集成学习一: Bagging
''团结就是力量''
对问题进行建模时, 算法无论如何优化都无法达到我们的要求,又或者精准算法的实现或调优成本太大, 这时,我们就会想,能不能把几个算法或模型结合起来,以'集体'的力量来解决问题? 这就是集成学习产生的原因.
偏倚与方差
在俱体讲解集成学习之前,先介绍一个概念偏倚-方差.
衡量模型的好坏, 最常用的方法就是其准确性, 拿回归举例, 数据真实值是 y, 而我们应用某一模型预测到的值是 \(\hat{y}\). 那误差率可以很容易的表示成:
\[
\begin{array}\\
E[error] &=& E[(\hat{y} - y)^2]\\
&=& E[(\hat{y} - \bar{y} + \bar{y} - y)^2] \\
&=& E[(\hat{y}-y)^2 -2(\hat{y}-\bar{y})(\bar{y}-y)+(\bar{y}-y)^2]\\
&=& E[(\hat{y}-\bar{y})^2 ]+E[(\bar{y}-y)^2]
\end{array}
\]
其中\(\bar{y}\) 是 \(\hat{y}\) 的期望, 前一项是预测值与期望的差别, 即方差(variance), 后一项是预测期望与真实值的差别, 即偏差(bias 或\(bias^2\)定义不同而已). 这就是所谓的偏倚-方差分解(Bias-variance decomposition, BVD).
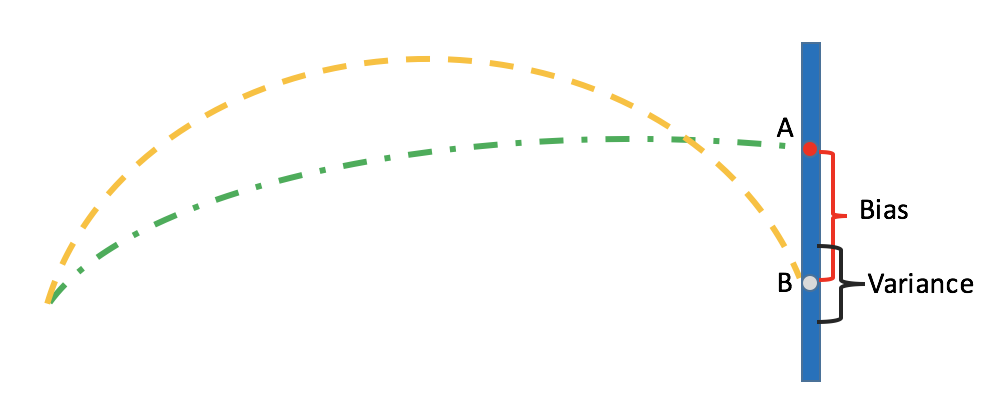
如上图示, 比如靶点在 A 位置, 可是某人的射击落点却总在B点附近, 这时B点可以当作是此人的射击位置期望, BVD中的偏倚与方差如图标示.
因此误差率可表示为:
\[
error = b + v+ \epsilon^2
\]
其中\(\epsilon\) 是噪声.
机器学习的优化, 无非是优化V, D 或者二者. 集成学习主要有两种思路, 一种是Bagging, 一种是boosting, 本质上是对V, D的不同优化方式.
本文来主要介绍下Bagging.
Bagging
Bagging 是并行式集成学习, 也可以说是投票式(voting)式学习. 以少数服从多数的原则来进行表决.
Bagging 是基于自助采样法(bootstrap samplinhg), 是bootstrap aggregating 的合成词.
Bagging算法有两个关键点, 一是自助采样, 二是投票.
自助采样
Bagging是多个学习器组合的集成学习, 每个学习器(称为基学习器) 都要独立训练, 每个基学习器的输入数据是有放回的从样本中抽取子样本(subsampling), 数量一般要求同原样本的数据量(个数) 一致.(ps: 每个个体被抽到的概率是\(1 - (1-\frac{1}{n})^n \approx 63.2\%\))
投票
当每个基学习器训练完成后,对每个个体进行(民主)投票表决, 比如分类, 得票最多的类别即为此个体的类别.
随机森林
随机森林(Random Forest) 也是Bagging 方式, 并且对其进行了改进: 不但对样本进行 subsampling(也称为row subsampling), 而且也对属性进行subsample( 也称column subsampling).
另外提一点的是, 虽然随机森经常以决策树作为基学习器,但从其建模过程来看, 并不局限于此,也就是其他算法作为基分类器也是允许的.
从BVD的角度, bagging 优化的是Variance, 即尽可能的使模型的方差减小, 以达到一个可接受的泛化能力.
