word2vector 使用方法 计算语义相似度
参考:http://techblog.youdao.com/?p=915#LinkTarget_699
word2vector是一个把词转换成词向量的一个程序,能够把词映射到K维向量空间,甚至词与词之间 的向量操作还能和语义相对应。如果换个思路,把词当做feature,那么word2vec就可以把feature映射到K维向量空间,一、什么是 word2vec?
采用的模型有 CBOW(Continuous Bag-Of-Words,即连续的词袋模型)和 Skip-Gram 两种
word2vec 通过训练,可以把对文本内容的处理简化为 K 维向量空间中的向量 运算,而向量空间上的相似度可以用来表示文本语义上的相似度。
。因此,word2vec 输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分 析等等
二、快速入门
简单介绍cmake makefile.txt → makefile make的关系
首先编写一个与平台无关的CMakelist.txt文本文件,这个文本文件是为了制定整个编译流程,然后通过cmake path(makelist.txt所在位置,在这个目录下就是 dian .) 生成本地化的Makefile文件 ,最后make 编译文件
总的来说就是
- 编写cmakelist.txt(跨平台的文件来制定整个编译流程)
- cmake .生成本地化的makefile
- make 编译 word2vec 工具
然后你想运行***脚本就sh ***.sh
demo-word.sh 中的代码如下,
主要工作为:
1) 编译(make)
2) 下载训练数据 text8,如果不存在。text8 中为一些空格隔开的英文单 词,但不含标点符号,一共有 1600 多万个单词。
3) 训练,大概一个小时左右,取决于机器配置
4) 调用 distance,查找最近的词
上github下载之后,打开文件夹你能看到很多.sh的脚本
这时候除了开心就是开心
因为运行脚本就ok了
首先敲入 make (由于有makefile文件直接这样就可以了 更何况没有makelist.txt cmake 也没有用)
简单介绍cmake makefile.txt → makefile make的关系
首先编写一个与平台无关的CMakelist.txt文本文件,这个文本文件是为了制定整个编译流程,然后通过cmake path(makelist.txt所在位置,在这个目录下就是 dian .) 生成本地化的Makefile文件 ,最后make 编译文件
总的来说就是
- 编写cmakelist.txt(跨平台的文件来制定整个编译流程)
- cmake .生成本地化的makefile
- make
然后你想运行***脚本就sh ***.sh
比如说我想知道一个词与谁的距离最近
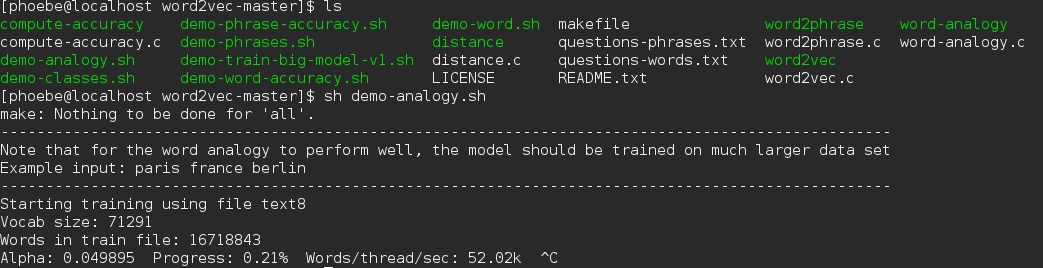
这个脚本里的内容首先会检查你有没有test8这个训练语料
如果没有它会自动下载,
下载之后就开始训练了
之后你可以输入三个单词
paris france berlin(分开的)
之后你会看到Germany出现在第一个位置
如果你不想运行脚本你也可以直接执行可执行的程序 比如:你可以在vectors.txt看到test8中的词转成了50维的词向量
nohup ./word2vec -train text8 -output vectors.txt -cbow 1 -size 50 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -iter 1 > test.log 2>&1 &
总之一句话,认真看脚本。。。。
word2vector 使用方法 计算语义相似度的更多相关文章
- 2017年计算语义相似度最新论文,击败了siamese lstm,非监督学习
Page 1Published as a conference paper at ICLR 2017AS IMPLE BUT T OUGH - TO -B EAT B ASELINE FOR S EN ...
