机器学习:集成学习(Bagging、Pasting)
一、集成学习算法的问题
- 可参考:模型集成(Enxemble)
- 博主:独孤呆博
- 思路:集成多个算法,让不同的算法对同一组数据进行分析,得到结果,最终投票决定各个算法公认的最好的结果;
- 弊端:虽然有很多机器学习的算法,但是从投票的角度看,仍然不够多;如果想要有效果更好的投票结果,最好有更多的算法参与;(概率论中称大数定理)
- 方案:创建更多的子模型,集成更多的子模型的意见;
- 子模型之间要有差异,不能一致;
二、如何创建具有差异的子模型
1)创建思路、子模型特点
- 思路:每个子模型只使用样本数据的一部分;(也就是说,如果一共有 500 个样本数据,每个子模型只看 100 个样本数据,每个子模型都使用同一个算法)
- 特点
- 由于将样本数据平分成 5 份,每份 100 个样本数据,每份样本数据之间有差异,因此所训练出的 5 个子模型之间也存在差异;
- 5 个子模型的准确率低于使用全部样本数据所训练出的模型的准确率;
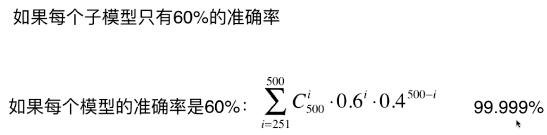
- 实际应用中,每个子模型的准确率有高有低,甚至有些子模型的准确率低于 50%;
- 集成的众多模型中,并不要求子模型有更高的准确率,只要子模型的准确率大于 50%,在集成的模型当中,随着子模型数量的增加,集成学习的整体的准确率升高;
原因分析见下图:

2)怎么分解样本数据给每个子模型?
- 放回取样(Bagging)
- 每个子模型从所有的样本数据中随机抽取一定数量的样本,训练完成后将数据放回样本数据中,下个子模型再从所有的样本数据中随机抽取同样数量的子模型;
- 机器学习领域,放回取样称为 Bagging;统计学中,放回取样称为 bootstrap;
- 不放回取样(Pasting)
- 500 个样本数据,第一个子模型从 500 个样本数据中随机抽取 100 个样本,第二个子模型从剩余的 400 个样本中再随机抽取 100 个样本;
- 通常采用 Bagging 的方式
原因:
- 可以训练更多的子模型,不受样本数据量的限制;
- 在 train_test_split 时,不那么强烈的依赖随机;而 Pasting 的方式,会首随机的影响;
- Pasting 的随机问题:Pasting 的方式等同于将 500 个样本分成 5 份,每份 100 个样本,怎么分,将对子模型有较大影响,进而对集成系统的准确率有较大影响;
3)实例创建子模型
- scikit-learn 中默认使用 Bagging 的方式生成子模型;
模拟数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
使用 Bagging 取样方式,决策树算法 DecisionTreeClassifier 集成 500 个子模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500, max_samples=200,
bootstrap=True) bagging_clf.fit(X_train, y_train)
bagging_clf.score(X_test, y_test)
# 准确率:0.904BaggingClassifier() 的参数:
- DecisionTreeClassifier():表示需要根据什么算法生产子模型;
- n_estimators=500:集成 500 个子模型;
- max_samples=100:每个子模型看 100 个样本数据;
- bootstrap=True:表示采用 Bagging 的方式从样本数据中取样;(默认方式)
- bootstrap=False:表示采用 Pasting 的方式从样本数据中取样;
三、其它
老师指点:
- 机器学习的过程没有一定之规,没有soft永远比hard好的结论(如果是那样,我们实现的接口就根本不需要hard这个选项了;
- 并不是说子模型数量永远越多越好,一切都要根据数据而定,对于一组具体的数据,如论是soft还是hard,亦或是子模型数量,都是超参数,在实际情况都需要根据数据进行一定的调节。
- 在机器学习的世界里,在训练阶段,并不是准确率越高越好。因为准确率高有可能是过拟合。应该是“越真实越好”。
- 所谓的真实是指结果要能“真实”的反应训练数据和结果输出的关系。
- 在真实的数据中,使用验证数据集是很重要的:)
机器学习:集成学习(Bagging、Pasting)的更多相关文章
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 机器学习基础—集成学习Bagging 和 Boosting
集成学习 就是不断的通过数据子集形成新的规则,然后将这些规则合并.bagging和boosting都属于集成学习.集成学习的核心思想是通过训练形成多个分类器,然后将这些分类器进行组合. 所以归结为(1 ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
随机推荐
- Pytorch的gather用法理解
先放一张表,可以看成是二维数组 行(列)索引 索引0 索引1 索引2 索引3 索引0 0 1 2 3 索引1 4 5 6 7 索引2 8 9 10 11 索引3 12 13 14 15 看一下下面例子 ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- 添加nginx服务到service的过程
Linux命令service - 系统服务管理(转) 用途说明 service命令用于对系统服务进行管理,比如启动(start).停止(stop).重启(restart).查看状态(status)等. ...
- HIVE 配置文件详解
hive的配置: hive.ddl.output.format:hive的ddl语句的输出格式,默认是text,纯文本,还有json格式,这个是0.90以后才出的新配置: hive.exec.scri ...
- SoapUI使用方法-01发送http请求
soap ui http://blog.csdn.net/russ44/article/details/51680083 一.发送HTTP请求消息 1.打开soapUI. 2.新建一个项目,实例如下: ...
- 透透彻彻IoC
本文转载自:http://stamen.iteye.com/blog/1489223/ 引述:IoC(控制反转:Inverse of Control)是Spring容器的内核,AOP.声明式事务等功能 ...
- Eureka、Ribbon、Feign常见问题及解决
1.Eureka常见问 1.1.Eureka Enviroment 的配置 eureka.enviroment=product 参考 https://github.com/Netflix/eureka ...
- LightOJ 1038 概率dp
题意:给一个数n,每次除它的一个因子(等概率),问除到1的次数的期望是多少 题解:概率dp,对于一个数x,y是x的因子个数,因子是a1到ay,E(x)=(E(a1)+1)/y+...+(E(ay)+1 ...
- hdu6237 分解质因子
题意:给一堆石子,每次移动一颗到另一堆,要求最小次数使得,所有石子数gcd>1 题解:枚举所有质因子,然后找次数最小的那一个,统计次数时,我们可以事先记录下每堆石子余质因子 的和,对所有石子取余 ...
- mac实用脚本
安全清倒废纸篓(AppleScript) on run {input, parameters} set title to "安全清倒废纸篓" set trashIsEmptyMes ...