参考文献:
- 机器学习, 2016, 周志华, 清华大学出版社
- 数据挖掘,2011, Pang-Ning Tan et al, 范明等译, 人民邮电出版社.
集成学习一: Bagging的更多相关文章
- [白话解析] 通俗解析集成学习之bagging,boosting & 随机森林
[白话解析] 通俗解析集成学习之bagging,boosting & 随机森林 0x00 摘要 本文将尽量使用通俗易懂的方式,尽可能不涉及数学公式,而是从整体的思路上来看,运用感性直觉的思考来 ...
- 机器学习:集成学习(Bagging、Pasting)
一.集成学习算法的问题 可参考:模型集成(Enxemble) 博主:独孤呆博 思路:集成多个算法,让不同的算法对同一组数据进行分析,得到结果,最终投票决定各个算法公认的最好的结果: 弊端:虽然有很多机 ...
- 机器学习回顾篇(12):集成学习之Bagging与随机森林
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 机器学习——集成学习之Bagging
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 随机森林 1.随机森林 ...
- bagging与boosting集成学习、随机森林
主要内容: 一.bagging.boosting集成学习 二.随机森林 一.bagging.boosting集成学习 1.bagging: 从原始样本集中独立地进行k轮抽取,生成训练集.每轮从原始样本 ...
- 集成学习的不二法门bagging、boosting和三大法宝<结合策略>平均法,投票法和学习法(stacking)
单个学习器要么容易欠拟合要么容易过拟合,为了获得泛化性能优良的学习器,可以训练多个个体学习器,通过一定的结合策略,最终形成一个强学习器.这种集成多个个体学习器的方法称为集成学习(ensemble le ...
- 秦曾昌人工智能课程---7、决策树集成学习Tree Ensembles
秦曾昌人工智能课程---7.决策树集成学习Tree Ensembles 一.总结 一句话总结: 其实机器模型减少variance的比较好的方式就是 多个模型取平均值 1.CART是什么? classi ...
- 机器学习回顾篇(13):集成学习之AdaBoost
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
随机推荐
- 3、Ansible playbooks(Hosts、Users、tasks、handlers、变量、条件测试(when、迭代)、templates)
Ansible playbooks playbook是由一个或多个“play”组成的列表.play的主要功能在于将事先归并为一组的主机装扮成事先通过ansible中的task定义好的角色.从根本上来讲 ...
- BZOJ 1061: [Noi2008]志愿者招募(线性规划与网络流)
http://www.lydsy.com/JudgeOnline/problem.php?id=1061 题意: 思路: 直接放上大神的建模过程!!!(https://www.byvoid.com/z ...
- PHP变量的值类型和引用类型
PHP 变量在内存中保存的并不直接是值的内容而是值的地址.比如: $a = 1; 从表面上看起来似乎是 $a 直接存储了 1 这个值.但是实际情况是,PHP 解释器创建了变量 $a , 将值 1 存入 ...
- 最受欢迎的前端框架 —— Bootstrap学习
Bootstrap是Twitter的Mark Otto和Jacob Thornton开发的,是目前最受欢迎的前端框架,它简单灵活,使得Web前端开发更加快捷方便. 首先,要基本掌握Bootstrap框 ...
- HashMap的实现原理-----哈希讲解
哈希,英文名Hash.他就像是一个隔壁家的孩子一样,伴随着码工们的成长.听到他们的名字,我们都觉得很高大上. 在写程序的时候,一般我们都是这样被教育的:这个事情搞不定?用哈希呀! 在面试的时候,一般是 ...
- 《Linux命令行与shell脚本编程大全》读书笔记
第一章:初识Linux 1.linux可划分为四个部分:内核.GNU工具.图形化桌面环境.应用程序 2.内核主要负责:系统内存管理.软件程序管理.硬件设备管理.文件系统管理 3.内核的系统内存管理,有 ...
- art-template
art-template 输出 标准语法 {{value}} {{data.key}} {{data['key']}} {{a ? b : c}} {{a || b}} {{a + b}} 原始语法 ...
- django人类可读性
一些Django的‘奇技淫巧’就存在于这些不起眼的地方. 为了提高模板系统对人类的友好性,Django在django.contrib.humanize中提供了一系列的模板过滤器,有助于为数据展示添加“ ...
- 书法字帖 PDF转化为可打印PDF
书法类的PDF,因为底色是黑色的,打印起来特别费墨,所以需要转化成白底黑字的文件, 才好打印. 1)用 pdfbox 的 ExtractImages 命令,抽出所有的图片 https://pdfbox ...
- ADO.NET梳理
目录: 简单的介绍下ADO.NET SqlConnection(连接对象) SqlCommand(命令对象) SqlParameter(Sql参数) SqlDataReader(数据流读取器) Sql ...