
legend=rownames(counts), beside=TRUE)
# Listing 6.3 - Bar plot for sorted mean values
states <- data.frame(state.region, state.x77)
means <- aggregate(states$Illiteracy, by=list(state.region), FUN=mean)
means means <- means[order(means$x),]
means barplot(means$x, names.arg=means$Group.1)
title("Mean Illiteracy Rate")

# Listing 6.3 - Bar plot for sorted mean values
states <- data.frame(state.region, state.x77)
means <- aggregate(states$Illiteracy, by=list(state.region), FUN=mean)
means means <- means[order(means$x),]
means barplot(means$x, names.arg=means$Group.1)
title("Mean Illiteracy Rate")

# Listing 6.4 - Fitting labels in bar plots
par(las=2) # set label text perpendicular to the axis
par(mar=c(5,8,4,2)) # increase the y-axis margin
counts <- table(Arthritis$Improved) # get the data for the bars # produce the graph
barplot(counts,
main="Treatment Outcome", horiz=TRUE, cex.names=0.8,
names.arg=c("No Improvement", "Some Improvement", "Marked Improvement")
)
par(opar)
# Spinograms
library(vcd)
attach(Arthritis)
counts <- table(Treatment,Improved)
spine(counts, main="Spinogram Example")
detach(Arthritis)

# Listing 6.5 - Pie charts
par(mfrow=c(2,2))
slices <- c(10, 12,4, 16, 8)
lbls <- c("US", "UK", "Australia", "Germany", "France") pie(slices, labels = lbls,
main="Simple Pie Chart")

pct <- round(slices/sum(slices)*100)
lbls <- paste(lbls, pct)
lbls <- paste(lbls,"%",sep="")
pie(slices,labels = lbls, col=rainbow(length(lbls)),
main="Pie Chart with Percentages")

library(plotrix)
pie3D(slices, labels=lbls,explode=0.1,
main="3D Pie Chart ") mytable <- table(state.region)
lbls <- paste(names(mytable), "\n", mytable, sep="")
pie(mytable, labels = lbls,
main="Pie Chart from a dataframe\n (with sample sizes)") par(opar)
mytable <- table(state.region)
lbls <- paste(names(mytable), "\n", mytable, sep="")
pie(mytable, labels = lbls,
main="Pie Chart from a dataframe\n (with sample sizes)") par(opar)

