3.基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf
1.PGD攻击的原理
PGD(Project Gradient Descent)攻击是一种迭代攻击,可以看作是FGSM的翻版——K-FGSM (K表示迭代的次数),大概的思路就是,FGSM是仅仅做一次迭代,走一大步,而PGD是做多次迭代,每次走一小步,每次迭代都会将扰动clip到规定范围内。
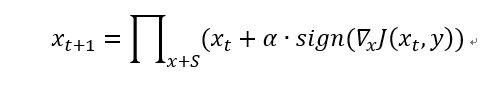
一般来说,PGD的攻击效果比FGSM要好,那么原理是什么呢?首先,如果目标模型是一个线性模型,那么用FGSM就可以了,因为此时loss对输入的导数是固定的,换言之,使得loss下降的方向是明确的,即使你多次迭代,扰动的方向也不会改变。而对于一个非线性模型,仅仅做一次迭代,方向是不一定完全正确的,这也是为什么FGSM的效果一般的原因了。

用画图软件画了一个很丑的图,但大致能够表达我的看法,黑圈是输入样本,假设样本只有两维,那么样本可以改变的就有八个方向,坐标系中显示了loss等高线,以及可以扰动的最大范围(因为是无穷范数,所以限制范围是一个方形,负半轴的范围没有画出来),黑圈每一次改变,都是以最优的方向改变,最后一次由于扰动超出了限制,所以直接截断,如果此时迭代次数没有用完,那么就在截断处继续迭代,直到迭代次数用完。
2.PGD的代码实现
class PGD(nn.Module):
def __init__(self,model):
super().__init__()
self.model=model#必须是pytorch的model
self.device=torch.device("cuda" if (torch.cuda.is_available()) else "cpu")
def generate(self,x,**params):
self.parse_params(**params)
labels=self.y adv_x=self.attack(x,labels)
return adv_x
def parse_params(self,eps=0.3,iter_eps=0.01,nb_iter=40,clip_min=0.0,clip_max=1.0,C=0.0,
y=None,ord=np.inf,rand_init=True,flag_target=False):
self.eps=eps
self.iter_eps=iter_eps
self.nb_iter=nb_iter
self.clip_min=clip_min
self.clip_max=clip_max
self.y=y
self.ord=ord
self.rand_init=rand_init
self.model.to(self.device)
self.flag_target=flag_target
self.C=C def sigle_step_attack(self,x,pertubation,labels):
adv_x=x+pertubation
# get the gradient of x
adv_x=Variable(adv_x)
adv_x.requires_grad = True
loss_func=nn.CrossEntropyLoss()
preds=self.model(adv_x)
if self.flag_target:
loss =-loss_func(preds,labels)
else:
loss=loss_func(preds,labels)
# label_mask=torch_one_hot(labels)
#
# correct_logit=torch.mean(torch.sum(label_mask * preds,dim=1))
# wrong_logit = torch.mean(torch.max((1 - label_mask) * preds, dim=1)[0])
# loss=-F.relu(correct_logit-wrong_logit+self.C) self.model.zero_grad()
loss.backward()
grad=adv_x.grad.data
#get the pertubation of an iter_eps
pertubation=self.iter_eps*np.sign(grad)
adv_x=adv_x.cpu().detach().numpy()+pertubation.cpu().numpy()
x=x.cpu().detach().numpy() pertubation=np.clip(adv_x,self.clip_min,self.clip_max)-x
pertubation=clip_pertubation(pertubation,self.ord,self.eps) return pertubation
def attack(self,x,labels):
labels = labels.to(self.device)
print(self.rand_init)
if self.rand_init:
x_tmp=x+torch.Tensor(np.random.uniform(-self.eps, self.eps, x.shape)).type_as(x).cuda()
else:
x_tmp=x
pertubation=torch.zeros(x.shape).type_as(x).to(self.device)
for i in range(self.nb_iter):
pertubation=self.sigle_step_attack(x_tmp,pertubation=pertubation,labels=labels)
pertubation=torch.Tensor(pertubation).type_as(x).to(self.device)
adv_x=x+pertubation
adv_x=adv_x.cpu().detach().numpy() adv_x=np.clip(adv_x,self.clip_min,self.clip_max) return adv_x
PGD攻击的参数并不多,比较重要的就是下面这几个:
eps: maximum distortion of adversarial example compared to original input
eps_iter: step size for each attack iteration
nb_iter: Number of attack iterations.
