零基础Python爬虫实现(爬取最新电影排行)
提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记。
目标网站
http://dianying.2345.com/top/
网站结构

要爬的部分,在ul标签下(包括li标签), 大致来说迭代li标签的内容输出即可。
遇到的问题?
代码简单, 但遇到的问题很多。
一: 编码
这里统一使用gbk了。
二: 库
过程中缺少requests,bs4,idna,certifi,chardet,urllib3等库, 需要手动添加库, 我说一下我的方法
库的添加方法:
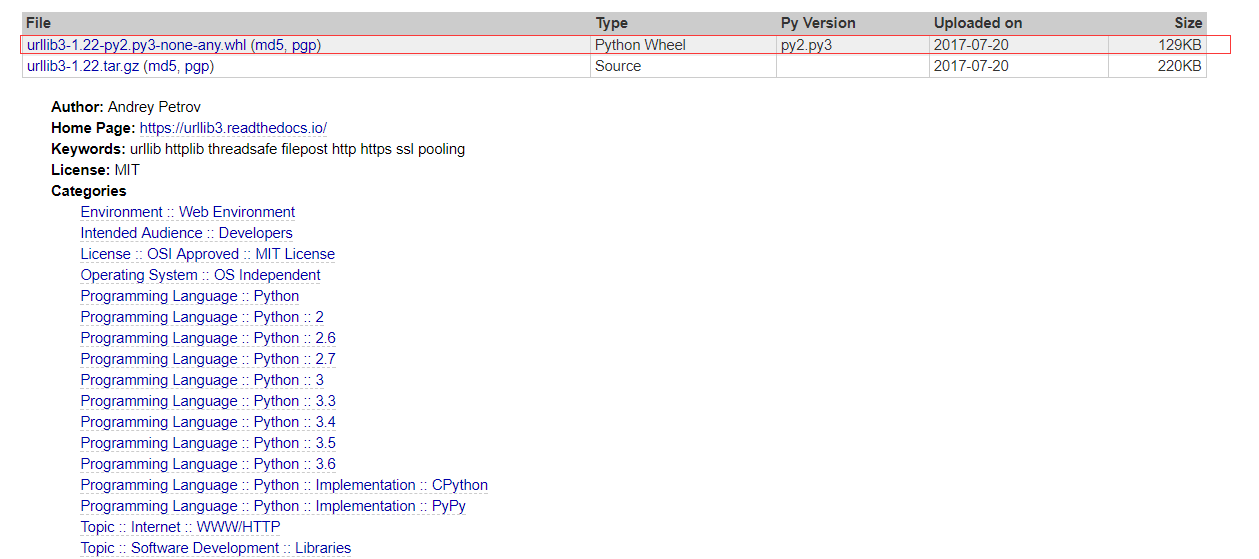
例如:urllib3
百度urllib3,通过链接下载到本地

我下载第一个
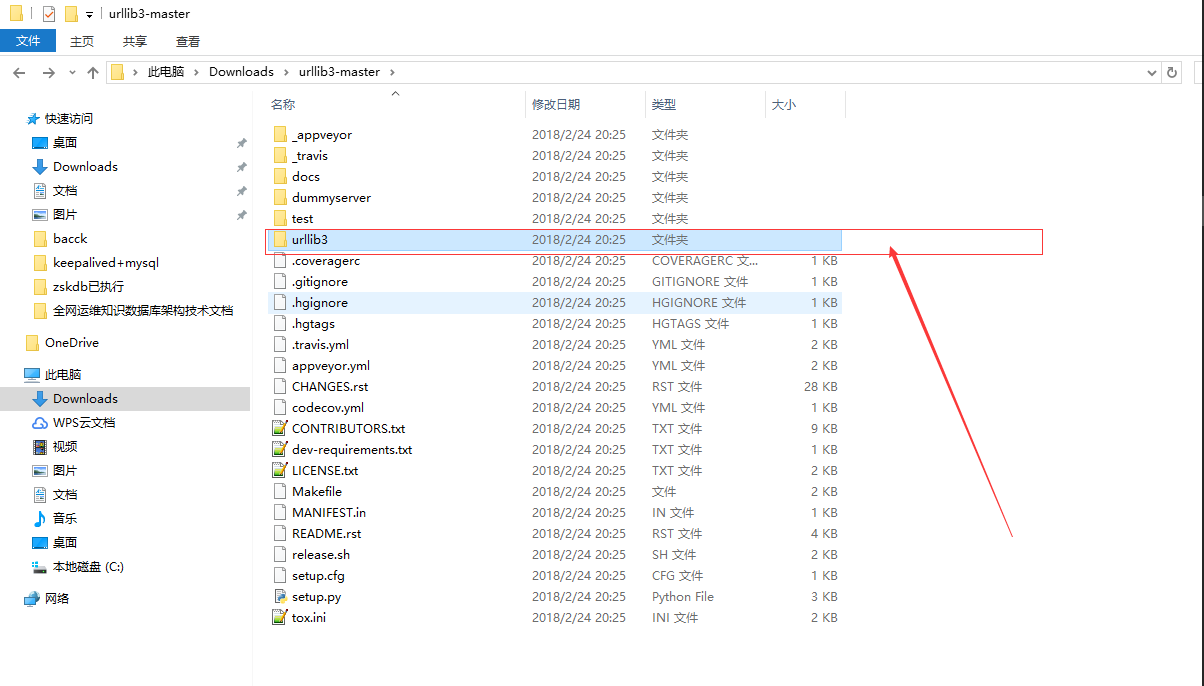
解压把urllib3文件夹扔进python安装目录的Lib目录下即可
三: 下载图片链接
这个就有意思了, 之前我是这样写的
f.write(requests.get(img_url).content)
报错
File "C:\Users\Shinelon\AppData\Local\Programs\Python\Python36\lib\requests\models.py", line 379, in prepare_url
raise MissingSchema(error)
requests.exceptions.MissingSchema: Invalid URL '//imgwx5.2345.com/dypcimg/img/c/65/sup196183_223x310.jpg': No schema supplied. Perhaps you meant http:////imgwx5.2345.com/dypcimg/img/c/65/sup196183_223x310.jpg? Process finished with exit code 1
图片是这样的,也无法进行迭代输出下载
没办法,后来自己自动给链接加上http:
img_url2 = 'http:' + img_url
f.write(requests.get(img_url2).content)
print(img_url2)
f.close()
然后就正常了。
附上代码
import requests
import bs4 def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = 'gbk'
return r.text
except:
return "someting wrong" def get_content(url):
