机器学习笔记-----AP(affinity propagat)算法讲解及matlab实现
大家好,我是人见人爱,花见花开的小花。哈哈~~!
在统计和数据挖掘中,亲和传播(AP)是基于数据点之间"消息传递"概念的聚类算法。与诸如k-means或k-medoids的聚类算法不同,亲和传播不需要在运行算法之前确定或估计聚类的数量。 类似于k-medoids,亲和力传播算法发现"样本",输入集合的成员,输出聚类结果。
一 算法描述
2.1基本介绍
我们让(x1,…xn)作为一系列的数据点,然后用矩阵S代表各个数据点之间的相似度,一般相似度的判断有欧氏距离,马氏距离,汉明距离。如果S(i,k)>S(i,j)则表示i到k的距离比i到j的距离近。其中S(k,k)表示节点k作为k的聚类中心的合适程度,可以理解为,节点k成为聚类中心合适度,在最开始时,这个值是初始化的时候使用者给定的值,会影响到最后聚类的数量。
这个算法通过迭代两个消息传递步骤来进行,以更新下面两个矩阵:
代表(Responsibility)矩阵R:r(i,k)表示第k个样本适合作为第i个样本的类代表点的代表程度。说白了K为男人,i为女人,代表矩阵R表示,这个男人成为i这个女人老公的适合程度。
适选(Availabilities)矩阵A=[a(i,k)]N×N:a(i,k)表示第i个样本选择第k个样本作为类代表样本的适合程度,同理表示i选择K作为自己老公的可能性。当然,这个社会是相对于封建社会有点进步的,比如也会征求女方的意见,但是又有一定弊端,这个男人K可以三妻四妾。所以K这个聚类中心,周围可以有许多样本i。所以有的人叫R矩阵为吸引度矩阵,矩阵A为归属度矩阵也是不无道理的。
2.2 算法的迭代公式

对于代表矩阵r:
假设现在有一个聚类中心K,我们找到另外一个假想的聚类中心k',重新定义K'的代表矩阵和适合矩阵: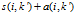 ,找出这两个值相加最大的那一个,在用我们的
,找出这两个值相加最大的那一个,在用我们的 减去这个最大的,就表示这个K的聚类中心对i这个样本的吸引程度。你想想,最大情敌的吸引力都没有我高,那我岂不是最牛叉???
减去这个最大的,就表示这个K的聚类中心对i这个样本的吸引程度。你想想,最大情敌的吸引力都没有我高,那我岂不是最牛叉???
对于适合矩阵a:
我们要明白一个道理,如果一个男人对大部分女人的吸引力都很大,那么这个男人对你这个女人的吸引力的可能性是不是比别人大一点?明白了这个道理。同理如果节点k作为其他节点i'的聚类中心的合适度很大,那么节点k作为节点i的聚类中心的合适度也可能会较大,由此就可以先计算节点k对其他节点的吸引度,r(i',k),然后做一个累加和表示节点k对其他节点的吸引度,得到: 。等等r(k,k)是什么意思呢,一般帅的人是不是都是特别容易自恋?你懂得,所以这个表示样本选择自己作为聚类中心的自恋程度。为了不让这个值过大,影响整体结果,将这个值控制在0以下。当i=k的时候我们选
。等等r(k,k)是什么意思呢,一般帅的人是不是都是特别容易自恋?你懂得,所以这个表示样本选择自己作为聚类中心的自恋程度。为了不让这个值过大,影响整体结果,将这个值控制在0以下。当i=k的时候我们选 就可以了。a(k,k)表示K这个作为聚类中心的能力。
就可以了。a(k,k)表示K这个作为聚类中心的能力。
注意有时候为了防止参数更新时的震动需要引入一个减震参数damping。Damping计算如下:

二 算法实现
function idx = AP(S)
N = size(s,1);
A=zeros(N,N);
R=zeros(N,N); % Initialize messages
lam=0.9; % Set damping factor
same_time = -1;
for iter=1:10000
% Compute responsibilities
Rold=R;
AS=A+S;
[Y,I]=max(AS,[],2);
for i=1:N
AS(i,I(i))=-1000;
end
[Y2,I2]=max(AS,[],2);
R=S-repmat(Y,[1,N]);
for i=1:N
R(i,I(i))=S(i,I(i))-Y2(i);
end
R=(1-lam)*R+lam*Rold; % Dampen responsibilities
% Compute availabilities
Aold=A;
Rp=max(R,0);
for k=1:N
Rp(k,k)=R(k,k);
end
A=repmat(sum(Rp,1),[N,1])-Rp;
dA=diag(A);
A=min(A,0);
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; % Dampen availabilities
if(same_time == -1)
E=R+A;
[tt idx_old] = max(E,[],2);
same_time = 0;
else
E=R+A;
[tt idx] = max(E,[],2);
if(sum(abs(idx_old-idx)) == 0)
same_time = same_time + 1;
if(same_time == 10)
iter
break;
end
end
idx_old = idx;
end
end
E=R+A;
[tt idx] = max(E,[],2);
% figure;
% for i=unique(idx)'
% ii=find(idx==i);
% h=plot(x(ii),y(ii),'o');
% hold on;
% col=rand(1,3);
% set(h,'Color',col,'MarkerFaceColor',col);
% xi1=x(i)*ones(size(ii)); xi2=y(i)*ones(size(ii));
% line([x(ii)',xi1]',[y(ii)',xi2]','Color',col);
% end;
总结:算法讲解部分到这里结束了。谢谢大家,能否走一波关注?哈哈
机器学习笔记-----AP(affinity propagat)算法讲解及matlab实现的更多相关文章
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 吴恩达机器学习笔记58-协同过滤算法(Collaborative Filtering Algorithm)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征. 但是如果我们既没有用户的参数, ...