我在上面代码中注释的这行代码是CW攻击的PGD形式,这个在防御论文https://arxiv.org/pdf/1706.06083.pdf中有体现,以后说到CW攻击再细说。
# label_mask=torch_one_hot(labels)
#
# correct_logit=torch.mean(torch.sum(label_mask * preds,dim=1))
# wrong_logit = torch.mean(torch.max((1 - label_mask) * preds, dim=1)[0])
# loss=-F.relu(correct_logit-wrong_logit+self.C)
最后再提一点就是,在上面那篇防御论文中也提到了,PGD攻击是最强的一阶攻击,如果防御方法对这个攻击能够有很好的防御效果,那么其他攻击也不在话下了。
2019-03-29 20:43:40
3.基于梯度的攻击——PGD的更多相关文章
- 2 基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf 1.PGD攻击的原理 PGD(Project Gradient Descent)攻击是一种迭代攻击,可 ...
- 2.基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 1 基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 4.基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf 1.MIM攻击的原理 MIM攻击全称是 Momentum Iterative Method,其实这也是 ...
- 3 基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf 1.MIM攻击的原理 MIM攻击全称是 Momentum Iterative Method,其实这也是 ...
- 5.基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- 4 基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- 基于梯度场和Hessian特征值分别获得图像的方向场
一.我们想要求的方向场的定义为: 对于任意一点(x,y),该点的方向可以定义为其所在脊线(或谷线)位置的切线方向与水平轴之间的夹角: 将一条直线顺时针或逆时针旋转 180°,直线的方向保持不变. 因 ...
- C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话: 在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言 原贴地址:https://helloacm.com/cc-linear-regression ...
随机推荐
- 量化交易之下单函数和context对象
一.下单函数 聚宽设计的函数(如前文所说准确叫法是API)的用法都写在API文档里,位置在聚宽网站导航栏-帮助-API文档 1.order按股数下单 order(security, amount, s ...
- P4610 [COCI2011-2012#7] KAMPANJA
题目背景 临近选举,总统要在城市1和城市2举行演讲.他乘汽车完成巡回演讲,从1出发,途中要经过城市2,最后必须回到城市1.特勤局对总统要经过的所有城市监控.为了使得费用最小,必须使得监控的城市最少.求 ...
- mongoDB 小练习
1 创建数据库名为 grade > use grade switched to db grade 2 创建集合 class 3 插入若干数据 格式如下{name:xxx,age:xxx,sex: ...
- Activation HDU - 4089(概率dp)
After 4 years' waiting, the game "Chinese Paladin 5" finally comes out. Tomato is a crazy ...
- 基于Elastalert的安全告警剖析
https://www.freebuf.com/sectool/164591.html *本文作者:bigface,本文属 FreeBuf 原创奖励计划,未经许可禁止转载. elastalert 是一 ...
- 前端ajax请求百度地图api
$.ajax({ type: "get", url: 'http://api.map.baidu.com/place/v2/search', data:{ ak:'您的ak', q ...
- 三步解决fiddler升级后https无法通过证书验证问题
有时候使用fiddler时,https页面会出现错误提示,我们可以这样设置来避免错误 第一步:去掉https的抓取 Tools>Option 去掉Capture HTTPS CONNECTs 的 ...
- IDEA配置注释模板
直接进入主题: Ctrl+Alt+S进入设置界面(我没改过按键映射,你也可以从File-OtherSetting进入设置),找到Editor->File and Code Templates,先 ...
- 基于USB网卡适配器劫持DHCP Server嗅探Windows NTLM Hash密码
catalogue . DHCP.WPAD工作过程 . python Responder . USB host/client adapter(USB Armory): 包含DHCP Server . ...
- [物理学与PDEs]第1章习题15 媒介中电磁场的电磁动量密度向量与电磁动量流密度张量
对媒质中的电磁场, 推导其电磁动量密度向量及电磁动量流密度张量的表达式 (7. 47) 及 (7. 48). 解答: 由 $$\beex \bea \cfrac{\rd}{\rd t}\int_\Om ...