Hadoop(4)-Hadoop集群环境搭建
准备工作
开启全部三台虚拟机,确保hadoop100的机器已经配置完成
分发脚本
操作hadoop100

新建一个xsync的脚本文件,将下面的脚本复制进去
vim xsync
#这个脚本使用的是rsync命令而不是scp命令,是同步而非覆盖文件,所以仅仅会同步过去修改的文件.但是rsync并不是一个原生的Linux命令,需要手动安装.如果没有,请自行安装
#!/bin/bash
# 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==)); then
echo no args;
exit;
fi # 获取文件名称
p1=$
fname=`basename $p1`
echo fname=$fname # 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir # 获取当前用户名称
user=`whoami` # 循环
# 101, 103 是机器的ip地址,大家可以根据情况修改
for((host=; host<; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
给xsync文件加可执行权限
chmod +x xsync
将xsync拷贝到 /bin 目录下,以后可以随处使用
sudo cp xsync /bin
运行以下命令,根据提示输入密码,将文件进行拷贝(拷贝前,如果hadoop100的hadoop目录里有 data和logs文件 务必删除掉再同步)
sudo xsync /opt/module/hadoop-2.7.2/ sudo xsync /opt/module/jdk1.8.0_144/
sudo xsync /etc/profile
再在全局会话中,使用source命令
source /etc/profile
至此,虚拟机的环境全部搭建完成,下面进行集群的配置
集群搭建
集群部署规划
|
hadoop100 |
hadoop101 |
hadoop102 |
|
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
hadoop集群至少需要3个replication,再加上一台NameNode,一台ResourceManager,一台SecondaryNameNode,理论上需要6台机器才能搭建一个集群.但是碍于条件有限,混搭成3台机器.每一台机器都是一个DataNode和NodeManager,同时hadoop100为NameNode,hadoop101为ResourceManager,hadoop102为SecondaryNameNode
配置集群
(1)核心配置文件
配置文件全部在 /opt/module/hadoop-2.7.2/etc/hadoop/目录下,先cd进来
配置core-site.xml
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(2)HDFS配置文件
配置hadoop-env.sh
vim hadoop-env.sh 修改JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
sudo vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property> <!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
(3)YARN配置文件
配置yarn-env.sh vim yarn-env.sh export JAVA_HOME=/opt/module/jdk1..0_144
配置yarn-site.xml vim yarn-site.xml 在该文件中增加如下配置 <!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(4)MapReduce配置文件
配置mapred-env.sh vim mapred-env.sh export JAVA_HOME=/opt/module/jdk1..0_144
配置mapred-site.xml 首先先cp一份
cp mapred-site.xml.template mapred-site.xml 再编辑
vim mapred-site.xml 在该文件中增加如下配置 <!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
(5)配置slaves
vim slaves 将localhost删除
添加三个子节点主机名
hadoop100
hadoop101
hadoop102 wq保存退出
(5) 在集群上分发配置好的Hadoop文件
xsync /opt/module/hadoop-2.7.2/etc/hadoop
集群启动
格式化Namenode 在hadoop100上 hdfs namenode -format
启动hdfs
start-dfs.sh
启动历史服务器 mr-jobhistory-daemon.sh start historyserver
在Hadoop101上启动Resourcemanager start-yarn.sh
使用jps命令
hadoop100
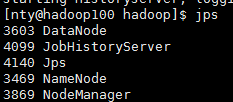
hadoop101

hadoop102

如果集群出了问题,删除每一台机器上的 data logs文件,再重新启动集群
cd $HADOOP_HOME
rm -rf data logs
测试集群
首先去到自己的home里
cd /home/nty mkdir input vim input/input
输入几个词语,我们用hadoop的wordcount方法来测试
将input文件夹传到hadoop上
hadoop fs -put input /
fs 表示操作文件系统
-put 将文件上传到hadoop上
input 本地源文件
/ hadoop的目标地址
上传完后 浏览器打开 http://hadoop100:50070/explorer.html#/

去hadoop的主目录下
cd /opt/module/hadoop-2.7./
运行以下命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /input /output
出现 completed successfully 程序运行成功

运行以下命令,能把词查出来,就说明集群搭建完成并且成功了~

real 开心~~~~
如果还不行,请留言.
Hadoop(4)-Hadoop集群环境搭建的更多相关文章
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- hadoop(八) - hbase集群环境搭建
1. 上传hbase安装包hbase-0.96.2-hadoop2-bin.tar.gz 2. 解压 tar -zxvf hbase-0.96.2-hadoop2-bin.tar.gz -C /clo ...
- Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
随机推荐
- EPS 转 pdf 在线
EPS 转 pdf 在线网站 https://convertio.co/zh/eps-pdf/
- 12C RAC 常用检查命令,持续总结中
grid: olsnodes -s列出集群中节点crsctl check cluster -all检查几圈状态crsctl check clustercrsctl check crs 检查当前节点sr ...
- VS LNK2019 解决办法之一
LNK2019: unresolved external symbol _main referenced in function __main 有人说这是因为静态动态引用引起的,但是!这些都没有解决我 ...
- WCF思考随笔一: WCF是干什么的?
对于WCF,之前知道是微软新一代开发框架的重要组成部分,是从之前Socket,COM,COM+,.NET Remoting,WebService等等系统内或系统间通讯解决方案发展而来,同时对各种解决方 ...
- UESTC 574 High-level ancients
分析: 无论父节点增加了多少,子节点的增量总比父节点多1. 这种差分的关系是保存不变的,我们可以一遍dfs根据结点深度得到在根结点的每个点的系数. 估且把一开始的结点深度称做c0吧,对于子树的修改就只 ...
- Uva 11294 婚姻
题目链接:https://vjudge.net/contest/166461#problem/C 题意: n对夫妻,有m对人吵过架,不能排在同一边,求新娘的一边的人: 分析: 每对夫妻,看成两个点,女 ...
- canvas基本图形
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Android学习笔记_79_ Android 使用 搜索框
1.在资源文件夹下创建xml文件夹,并创建一个searchable.xml: android:searchSuggestAuthorityshux属性的值跟实现SearchRecentSuggesti ...
- HTML5之canvas基本API介绍及应用 1
一.canvas的API: 1.颜色.样式和阴影: 2.线条样式属性和方法: 3.路径方法: 4.转换方法: 5.文本属性和方法: 6.像素操作方法和属性: 7.其他: drawImage:向画布上绘 ...
- c语言描述的二分插入排序法
#include<stdio.h> #include<stdlib.h> //二分插入排序法 void BinsertSort(int a[],int n){ int low, ...