斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1、如果需要很高的置信度的话,查准率会很高,相应的召回率很低;2、如果需要避免假阴性的话,召回率会很高,查准率会很低。下图右边显示的是召回率和查准率在一个学习算法中的关系。值得注意的是,没有一个学习算法是能同时保证高查准率和召回率的,要高查准率还是高召回率,取决于自己的需求。此外,查准率和召回率之间的关系曲线可以是多样性,不一定是图示的形状。

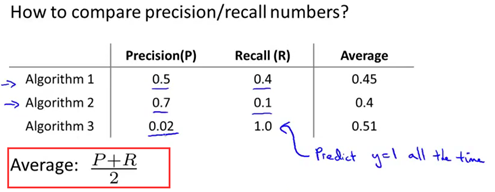
如何取舍查准率和召回率数值:
一开始提出来的算法有取查准率和召回率的平均值,如下面的公式average=(P+R)/2。显然,在给出的三个算法当中,算法3的平均值是最高的,然而通过查准率(0.02)和召回率(1.0)可以看出这并不是一个很好的模型。因此,取平均值这个评估模式是不可取的。
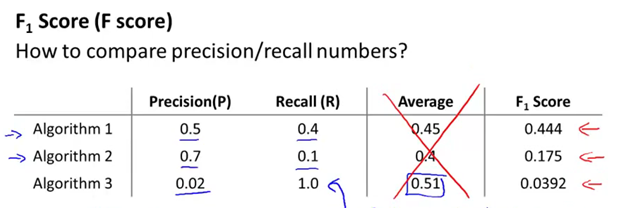
如果采用F score算法来同时评估查准率和召回率,则是比较有用的算法。分子的PR决定了查准率(P)和召回率(R)必须同时比较大,才能保证F score数值比较大。假如查准率或者召回率很低,接近于0,直接导致的后果PR值非常低,趋近于0,也就是F score也很低。

此时再比较三个算法,可发现算法1是最优的,同时我们观察到算法3在这个公式中F score值是最低的。很好的说明了算法3不是一个很好的模型(查准率太低)。说明F score是一个很好的同时评估查准率和召回率的公式。
斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:Neural Networks,representation: non-linear hypotheses(为什么需要做非线性分类器)
如上图所示,如果用逻辑回归来解决这个问题,首先需要构造一个包含很多非线性项的逻辑回归函数g(x).这里g仍是s型函数(即 ).我们能让函数包含很多像这的多项式,当多项式足够多时,那么你也许能够得到可以 ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
随机推荐
- AI算法第一天【概述与数学初步】
1. 机器学习的定义: 机器从数据中学习出规律和模式,以应用在新数据上作出预测的任务 2.学习现象: (1)语言文字的认知识别 (2)图像,场景,物体的认知和识别 (3)规则:下雨天要带雨伞 (4)复 ...
- 1.Java简介
第一章 Java简介 开始上传一些自己画的思维导图 画的基本上是根据菜鸟教程Java的对应的图 会有一系列的图陆续放出来,不过博客上只有截图,具体的带注释的具体的图后续会放在git上,更新会加上git ...
- idea -> Error during artifact deployment. See server log for details.
用idea导入eclipse工程,运行时,报Error during artifact deployment. See server log for details. 谷歌,最后发现是最新 tomc ...
- 安装 BizTalk Server 2016
在单台计算机上安装 BizTalk Server. 开始操作之前 系统管理员 – 安装 SQL Server 时,安装程序会自动向登录的帐户授予系统管理员权限. 由于安装 BizTalk ...
- 洛谷 P2921 [USACO08DEC]在农场万圣节Trick or Treat on the Farm
题目描述 每年,在威斯康星州,奶牛们都会穿上衣服,收集农夫约翰在N(1<=N<=100,000)个牛棚隔间中留下的糖果,以此来庆祝美国秋天的万圣节. 由于牛棚不太大,FJ通过指定奶牛必须遵 ...
- 彻底弄懂 HTTP 缓存机制及原理 | 干货
来源:www.cnblogs.com/chenqf/p/6386163.html 前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个 ...
- linux系统命令大全
文件管理 cat chattr chgrp chmod chown cksum cmp cp cut diff diffstat file find git gitview in indent les ...
- Google浏览器——AxureRP_for_chorme_0_6_2添加
准备 链接:https://share.weiyun.com/5PVwSMA Google浏览器版本 步骤 压缩解压 首先把需要安装的第三方插件,后缀.crx 改成 .rar,然后解压,得到一个文件夹 ...
- ContOS7编译安装python3,配置虚拟环境
Python36编译安装 一,下载python源码包 网址:https://www.python.org/downloads/release/python-367/ # 软件包下载到/opt目录 cd ...
- 配置Robot Framework 环境时如何查看wxPython是否成功安装
配置Robot Framework,win10系统,安装版本分别如下: