爬虫开发12.selenium在scrapy中的应用
引入
- 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
今日详情
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
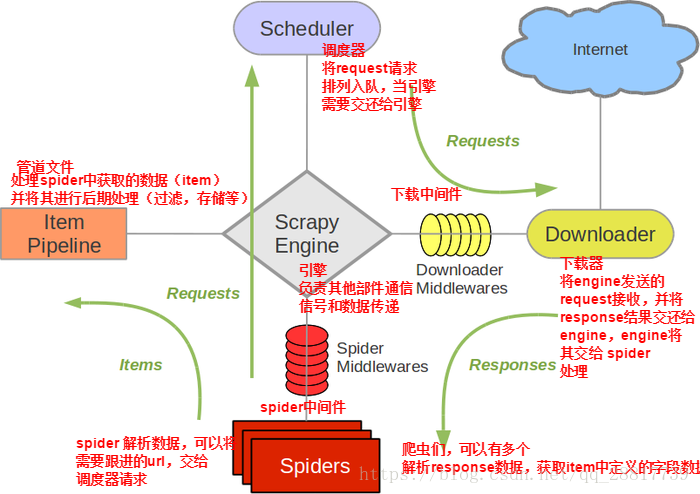
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
#必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}爬虫开发12.selenium在scrapy中的应用的更多相关文章
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 如何优雅的在scrapy中使用selenium —— 在scrapy中实现浏览器池
1 使用 scrapy 做采集实在是爽,但是遇到网站反爬措施做的比较好的就让人头大了.除了硬着头皮上以外,还可以使用爬虫利器 selenium,selenium 因其良好的模拟能力成为爬虫爱(cai) ...
- python网页爬虫开发之六-Selenium使用
chromedriver禁用图片,禁用js,切换UA selenium 模拟chrome浏览器,此时就是一个真实的浏览器,一个浏览器该加载的该渲染的它都加载都渲染,所以爬取网页的速度很慢.如果可以不加 ...
- 爬虫(十一):scrapy中的选择器
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- 爬虫(十三):scrapy中pipeline的用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 京东联盟开发(12)——删除MySQL表中重复记录并且只保留一条
本文介绍如何删除商品表中的一些重复记录. 有时,一条商品由于有多个skuid,比如某种手机有不同颜色,但价格.优惠等信息却是一致,导致其被多次收录.由于其各种条件基本类似,这样它在商品中多个sku都排 ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
随机推荐
- 查看MSSQL数据库每个表占用的空间大小
需要查看数据库表的大小,查询SQL Server联机从书得到如下语句: sp_spaceused 显示行数.保留的磁盘空间以及当前数据库中的表所使用的磁盘空间,或显示由整个数据库保留和使用的磁盘空间. ...
- 88. Merge Sorted Array (Array)
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: Y ...
- Java-Properties文件读取工具类
import org.apache.commons.configuration.ConfigurationException; import org.apache.commons.configurat ...
- centos6.5系统hadoop2.7安装sqoop
一.sqoop简介 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ...
- Oracle-属性查询
1. 查询表的部分字段属性 select t.*, c.comments from user_tab_columns t, user_col_comments c where t.table_name ...
- SQL 数据库 学习 006 如何设置一个用户名和密码
我的电脑系统: Windows 10 64位 使用的SQL Server软件: SQL Server 2014 Express 先启动 SQL Server 2014 Management Studi ...
- A*搜索 概念
启发式搜索:启发式搜索就是在状态空间中的搜索对每一个搜索的位置进行评估,得到最好的位置,再从这个位置进行搜索直到目标.这样可以省略大量无畏的搜索路径,提到了效率.在启发式搜索中,对位置的估价是十分重要 ...
- 协方差与pearson相关系数
协方差 协方差大于0,表示两个随机变量正线性相关 协方差等于0,表示两随机变量无线性相关 协方差小于0,表示两随机变量负线性相关 协方差智能表示随机变量的线性相关关系,不能刻画其相关程度. 因此引入了 ...
- 导入excel精华版
//须引入 NPOI, NPOI.OOXML, NPOI.Openxml4Net, NPOI.OpenxmlFormats等程序集 自己去下载吧 NPOI组件很好用不可能下不到自己去吧,通常去百度网盘 ...
- rocketmq配置项说明(对应版本:4.0.0-incubating)
Broker配置参数说明 自定义客户端行为 ※一些默认配置的源代码路径 org.apache.rocketmq.store.config --END--