html = get_html(url)
soup = bs4.BeautifulSoup(html, 'lxml') movieslist = soup.find('ul', class_='picList clearfix')
movies = movieslist.find_all('li') for top in movies:
#爬取图片src
img_url = top.find('img')['src']
#爬取影片name
name = top.find('span', class_='sTit').a.text
try:
#爬取影片上映时间
time = top.find('span', class_='sIntro').text
except:
time = "暂无上映时间"
#爬取电影角色主演
actors = top.find('p', class_='pActor')
actor = ''
for act in actors.contents:
actor = actor + act.string + ' '
#爬取电影简介
intro = top.find('p', class_='pTxt pIntroShow').text
print("片名:{}\t{}\n{}\n{} \n \n ".format(name, time, actor,intro))
#下载图片到指定目录
with open('/Users/Shinelon/Desktop/1212/'+name+'.png','wb+') as f:
img_url2 = 'http:' + img_url
f.write(requests.get(img_url2).content)
print(img_url2)
f.close() def main():
url = 'http://dianying.2345.com/top/'
get_content(url) if __name__ == "__main__":
main()
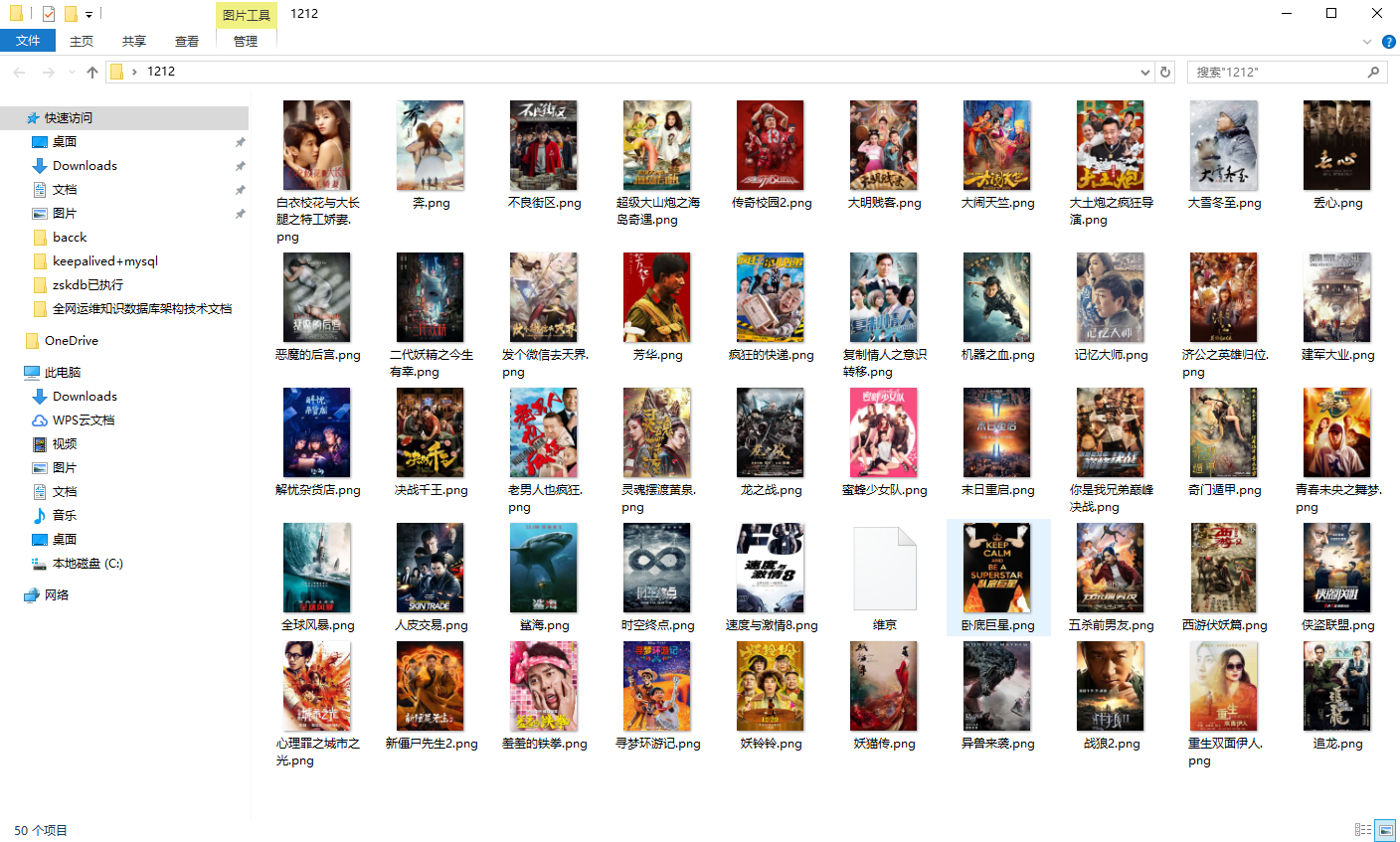
结果

零基础Python爬虫实现(爬取最新电影排行)的更多相关文章
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- 爬取豆瓣电影排行top250
功能描述V1.0: 爬取豆瓣电影排行top250 功能分析: 使用的库 1.time 2.json 3.requests 4.BuautifulSoup 5.RequestException 上机实验 ...
随机推荐
- 利用yum升级Centos6的gcc版本,使其支持C++11
