机器学习笔记—混合高斯和 EM 算法
本文介绍密度估计的 EM(Expectation-Maximization,期望最大)。
假设有 {x(1),...,x(m)},因为是无监督学习算法,所以没有 y(i)。
我们通过指定联合分布 p(x(i),z(i))=p(x(i)|z(i))p(z(i)) 来对数据建模。这里 z(i)~Multinomial(Φ),其中 Φj≥0,Φ1+Φ2+...+Φk=1,参数 Φj 给定 p(z(i)=j),x(i)|z(i)=j~N(μj,∑j)。k 表示 z(i) 能取的值的个数,所以,通过从 {1,...,k} 中随机选择 z(i),x(i) 从 k 个依赖于 z(i) 的高斯中生成。这就是高斯混合模型。z(i) 是隐随机变量,它们是隐藏的,这增大了估计问题的难度。
模型的参数是 Φ,μ 和 ∑,为对它们做估计,数据的似然为:
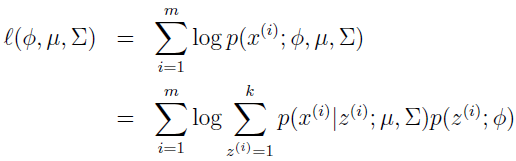
如果通过对参数求导并设为 0 来解,会发现不可能在封闭形式中找到最大似然估计。
随机变量 z(i) 表示 x(i) 来自 k 个高斯分布中的哪一个,如果知道 z(i) 的值,最大似然估计问题就简单了

最大化后参数为:
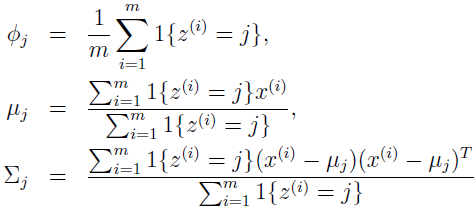 可以看到,如果知道 z(i),最大似然估计就跟高斯判别分析模型的参数估计差不多,除了 z(i) 扮演类标识的角色。
可以看到,如果知道 z(i),最大似然估计就跟高斯判别分析模型的参数估计差不多,除了 z(i) 扮演类标识的角色。
尽管如此,在我们的密度估计问题中,z(i) 是未知的,怎么办?
EM 算法是一个迭代算法,主要分两步:在 E 步,猜测 z(i) 的值;在 M 步,基于猜测更新模型的参数。因为在 M 步假装第一步是正确的,最大化就变简单了。这是算法:


在 E 步,给定 x(i),使用当前参数,用贝叶斯规则计算 z(i) 的后验概率。
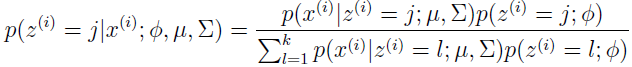
其中 p(x(i)|z(i)=j;μ;∑) 是由 x(i) 的以 μj 为均值和 ∑j 为方差的高斯密度估计出来的;p(z(i)=j;Φ) 是由 Φj 给定的。在 E 步计算的 wj(i) 代表 z(i) 的软估计。
如果拿 M 步的更新同上面 z(i) 已知时的公式做对比,它们是相等的,除了指示函数 I{z(i)=j} 以 wj(i) 代替。
EM 算法会让人想起 K-均值聚类,差别在于硬聚类绑定 c(i) 以软绑定 wj(i) 代替。同 K-均值类似,它也会陷入局部最优,所以多对初始参数赋几次值是个好主意。
很清楚,EM 算法对重复猜测未知 z(i) 有一个非常自然的解释,但它能保证收敛吗?下篇文章将更广地介绍 EM,使我们可以把它应用到其它包含隐变量的估计问题,也会有收敛的证明。
参考资料:
1、http://cs229.stanford.edu/notes/cs229-notes7b.pdf
机器学习笔记—混合高斯和 EM 算法的更多相关文章
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 机器学习(七)EM算法、GMM
一.GMM算法 EM算法实在是难以介绍清楚,因此我们用EM算法的一个特例GMM算法作为引入. 1.GMM算法问题描述 GMM模型称为混合高斯分布,顾名思义,它是由几组分别符合不同参数的高斯分布的数据混 ...
- 【机器学习】GMM和EM算法
机器学习算法-GMM和EM算法 目录 机器学习算法-GMM和EM算法 1. GMM模型 2. GMM模型参数求解 2.1 参数的求解 2.2 参数和的求解 3. GMM算法的实现 3.1 gmm类的定 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 吴恩达机器学习笔记58-协同过滤算法(Collaborative Filtering Algorithm)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征. 但是如果我们既没有用户的参数, ...
- 吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征: 异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
- 机器学习笔记(五) K-近邻算法
K-近邻算法 (一)定义:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别. (二)相似的样本,特征之间的值应该是相近的,使用k-近邻算法需要做标准化处理.否 ...
- [吴恩达机器学习笔记]14降维3-4PCA算法原理
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.3主成分分析原理Proncipal Component Analysis Problem Formulation 主成分分析( ...
随机推荐
- nsq里面WaitGroups两种实用的用法
看过好几遍了,觉得挺实用的,记录备忘一下. 1.开启很多个 goroutine 之后,等待执行完毕 type WaitGroupWrapper struct { sync.WaitGroup } fu ...
- 浅谈pipreqs组件(自动生成需要导入的模块信息)
简介 pipreqs的作用 一起开发项目的时候总是要搭建环境和部署环境的,这个时候必须得有个python第三方包的list,一般都叫做requirements.txt. 如果一个项目使用时virtua ...
- Mybatis框架学习总结-表的关联查询
一对一关联 创建表和数据:创建一张教师表和班级表,这里假设一个老师只负责教一个班,那么老师和班级之间的关系就是一种一对一的关系. CREATE TABLE teacher( t_id INT PRIM ...
- 深入浅出MySQL-DDL语句
DDL语句 DDL是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建.删除.修改等操作的语言.它和DML(数据操纵语言)的最大区别是DML知识对表内部的数据操作,而不涉及表的定义.结构的修 ...
- python web框架 django 工程 创建 目录介绍
# 创建Django工程django-admin startproject [工程名称] 默认创建django 项目都会自带这些东西 django setting 配置文件 django可以配置缓存 ...
- SSH secure shell 原理与运用
转: http://www.ruanyifeng.com/blog/2011/12/ssh_remote_login.html 作者: 阮一峰 日期: 2011年12月21日 SSH是每一台Linux ...
- 解决Centos关闭You have new mail in /var/spool/mail/root提示(转)
今天查看内存的时候 出现一天奇怪的提示 You have new mail in /var/spool/mail/root 有的时候每敲一下回车,就出来You have new mail in /va ...
- grpc入门(三)
grpc入门(三) 一.介绍 本文是关于grpc的第三篇博文,是对前两篇博文的具体代码实现,秉着个人一贯的风格,没有太多抒情和总结,直接就上代码. 文章代码参考:https://github.com/ ...
- centos上传下载文件
1.在windows上安装SecureCRT 2.在centos上安装rzsz软件:yum install lrzsz 3.rz命令上传文件到centos 4.sz命令发送文件到windows
- spring-boot单元测试
一.为什么要写单元测试 很多程序员有两件事情不愿意做: 写注释. 写单元测试. 但是在看代码时又会希望有清晰明了的注释,重构代码时能有一套随时可以跑起来的单元测试. 最近在迁移一个项目,从sqlser ...