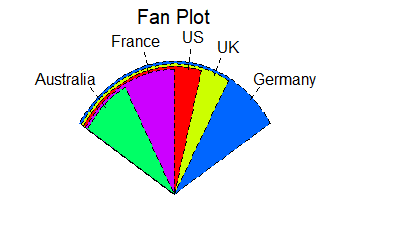
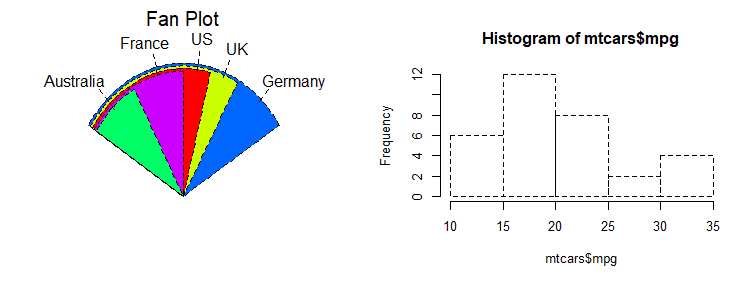
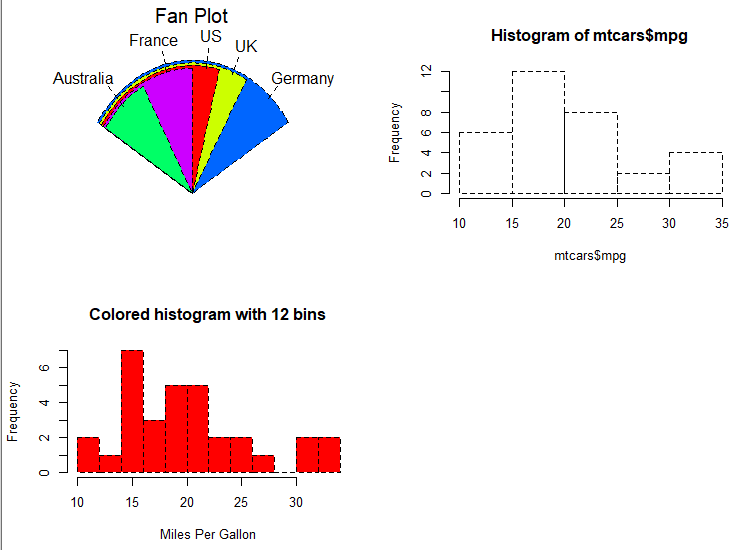
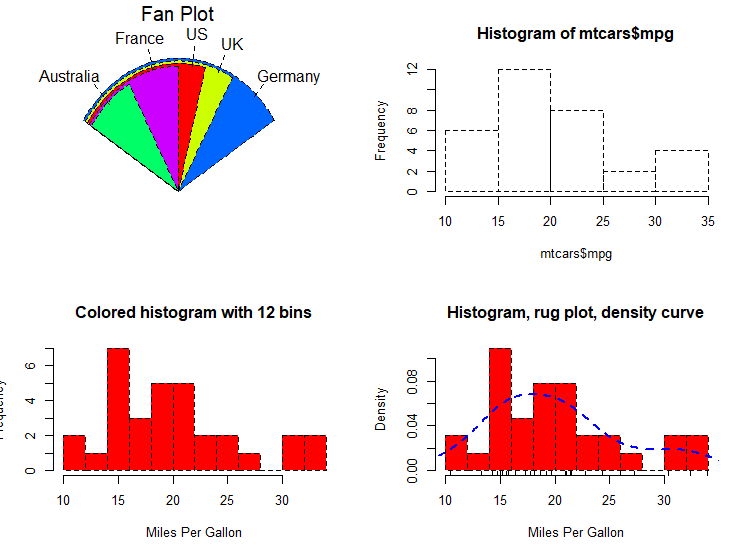
# Fan plots
library(plotrix)
slices <- c(10, 12,4, 16, 8)
lbls <- c("US", "UK", "Australia", "Germany", "France")
fan.plot(slices, labels = lbls, main="Fan Plot")
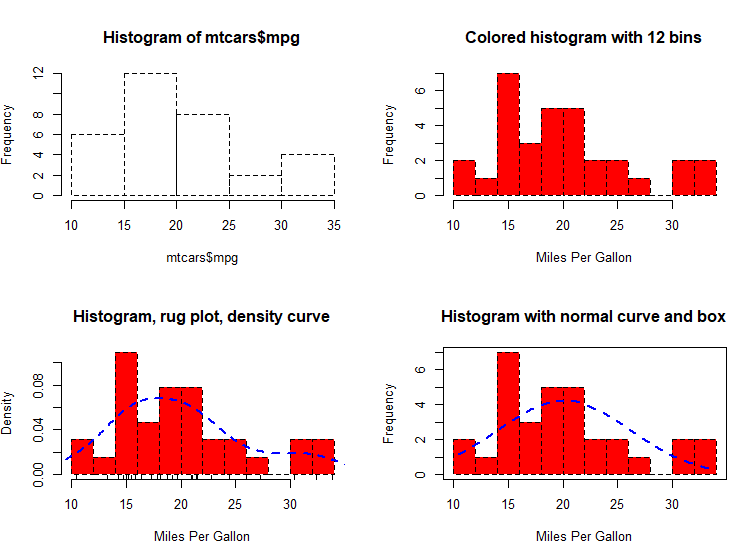
# Listing 6.6 - Histograms
# simple histogram 1
hist(mtcars$mpg)
# colored histogram with specified number of bins
hist(mtcars$mpg,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Colored histogram with 12 bins")
# colored histogram with rug plot, frame, and specified number of bins
hist(mtcars$mpg,
freq=FALSE,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Histogram, rug plot, density curve")
rug(jitter(mtcars$mpg))
lines(density(mtcars$mpg), col="blue", lwd=2)
# histogram with superimposed normal curve (Thanks to Peter Dalgaard)
x <- mtcars$mpg
h<-hist(x,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Histogram with normal curve and box")
xfit<-seq(min(x),max(x),length=40)
yfit<-dnorm(xfit,mean=mean(x),sd=sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col="blue", lwd=2)
box()
# Listing 6.6 - Histograms
# simple histogram 1
hist(mtcars$mpg) # colored histogram with specified number of bins
hist(mtcars$mpg,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Colored histogram with 12 bins") # colored histogram with rug plot, frame, and specified number of bins
hist(mtcars$mpg,
freq=FALSE,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Histogram, rug plot, density curve")
rug(jitter(mtcars$mpg))
lines(density(mtcars$mpg), col="blue", lwd=2) # histogram with superimposed normal curve (Thanks to Peter Dalgaard)
x <- mtcars$mpg
h<-hist(x,
breaks=12,
col="red",
xlab="Miles Per Gallon",
main="Histogram with normal curve and box") xfit<-seq(min(x),max(x),length=40)
yfit<-dnorm(xfit,mean=mean(x),sd=sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col="blue", lwd=2)
box()
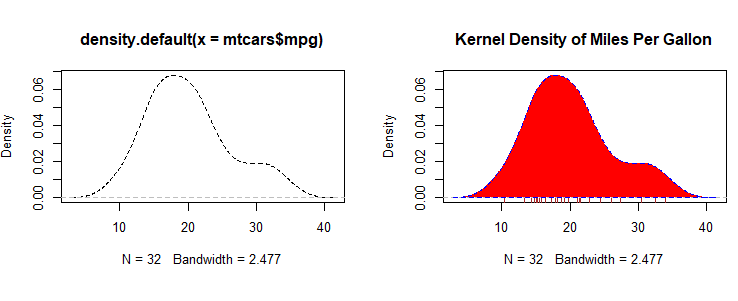
# Listing 6.7 - Kernel density plot
d <- density(mtcars$mpg) # returns the density data
plot(d) # plots the results