下面的可以在centos6下工作,centos7下有问题.可能是因为centos下的scl我是拷贝的文件,没有完全验证centos6下肯定没问题. https://my.oschina.net/u/5 ...
- spring之文件上传
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- LA 2218 Triathlon(半平面交)
Triathlon [题目链接]Triathlon [题目类型]半平面交 &题解: 做了2道了,感觉好像套路,都是二分答案,判断半平面交是否为空. 还有刘汝佳的代码总是写const +& ...
- Git安装及创建版本库
一.在Windows上安装Git 1.虽然用于开发的系统最好是用Mac或者Linux,但绝大多数新人都是用Windows进行开发.Windows系统上也有提供了Git(Windows版),下载地址:h ...
- Day7 错误和异常
一.异常 1.异常基础 1.为了让我们的代码在出现异常的时候,整个项目依然是可以正常运行的,所以我们引入了异常处理机制! 2.在编程过程中为了增加友好性,在程序出现bug时一般不会将错误信息显示给用户 ...
- EXTENDED LIGHTS OUT (高斯消元)
In an extended version of the game Lights Out, is a puzzle with 5 rows of 6 buttons each (the actual ...
- SpringMVC探究-----常用获取传递参数的方法
1.@RequestParam @RequestParam 常用来映射请求参数,它有三个属性可以配置: value 值即请求参数的参数名 required 该参数是否必须. 默认为 true d ...
- cocos v3.10 下载地址
官方给出的是在:http://www.cocos2d-x.org/filedown/CocosForWin-v3.10.exe如果下载不了,可以在这里下http://cdn.cocos2d-x.org ...
- qDeleteAll 之后必须清空容器
[1]qDeleteAll应用示例 qDeleteAll源码如下: template <typename ForwardIterator> Q_OUTOFLINE_TEMPLATE voi ...
- 关于SqlCommand对象的2个方法:ExecuteNonQuery 方法和ExecuteScalar方法
1.SqlCommand.ExecuteNonQuery 方法 对连接执行 Transact-SQL 语句并返回受影响的行数. 语法:public override int ExecuteNonQue ...