scrapy详细数据流走向(个人总结)
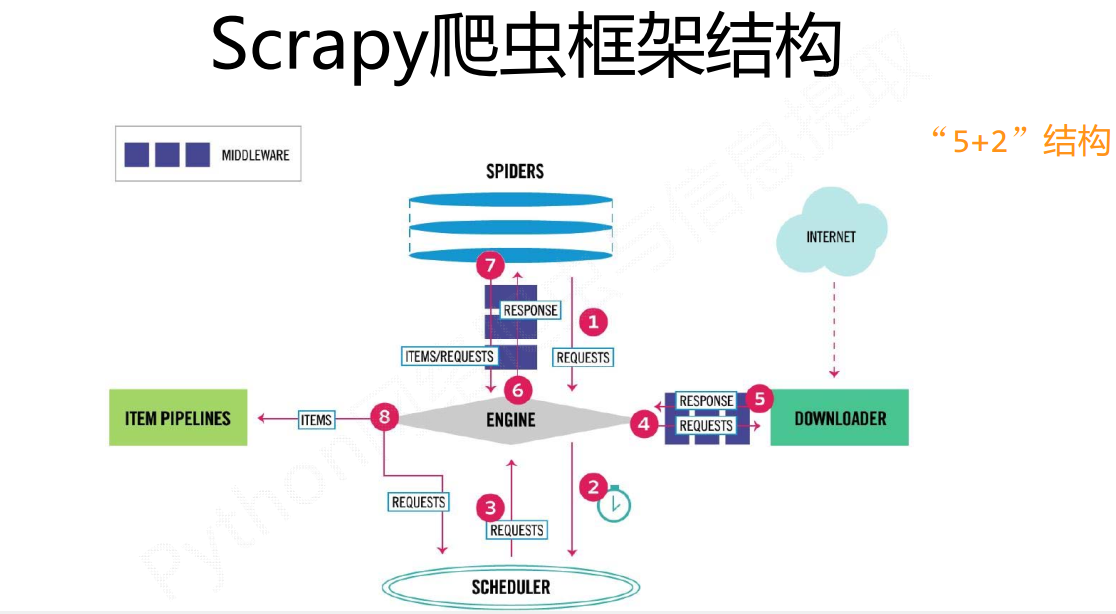
直接从数据流的角度来说比较容易理解:
·1、Spider创建一个初识url请求,把这个请求通过Engine转给Scheduler调度模块。然后Scheduler向Engine提供一个请求(这个请求是一个真实的url请求)
疑问点一:为什么Engine把请求发给Scheduler模块,然后又从Scheduler模块里面取出来,这不是多此一举么,这个Scheduler模块有作用么?
按照我的理解,scrapy把各个组件模块化,就是为了更加方便的配置,当然你把所有模块都写在一起,功能同样可以实现,只不过这就失去了这个框架的价值了,Scheduler就是为了存取请求,而Spider就是解析出新的请求和数据item。
疑问点二:为什么说Scheduler存的是真实的url请求
Spider里面的url不一定是我们需要的url,需要经过解析,生成我们所需要的真实url,然后通过Engine发送给Scheduler
2、第一步Engine已经得到了真实的url地址,然后Engine把这个请求request发送给Downloader模块
tips:我们主要到Engine发送请求给Downloader模块前,需要进过DownloaderMiddleware中间件,实际上这里可以对请求做一些修改,也就是添加User-Agent之类的参数,如果用过requests第三方包应该容易理解
3、Downloader模块把网页下载完成后会把结果返回给Engine
tips:这个过程同样会经过DownloaderMiddleware,所以很容易理解,我们可以在这里修改response相关信息
4、Engine得到数据之后,它会把数据发送给Spider进行解析得到item(数据)或者是request(新的请求)
tips:比如我们本来要获取的是图片信息,在得到的response中发现不止有图片信息(item),还有其他的连接(新的request)
5、Spider解析得到的item和request会有两种走向
a:如果是item,也就是已经得到了数据,那么就通过Engine把item发送到Itempipeline进行处理,这里主要是进行数据的清洗、查重、保存等操作。
b:如果生成的是request,照着之前的,通过Engine把真实请求request发送给Scheduler,然后Engine从Scheduler拿request,发给给Downloader下载,Downloader下载完通过Engine发送给Spider。。如此往复,直到没有新的request请求
有时候看到网上的教程那么长会觉得难,不想去学,真正去学的时候会发现,其实也就那样。好了,关于scrapy的数据流就到这。
scrapy详细数据流走向(个人总结)的更多相关文章
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- 97、爬虫框架scrapy
本篇导航: 介绍与安装 命令行工具 项目结构以及爬虫应用简介 Spiders 其它介绍 爬取亚马逊商品信息 一.介绍与安装 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, ...