d <- density(mtcars$mpg)
plot(d, main="Kernel Density of Miles Per Gallon")
polygon(d, col="red", border="blue")
rug(mtcars$mpg, col="brown")
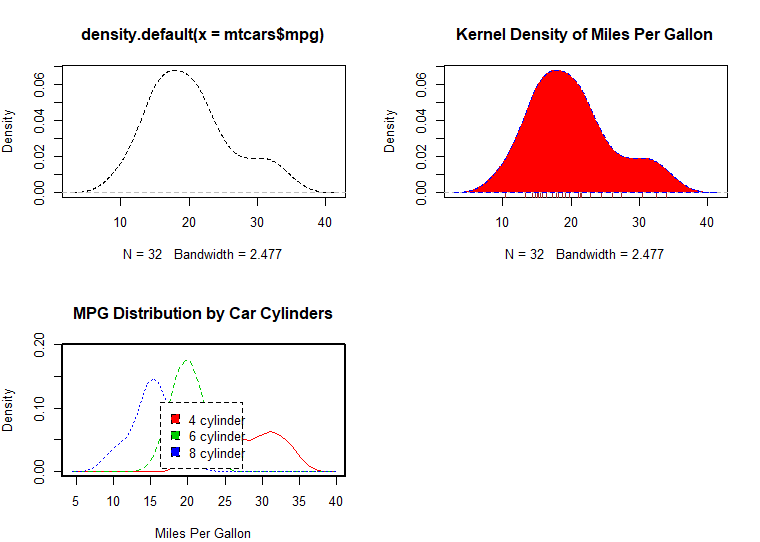
# Listing 6.8 - Comparing kernel density plots
par(lwd=2)
library(sm)
attach(mtcars) # create value labels
cyl.f <- factor(cyl, levels= c(4, 6, 8),
labels = c("4 cylinder", "6 cylinder", "8 cylinder")) # plot densities
sm.density.compare(mpg, cyl, xlab="Miles Per Gallon")
title(main="MPG Distribution by Car Cylinders")

# add legend via mouse click
colfill<-c(2:(2+length(levels(cyl.f))))
cat("Use mouse to place legend...","\n\n")
legend(locator(1), levels(cyl.f), fill=colfill)
detach(mtcars)
par(lwd=1)
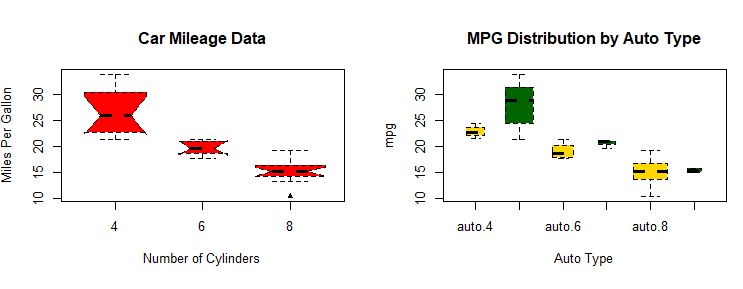
# parallel box plots
boxplot(mpg~cyl,data=mtcars,
main="Car Milage Data",
xlab="Number of Cylinders",
ylab="Miles Per Gallon")
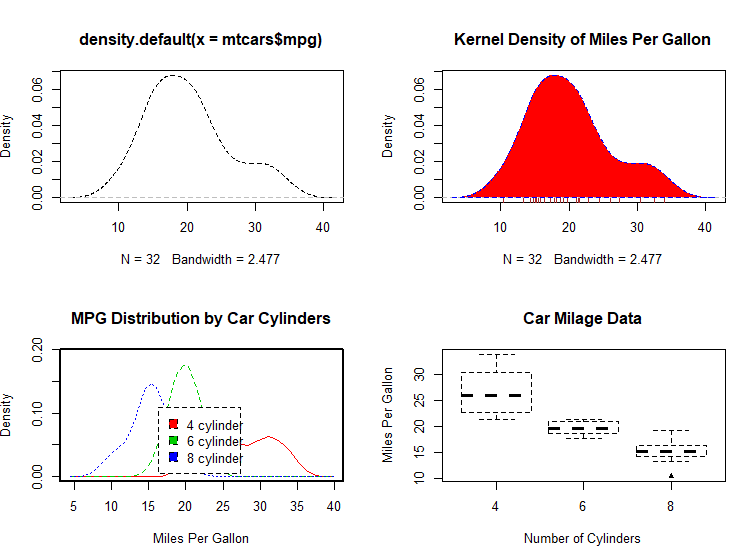
# notched box plots
boxplot(mpg~cyl,data=mtcars,
notch=TRUE,
varwidth=TRUE,
col="red",
main="Car Mileage Data",
xlab="Number of Cylinders",
ylab="Miles Per Gallon")