- 吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征: 异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
- 机器学习笔记(五) K-近邻算法
K-近邻算法 (一)定义:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别. (二)相似的样本,特征之间的值应该是相近的,使用k-近邻算法需要做标准化处理.否 ...
- [吴恩达机器学习笔记]14降维3-4PCA算法原理
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.3主成分分析原理Proncipal Component Analysis Problem Formulation 主成分分析( ...
- 机器学习笔记—混合高斯和 EM 算法
本文介绍密度估计的 EM(Expectation-Maximization,期望最大). 假设有 {x(1),...,x(m)},因为是无监督学习算法,所以没有 y(i). 我们通过指定联合分布 p( ...
- [机器学习笔记]kNN进邻算法
K-近邻算法 一.算法概述 (1)采用测量不同特征值之间的距离方法进行分类 优点: 精度高.对异常值不敏感.无数据输入假定. 缺点: 计算复杂度高.空间复杂度高. (2)KNN模型的三个要素 kNN算 ...
随机推荐
- Java中json的构造和解析
什么是 Json? JSON(JvaScript Object Notation)(官网网站:http://www.json.org/)是 一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机 ...
- 让OData和NHibernate结合进行动态查询
OData是一个非常灵活的RESTful API,如果要做出强大的查询API,那么OData就强烈推荐了.http://www.odata.org/ OData的特点就是可以根据传入参数动态生成Ent ...
- 使用 python 管理 mysql 开发工具箱 - 1
Mysql 是一个比较优秀的开源的数据库,很多公司都在使用.作为运维人员,经常做着一些重复性的工作,比如创建数据库实例,数据库备份等,完全都可以使用 python 编写一个工具来实现. 一.模块 Co ...
- 配置WinRM的Https
1. 打开IIS管理器,选中IIS服务根节点,然后在主内容页选中IIS条目下的服务器证书双击: 2. 在新出现的服务器证书面板下点右边一列的创建自签名证书 3. 证书名称是:名称(这里强调一下,证书的 ...
- Unity中使用Attribute
Attribute是c#的语言特性 msdn说明如下: The Attribute class associates predefined system information or user-def ...
- hibernate学习-HibernateDemo
上篇文章我们讲述了eclipse安装hibernate插件的过程,这篇文章我们来做第一个HibernateDemo. 1).hibernate的jar开发包的下载,官网下载地址:http://hibe ...
- Python Socket 网络编程
Socket 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于 Socket 来完成通信的,例如我们每天浏览网页.QQ ...
- 【python之路1】python安装与环境变量配置
直接搜索 Python,进入官网,找到下载,根据个人电脑操作系统下载相应的软件.小编的是windows os .下载python-2.7.9.msi 安装包 双击安装程序,进入安装步骤.在安装过程中 ...
- [No000099]软件版本命名规范
软件版本阶段说明 Base: 此版本表示该软件仅仅是一个假页面链接,通常包括所有的功能和页面布局,但是页面中的功能都没有做完整的实现,只是做为整体网站的一个基础架构. Alpha: 此版本表示该软件在 ...
- ngx_http_uwsgi_module模块.md
ngx_http_uwsgi_module ngx_http_uwsgi_module模块允许将请求传递到uwsgi服务器. 示例配置: location / { include uwsgi_para ...