爬虫——scrapy框架
Scrapy是一个异步处理框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可拓展性强,可以灵活完成各种需求。我们只需要定制几个模块就可以轻松实现一个爬虫。
1.架构

Scrapy Engine,引擎,负责整个系统的数据流处理、触发事务,是整个框架的核心。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成Item对象。
Scheduler,调度器,接受引擎发送过来的请求,并将其加入到队列之中,在引擎再次请求时将请求提供给引擎。
Downloader,下载器,下载网页内容,并将网页内容返回给爬虫。
Sprider,爬虫,其内定义了爬取逻辑和网页的解析规则,它主要负责解析响应并生成提取结果的新的请求。
Item Pipeline,项目管道,负责处理由爬虫从网页中提取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器直接的钩子框架,主要处理引擎与下载器之间的请求和响应。
Spider Middle,爬虫中间件,位于引擎和爬虫之间的钩子框架,主要处理爬虫输入的响应和输出的结果及新请求。
2.数据流
Scrapy中的数据流由引擎控制,数据流的过程如下:
(1)scrapy engine打开一个网站,找到该网站的Sprider,并向该Sprider请求第一个需要爬取的URL。
3.创建项目
在pycharm的终端Terminal : scrapy startproject tutorial ,
然后在pycharm打开该项目得到如下目录:
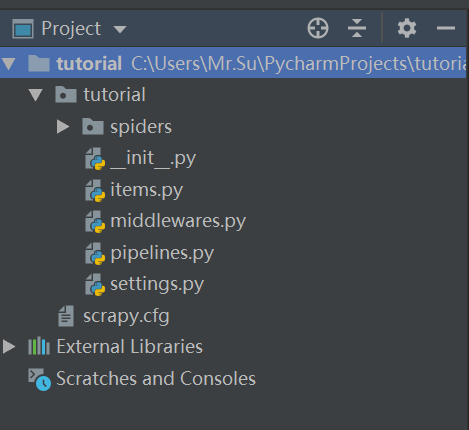
- scrapy.cfg: 项目的配置文件
- tutorial/items.py: 项目中的item文件,定义数据结构。
- tutorial/pipelines.py: 项目中的pipelines文件,数据存储,操作数据。
- tutorial/settings.py: 项目的设置文件。
- tutorial/spiders/: 放置spider代码的目录。
4.创建Spider
spider是自己定义的类,Scrapy用它来抓取内容。并解析抓取的结果。不过这个类必须继承Scrapy提供的Spider类scrapy.Sprider,还要定义Spider的名称和起始请求。
命令行创建spider : scrapy genspider quotes quotes.toscrape.com # -*- coding: utf- -*-
import scrapy class QuotesSpider(scrapy.Spider):
name = 'quotes' #用来区分不同的Spider
allowed_domains = ['quotes.toscrape.com'] #允许爬取的域名
start_urls = ['http://quotes.toscrape.com/'] #spider启动时爬取的url列表 def parse(self, response):#负责解析返回的响应、提取数据或者进一步生成要处理的请求。
#response是爬取start_url的结果
pass
4.创建item
item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。假设我们需要获取的内容是name、age、 sex。
修改item.py如下:
# -*- coding: utf- -*- # Define here the models for your scraped items
#保存和爬取数据的容器
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuoteItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
age = scrapy.Field()
sex = scrapy.Field()
pass
scrapy demo:爬取http://quotes.toscrape.com/的author、text、tags,并保存为json、csv文件。
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#保存和爬取数据的容器
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuoteItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
# tags = scrapy.Field()
pass
spirders/quotes.py
# -*- coding: utf- -*-
import scrapy
from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider):
name = 'quotes' #用来区分不同的Spider
allowed_domains = ['quotes.toscrape.com'] #允许爬取的域名
start_urls = ['http://quotes.toscrape.com/'] #spider启动时爬取的url列表 def parse(self, response): #负责解析返回的响应、提取数据或者进一步生成要处理的请求 #数据提取
quotes = response.css('.quote') #选择所有的quote
for quote in quotes:
item = QuoteItem() #.text::text 表示选择class=text的节点的正文内容
item['text'] = quote.css('.text::text').extract_first() #获取节点的内容:.text::text表示获取其内容text
item['author'] = quote.css('.author::text').extract_first()# .extract_first表示获取其正文的第一个元素
#item['tags'] = quote.css('.tags::text').extract_first()
yield item next = response.css('.pager .next a::attr("href")').extract_first() #获取下一个需要爬取的页面
url = response.urljoin(next)#urljoin()将相对url构造成一个绝对url
yield scrapy.Request(url=url,callback = self.parse) #回调函数 命令行运行: scrapy crawl quotes
执行完成后,我们可以在命令行查看运行结果,但是如何把执行结果保存为json文件或者csv文件呢?
scrapy支持多种格式输出:
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.csv
#运行成功后,项目根目录里会自动生成json和csv文件。
爬虫——scrapy框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 爬虫scrapy框架之CrawlSpider
爬虫scrapy框架之CrawlSpider 引入 提问:如果想要通过爬虫程序去爬取全站数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模 ...
