zookeeper之二:zookeeper3.7.0安装过程实操
前面分享了zookeeper的基本知识,下面分享有关zookeeper安装的知识。
1、下载
zookeeper的官网是:https://zookeeper.apache.org/
在官网上找到下载链接,
这里使用的是二进制安装包,使用的是3.7.0的版本。
2、安装
2.1、环境
os:我这里是在虚拟机环境中的centos7-64进行安装。
JDK:zookeeper需要JDK的支持,需要事先配置好java的环境变量。
2.2、安装
zookeeper的安装可以分为单机版和集群版,单机版是只有一个节点,集群版使用三个节点。
2.2.1、单机版
2.2.1.1、修改配置
单机版是只有一个节点的zookeeper进程,把下载好的安装包上传到对应得linux服务器目录上,对文件进行解压,解压后的文件如下,
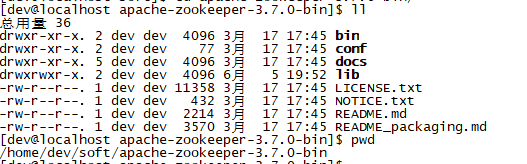
这里有两个比较重要的目录bin和conf,bin目录存放的是zookeeper启动脚本,conf下存放的是配置文件。首先修改配置文件,在conf下有三个文件,

zoo_sample.cfg是一个样例文件,zookeeper启动的时候默认使用的是zoo.cfg,这里从zoo_sample.cfg复制一个名为zoo.cfg即可,然后修改zoo.cfg文件,整个zoo.cfg文件是这样的
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1 ## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
我这里仅修改了下面的配置,
dataDir=/home/dev/datas/zookeeper3.7.0/single
2.2.1.2、启动
在zookeeper的目录下,执行下面的命令
bin/zkServer.sh start
看到下面的内容,说明已经启动成功

2.2.2、集群版
2.2.2.1、修改配置
由于我这里没有多余的物理机,所以在一台虚拟机上部署多个zk进程,配置如下,
| 地址 | myid | 对外端口 | 通信端口 | 选举端口 | dataDir |
| 本机 | 1 | 2182 | 2382 | 2482 |
/home/dev/datas/zookeeper3.7.0/cluster/node1 |
| 本机 | 2 | 2183 | 2383 | 2483 |
/home/dev/datas/zookeeper3.7.0/cluster/node2 |
| 本机 | 3 | 2184 | 2384 | 2484 |
/home/dev/datas/zookeeper3.7.0/cluster/node3 |
有了上面的配置,只需要在conf文件夹下,分别创建3个配置文件夹,然后放置zoo.cfg文件即可,分别按照上面的配置进行修改,在启动的时候分别制定不同的配置文件,

然后分别修改node1、node2、node3中的zoo.cfg文件,修改的配置项如下,node1
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node1
clientPort=2182
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
node2
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node2
clientPort=2183
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
node3
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node3
clientPort=2184
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
之后再dataDir目录下还要建立一个myid的文本文件,文件的内容分别为node1下为1、node2下为2、node3下为3
2.2.2.2、启动
经过了上面对集群模式下的配置,下面启动集群中的3个节点,方式如下
bin/zkServer.sh --config conf/node1 start
看下面的图片,

按照上面的方式分别启动node1、node2、node3节点。
3、测试
上面,我们分别使用单机版和集群版按照了zookeeper,那么怎么测试是否安装成功
3.1、单机版
在单机版下,如果没有改端口直接使用即可,
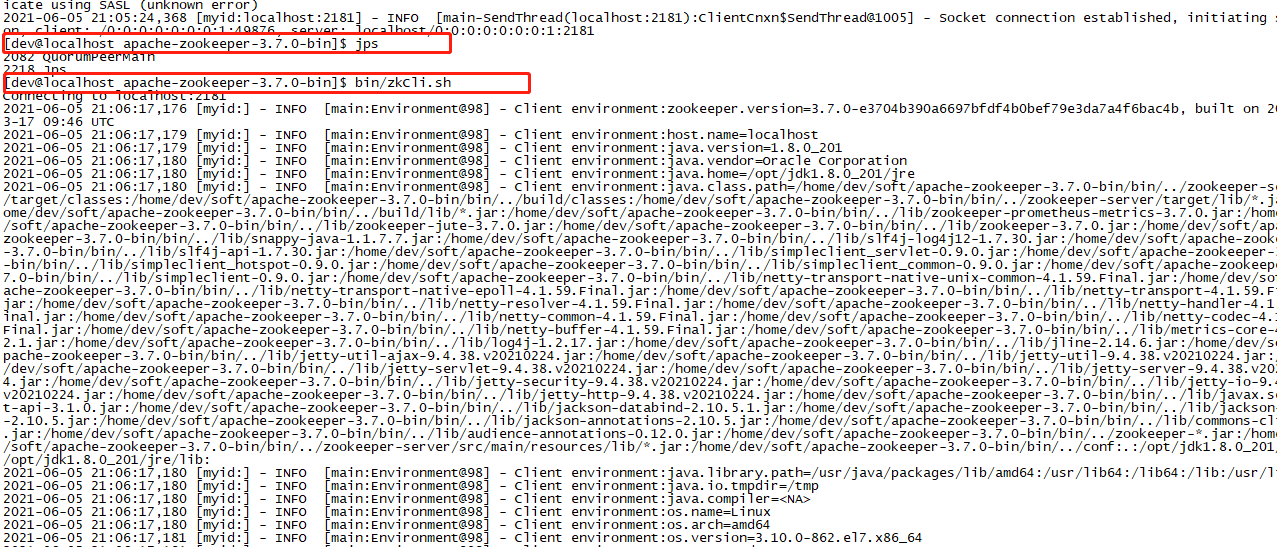
bin/zkCli.sh
出现下面的画面说明启动成功
3.2、集群版
3.2.1、验证单节点是否启动成功
在集群模式下,由于没有使用默认的端口,这里需要使用下面的命令,
#登录node3节点
bin/zkCli.sh -server 127.0.0.1:2183