# Listing 6.9 - Box plots for two crossed factors
# create a factor for number of cylinders
mtcars$cyl.f <- factor(mtcars$cyl,
levels=c(4,6,8),
labels=c("4","6","8"))
# create a factor for transmission type
mtcars$am.f <- factor(mtcars$am,
levels=c(0,1),
labels=c("auto","standard"))
# generate boxplot
boxplot(mpg ~ am.f *cyl.f,
data=mtcars,
varwidth=TRUE,
col=c("gold", "darkgreen"),
main="MPG Distribution by Auto Type",
xlab="Auto Type")
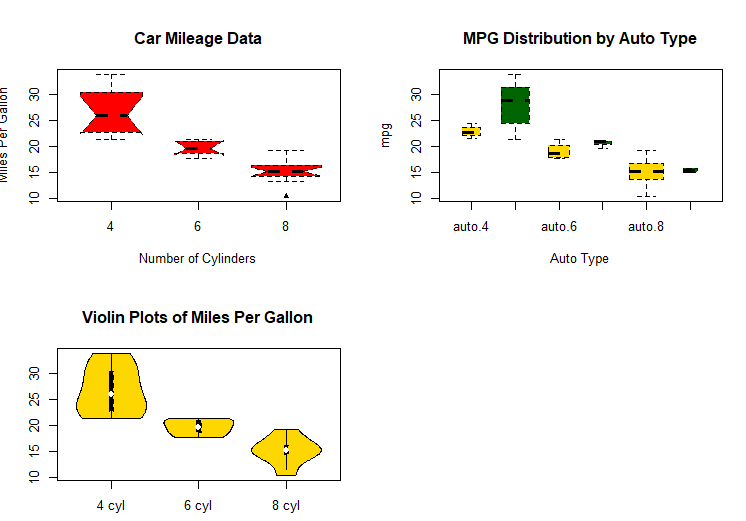
# Listing 6.10 - Violin plots library(vioplot)
x1 <- mtcars$mpg[mtcars$cyl==4]
x2 <- mtcars$mpg[mtcars$cyl==6]
x3 <- mtcars$mpg[mtcars$cyl==8]
vioplot(x1, x2, x3,
names=c("4 cyl", "6 cyl", "8 cyl"),
col="gold")
title("Violin Plots of Miles Per Gallon")
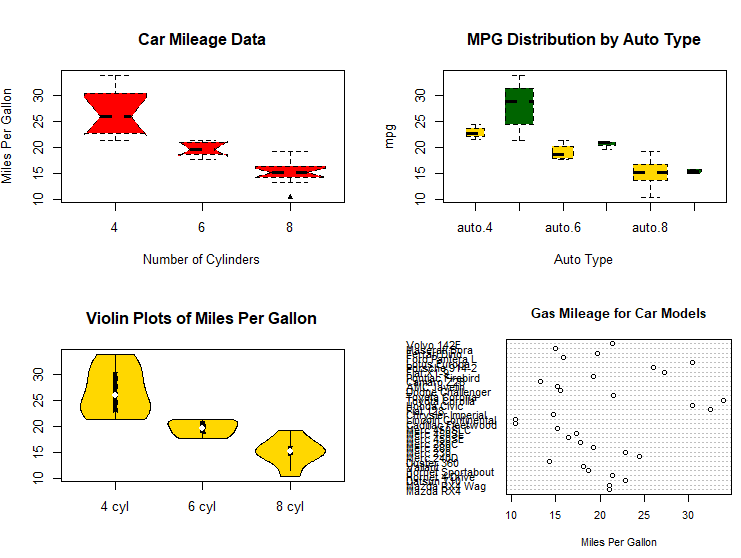
# dot chart
dotchart(mtcars$mpg,labels=row.names(mtcars),cex=.7,
main="Gas Mileage for Car Models",
xlab="Miles Per Gallon")
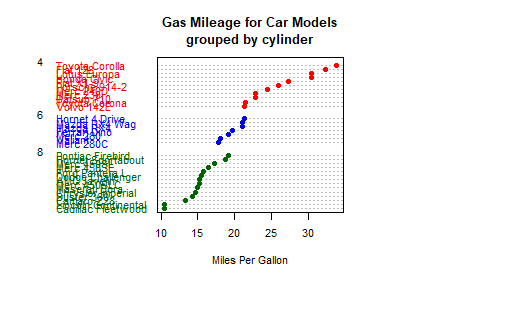
# Listing 6.11 - Dot plot grouped, sorted, and colored
x <- mtcars[order(mtcars$mpg),]
x$cyl <- factor(x$cyl)
x$color[x$cyl==4] <- "red"
x$color[x$cyl==6] <- "blue"
x$color[x$cyl==8] <- "darkgreen"
dotchart(x$mpg,
labels = row.names(x),
cex=.7,
pch=19,
groups = x$cyl,
gcolor = "black",
color = x$color,
main = "Gas Mileage for Car Models\ngrouped by cylinder",
xlab = "Miles Per Gallon")
吴裕雄--天生自然 R语言数据可视化绘图(2)的更多相关文章
- 吴裕雄--天生自然 R语言数据可视化绘图(3)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # record current settings # Listing 11.1 - A scatter ...
- 吴裕雄--天生自然 R语言数据可视化绘图(4)
par(ask=TRUE) # Basic scatterplot library(ggplot2) ggplot(data=mtcars, aes(x=wt, y=mpg)) + geom_poin ...