- 安装爬虫 scrapy 框架前提条件
安装爬虫 scrapy 框架前提条件 (不然 会 报错) pip install pypiwin32
- 爬虫Ⅱ:scrapy框架
爬虫Ⅱ:scrapy框架 step5: Scrapy框架初识 Scrapy框架的使用 pySpider 什么是框架: 就是一个具有很强通用性且集成了很多功能的项目模板(可以被应用在各种需求中) scr ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- 爬虫Scrapy框架运用----房天下二手房数据采集
在许多电商和互联网金融的公司为了更好地服务用户,他们需要爬虫工程师对用户的行为数据进行搜集.分析和整合,为人们的行为选择提供更多的参考依据,去服务于人们的行为方式,甚至影响人们的生活方式.我们的scr ...
- 自己动手实现爬虫scrapy框架思路汇总
这里先简要温习下爬虫实际操作: cd ~/Desktop/spider scrapy startproject lastspider # 创建爬虫工程 cd lastspider/ # 进入工程 sc ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- 爬虫--Scrapy框架的基本使用
流程框架 安装Scrapy: (1)在pycharm里直接就可以进行安装Scrapy (2)若在conda里安装scrapy,需要进入cmd里输入指令conda install scrapy ...
- Python网咯爬虫 — Scrapy框架应用
Scrapy框架 Scrapy是一个高级的爬虫框架,它不仅包括了爬虫的特征,还可以方便地将爬虫数据保存到CSV.Json等文件中. Scrapy用途广泛,可以用于数据挖掘.监测 ...
随机推荐
- 设置Linux环境变量的方法和区别_Ubuntu
设置 Linux 环境变量可以通过 export 实现,也可以通过修改几个文件来实现,有必要弄清楚这两种方法以及这几个文件的区别. 通过文件设置 Linux 环境变量 首先是设置全局环境变量,对所有用 ...
- C3P0连接池温习1
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- 网络协议与OSI体系结构
网络协议与网络体系结构 一.网络协议的概念 1.含义: 网络协议是计算机间进行通信时遵循的一些约定和规则 2.三要素: (1)语法:用于确定协议元素的格式,即数据与控制信息的结构 (2)语义:用于确定 ...
- python while and for
一.while循环 1.格式: while 条件: while循环体 else: 循环正常跳出执行的语句 2.实例: index= : : break #直接跳出while ,不会执行else els ...
- Linux /var/log下的各种日志文件详解
1)/var/log/secure:记录登录系统存取数据的文件;例如:pop3,ssh,telnet,ftp等都会记录在此. 2)/var/log/wtmp:记录登录这的信息记录,被编码过,所以必须以 ...
- 一个特别好用的属性:inline-block
说起inline-block,大家都不陌生,如果我要保证:有一个内联元素,保证它换行时,不被截断,而要整体换行,那么设置:display:inline-block 即可
- Java面试知识点之计算机网络篇(一)
前言:在Java面试中,计算机网络的知识也是一项重点,因此笔者在此对计算机网络的相关知识进行总结. 1.OSI参考模型 自下而上:物理层(物理介质,比特流).数据链路层(网卡.交换机).网络层(IP协 ...
- 设计模式のPrototypePattern(原型模式)----创建模式
一.产生的背景 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆.当直接创建对象的代价比较大时,则采用这种模式.例如,一个对象需要在一个高代价的数据库操作之后被创建.我们可以缓存该对象,在下 ...
- kafka环境搭建测试
一.安装 1. 下载:去kafka官网下载:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.1/kafka_2.11-0.9.0.1.t ...
- 在 PHP 7 中不要做的 10 件事
在 PHP 7 中不要做的 10 件事 1. 不要使用 mysql_ 函数 这一天终于来了,从此你不仅仅“不应该”使用mysql_函数.PHP 7 已经把它们从核心中全部移除了,也就是说你需要迁移到好 ...