- 深度学习解决NLP问题:语义相似度计算
在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度.feeds场景下Doc和Doc的语义相似度.机器翻译场景下A句子和B句子的语义相似度等等.本文通过介绍DSSM.C ...
- DSSM算法-计算文本相似度
转载请注明出处: http://blog.csdn.net/u013074302/article/details/76422551 导语 在NLP领域,语义相似度的计算一直是个难题:搜索场景下quer ...
- NLP 语义相似度计算 整理总结
更新中 最近更新时间: 2019-12-02 16:11:11 写在前面: 本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学.写得不 ...
- 用BERT做语义相似度匹配任务:计算相似度的方式
1. 自然地使用[CLS] 2. cosine similairity 3. 长短文本的区别 4. sentence/word embedding 5. siamese network 方式 1. 自 ...
- 基于熵的方法计算query与docs相似度
一.简单总结 其实相似度计算方法也是老生常谈,比如常用的有: 1.常规方法 a.编辑距离 b.Jaccard c.余弦距离 d.曼哈顿距离 e.欧氏距离 f.皮尔逊相关系数 2.语义方法 a.LSA ...
- BERT实现QA中的问句语义相似度计算
1. BERT 语义相似度 BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双 ...
- 孪生网络(Siamese Network)在句子语义相似度计算中的应用
1,概述 在NLP中孪生网络基本是用来计算句子间的语义相似度的.其结构如下 在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼 ...
- 使用并行的方法计算斐波那契数列 (Fibonacci)
更新:我的同事Terry告诉我有一种矩阵运算的方式计算斐波那契数列,更适于并行.他还提供了利用TBB的parallel_reduce模板计算斐波那契数列的代码(在TBB示例代码的基础上修改得来,比原始 ...
随机推荐
- ntopng基础
当你在本地网络监控网络流量,根据流量大小.监控平台/接口.数据库类型等等,可以有许多不同的选择.ntopng是一套开源(遵循GPLv3协议)网络流量分析解决方案,提供基于web界面的实时网络流量监控. ...
- Shiro-Base64加密解密,Md5加密
Shiro权限框架中自带的加密方式有Base64加密,MD5加密 在Maven项目的pom.xml中添加shiro的依赖: <dependency> <groupId>org. ...
- java.util.Calendar
package day14; import com.sun.scenario.effect.impl.sw.sse.SSEBlend_SRC_OUTPeer; import java.util.Cal ...
- Oracle中查看建立索引和使用索引的注意点
一.查看和建立索引 select * from user_indexes where table_name = 'student' create index i_student_num on stud ...
- 数据分析之可反复与独立样本的T-Test分析
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jia20003/article/details/24201297 数据分析之独立样本的T-Test分 ...
- 创建Java不可变类
不可变(immutable)类的意思是创建该类的实例后,该实例的Field是不可改变的,Java提供的8个包装类和java.lang.String类都是不可变类. 如果需要创建自定义的不可变类,可遵守 ...
- Java游戏服务器成长之路——感悟篇
又是一个美好的周末啊,现在一到周末,早上就起得晚,下午困了又会睡一两个小时,上班的时候,早上起来喝一杯咖啡,然后就能高效的工作一整天,然而到了周末人就懒散了,哈哈. 最近刚跳槽,到新公司已经干了有两周 ...
- python全栈开发从入门到放弃之函数进阶
1.三元运算 a= 1 b=2 max = (a if a>b else b ) #条件成立的结果 if 条件 else 条件不成立的结果 print(max) 2.先上一首python之禅 i ...
- python全栈开发从入门到放弃之面向对象反射
1.classmethod.staticmethod方法 classmethod类方法默认参数cls,可以直接用类名调用,可以与类属性交互 #student文件内容 宝宝,男 博博,女 海娇,男 海燕 ...
- css选择器中间的空格
div p div标签下 的p标签 (后代) div .a div 的后代类属性有a的 div.a 类属性有a的div标签 div.a1.a2 多类选择器 类包含a1,a2的div标签 div.a1 ...