- 吴裕雄--天生自然 R语言数据可视化绘图(1)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # make a copy of current settings attach(mtcars) # be ...
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:处理缺失数据的高级方法(续一)
#-----------------------------------# # R in Action (2nd ed): Chapter 18 # # Advanced methods for mi ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
随机推荐
- C/C++画一个巨型五角星
把朱老师拉着画了半天 利用正弦定理判断一个点是否是否在五角星内,相对于五角星中心的四个象限特判一下来修改角度,把角度都转化成最上面的角,就差不多了,没仔细调整五角星位置,很丑 当然其实也有更方便的方法 ...
- Springboot | Failed to execute goal org.springframework.boot:spring-boot-maven-plugin
案例 今天搭建spring boot 环境时,使用mvn install ,出现Failed to execute goal org.springframework.boot:spring-boot- ...
- 二、Linux系统硬链接和软链接详细介绍与实践
链接的概念 在linux系统中,链接可分为两种:一种被称为硬链接(Hard LinK),另一种被称为软链接或符号链接(Symbolic Link).在默认不带参数的情况下,执行ln命令创建的链接是硬链 ...
- asp.net core 3.x 身份验证-2启动阶段的配置
注册服务.配置选项.添加身份验证方案 在Startup.ConfigureServices执行services.AddAuthentication() 注册如下服务(便于理解省略了部分辅助服务): s ...
- POJ_1166_暴搜
题目描述: 有3*3的9个时钟,每个始终有0,1,2,3四种可以循环的状态码,每组数据给我们9个时钟的一种状态码.另外还有9种操作,分别使指定位置的时钟状态码加一,求使得9个时钟状态码全部置于0的最少 ...
- POJ 1751 Highways(最小生成树Prim普里姆,输出边)
题目链接:点击打开链接 Description The island nation of Flatopia is perfectly flat. Unfortunately, Flatopia has ...
- python之面向对象01
1.面向过程编程最容易被初学者接受,其往往用一段长代码来实现指定功能,开发过程的思路是将数据与函数按照执行的逻辑顺序组织在一起,数据与函数分开考虑. 2.类与对象 (1)类是抽象的,是有相同属性和行为 ...
- get post 区别【转】
应该是最简洁直接的了???? Get:是以实体的方式得到由请求URI所指定资源的信息,如果请求URI只是一个数据产生过程,那么最终要在响应实体中返回的是处理过程的结果所指向的资源,而不是处理过程的描述 ...
- DBA常用SQL之DDL生成语句-2
------数据迁移常用SQL SELECT 'DROP USER '||u.username ||' CASCADE;' AS dropstrs FROM DBA_USERS U where u.u ...
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...