3.2.2、验证集群是否正常同步数据
对于集群测试,还可以在node1上新建目录,然后在node3上检查是否存在该目录
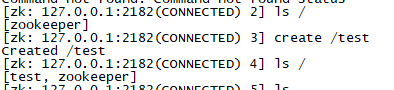
看node3下的目录
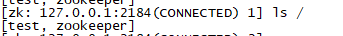
这样就可以看出zookeeper集群是正常的。
3.2.3、验证集群状态
可以通过查看集群的命令查看整个集群的状态
bin/zkServer.sh --config conf/node1 status

看下node2的状态

以上几种方式说明zookeeper集群正常。
有不正之处,欢迎指正。参考:
https://blog.csdn.net/dandandeshangni/article/details/80558383
https://www.cnblogs.com/8899man/p/5710191.html

zookeeper之二:zookeeper3.7.0安装过程实操的更多相关文章
- VMware VCSA 6.0安装过程 (转)
VMware VCSA 6.0安装过程(专版) 一.环境准备 VMware vCenter Server Appliance(VCSA)6.0的部署和之前的版本不同,在5.5及之前的版本可以通过 ...
- Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程
Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程 下载安装文件 Oracle Data Integrator 12cR1 (12.1.3.0.0) http: ...
- Nebula 2.5.0安装过程及遇到的坑
2021年8月23日,Nebula 发布了最新版本:2.5.0,正好赶上新环境部署,记录一下安装过程及遇到的坑: 一.准备工作 以下安装使用nebula用户,搭建集群模式,一共三台机器:192.168 ...
- VMware workstation16 中Centos7下MySQL8.0安装过程+Navicat远程连接
1.MySQL yum源安装 2.安装后,首次登录mysql以及密码配置3.远程登录问题(Navicat15为例) 一.CentOS7+MySQL8.0,yum源安装1.安装mysql前应卸载原有my ...
- Mysql 6.0安装过程(截图放不上去)
由于免费,MySQL数据库在项目中用的越来越广泛,而且它的安全性能也特别高,不亚于oracle这样的大型数据库软件.可以简单的说,在一些中小型的项目中,使用MySQL ,PostgreSQL是最佳 ...
- 百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨.经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基 ...
- GitBook安装部署实操手册
前言 GitBook是一个基于Node.js的命令行工具,可使用Git和Markdown来编写文档,赞誉太多,不再赘述. Node.js 下载安装包 cd /tmp wget https://node ...
- Hadoop2.2.0安装过程记录
1 安装环境1.1 客户端1.2 服务端1.3 安装准备 2 操作系统安装2.1.1 BIOS打开虚拟化支持2.1.2 关闭防火墙2.1.3 安装 ...
- 【Zookeeper学习】Zookeeper-3.4.6安装部署
[时间]2014年11月19日 [平台]Centos 6.5 [工具] [软件]jdk-7u67-linux-x64.rpm zookeeper-3.4.6.tar.gz [步骤] 1. 准备条件 ( ...
随机推荐
- Day16_90_通过反射机制获取某个特定的构造方法
通过反射机制获取某个特定的构造方法 public class ReflectTest13 { public static void main(String[] args) throws ClassNo ...
- Day13_72_类锁
类锁 * 对象锁(synchronized method{})和类锁(static sychronized method{})的区别 - 对象锁也叫实例锁,对应synchronized关键字,当多个线 ...
- Proxy.newProxyInstance源码探究
JDK动态代理案例实现:实现 InvocationHandler 接口重写 invoke 方法,其中包含一个对象变量和提供一个包含对象的构造方法: public class MyInvocationH ...
- CentOS7 基本概念以及安装注意事项
什么是Linux发行版?发行版是什么意思? Linux本质上是操作系统内核,类似Chrome浏览器内核一样,Linux发行版CentOS.Redhat.Ubuntu等等都是基于Linux内核开发出来的 ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- Python Basics with numpy (optional)
Python Basics with Numpy (optional assignment) Welcome to your first assignment. This exercise gives ...
- 7- MySQL结果数据处理与函数
复习: 查询:select 列名 from 表 去重:distinct 排序:order by 列1 列2 排序方法:asc desc. 限定返回行数:limit n limit n,m 过滤:whe ...
- 技术面试问题汇总第001篇:猎豹移动反病毒工程师part1
我在2014年7月1日参加了猎豹移动(原金山网络)反病毒工程师的电话面试,但是很遗憾,由于我当时准备不足,加上自身水平不够,面试官向我提出的很多技术问题我都没能答出来(这里面既有基础类的问题,也有比较 ...
- 洛谷P1422 小玉家的电费
题目描述 夏天到了,各家各户的用电量都增加了许多,相应的电费也交的更多了.小玉家今天收到了一份电费通知单.小玉看到上面写:据闽价电[2006]27号规定,月用电量在150千瓦时及以下部分按每千瓦时0. ...
- POJ2135 来回最短路(简单费用流)
题意: 就是从1走到n然后再走回来,一条边只能走一次,要求路径最短. 思路: 比较水,可以直接一遍费用流,不解释了,具体的看看代码,敲这个题就是为了练 练手,好久不敲了,怕比赛 ...