- 爬虫框架之Scrapy
一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowloader Middeware ...
- Scrapy学习篇(一)之框架
概览 在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解.下面是scr ...
- 爬虫 之 scrapy框架
浏览目录 介绍 安装 项目结构及爬虫应用简介 常用命令行工具 Spiders爬虫 Selectors选择器 Item Pipeline 项目管道 Downloader Middleware下载中间件 ...
- 爬虫框架scrapy的基本内容
Scrapy介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以帮助用户简单快速的部署一个专业的网络爬虫.如果说前面我们写的定制bs4爬虫是”手动挡“,那Scrapy就相当 ...
- 爬虫之scrapy工作流程
Scrapy是什么? scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容.Scrapy 使用了 Twisted['twɪstɪd] ...
- 九、爬虫框架之Scrapy
爬虫框架之Scrapy 一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowload ...
- 第六篇:Scrapy框架
爬虫框架之Scrapy 一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowload ...
随机推荐
- 【题解】HNOI2008GT考试
这题好难啊……完全不懂矩阵加速递推的我TAT 这道题目要求我们求出不含不吉利数字的字符串总数,那么我们有dp方程 : dp[i][j](长度为 i 的字符串,最长与不吉利数字前缀相同的后缀长度为 j ...
- Codeforces Round #510 (Div. 2) B. Vitamins
B. Vitamins 题目链接:https://codeforces.com/contest/1042/problem/B 题意: 给出几种药,没种可能包含一种或多种(最多三种)维生素,现在问要吃到 ...
- OSI 七层模型和 TCP/IP 四层模型 及 相关网络协议
简介 OSI 是理论上的模型,也就是一个统一的国际标准,现在的很多网络设备或者是网络协议都不同程度的精简了自己的所谓的模型,那么他们为了自己的通讯兼容都会参考这个OSI模型 TCP/IP 包括: TC ...
- Death Note
注:本文系作者原创,但可随意转载. ********************************************************************************** ...
- jquery从零起步学
html: <HTML> <head> <meta http-equiv="content-type" content="text/html ...
- IOS 上传项目到github 终端操作
1.创建github账号 2.创建秘钥 3.Github配置秘钥 4.上传文件 复制保存网址 终端操作,如果没有ssh,自行安装 GitHub配置秘钥 克隆github上创建的项目 将自己的本地项目, ...
- Substrings(hdu 4455)
题意: 给定一个序列ai,个数为n.再给出一系列w:对于每个w,求序列中,所有长度为w的连续子串中的权值和,子串权值为子串中不同数的个数. /* dp[i]表示长度为i的序列不同元素个数之和. 考虑从 ...
- JAVA路线
[转]Java自学之路——by马士兵 作者:马士兵老师 JAVA自学之路 一:学会选择 为了就业,不少同学参加各种各样的培训. 决心做软件的,大多数人选的是java,或是.net,也有一些选择了手机. ...
- 【BZOJ2253】纸箱堆叠 [CDQ分治]
纸箱堆叠 Time Limit: 30 Sec Memory Limit: 256 MB[Submit][Status][Discuss] Description P 工厂是一个生产纸箱的工厂. 纸 ...
- AtCoder Regular Contest 082 E
Problem Statement You are given N points (xi,yi) located on a two-dimensional plane. Consider a subs ...