大数据-09-Intellij idea 开发java程序操作HDFS
主要摘自 http://dblab.xmu.edu.cn/blog/290-2/
简介
本指南介绍Hadoop分布式文件系统HDFS,并详细指引读者对HDFS文件系统的操作实践。Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,如果已经安装了Hadoop,其中就已经包含了HDFS组件,不需要另外安装。
利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
利用Java API进行交互,需要利用软件Eclipse编写Java程序。
(一) 在Ubuntu中安装Intellij idea
直接在官网下载试用版本ideaIU-2018.1.1.tar.gz。
(二)在idea创建项目
点击创建新项目

选择java项目, 如果在SDK未显示1.8, 请点南new按键添加相应SDK,默认位置为/usr/lib/jvm/java-8-openjdk-amd64

在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/HDFSExample”目录下然后,点击界面底部的“Next>”按钮,进入下一步的完成设置。
(三)为项目添加需要用到的JAR包
在File>Project Struecture 中添加引用JAR包

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中按钮,

为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar添加到当前的Java工程中。
(四)编写Java应用程序代码
输入新建的Java类文件的名称,这里采用名称“HDFSFileIfExist”,其他都可以采用默认设置,然后,点击界面右下角“OK”按钮,
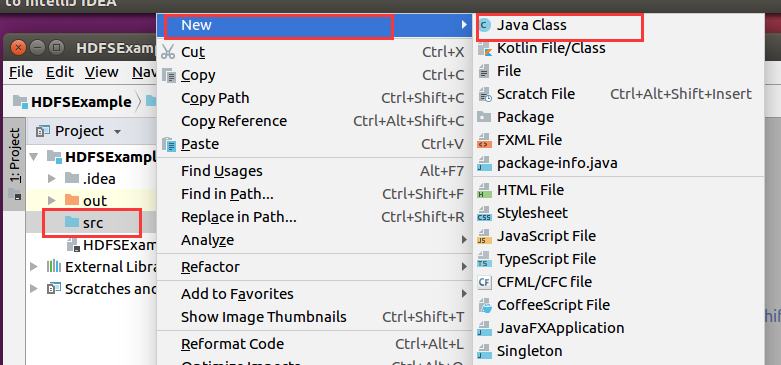
创建了一个名为“HDFSFileIfExist.java”的源代码文件,请在该文件中输入以下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args){
try{
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.3.236:9000"); // 这里根据自己实际情况调整
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
(五)编译运行程序
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh
在Project窗口中,选中HDFSFileIfExist类,右键选择run,即可看到结果。 上java代码中,我们设置的判断HDFS中是否含有test名字的文件,可以根据实际情况作调整。
(六)应用程序的部署
下面介绍如何把Java应用程序生成JAR包,部署到Hadoop平台上运行。首先,在Hadoop安装目录下新建一个名称为myapp的目录,用来存放我们自己编写的Hadoop应用程序,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop
mkdir myapp
然后,请在Idea工作界面左侧的File > Project Structure,出现如下面示后,再作相应选择:

然后选择要导出的类

然后选删除其它依赖类,只留下自己的代码即可
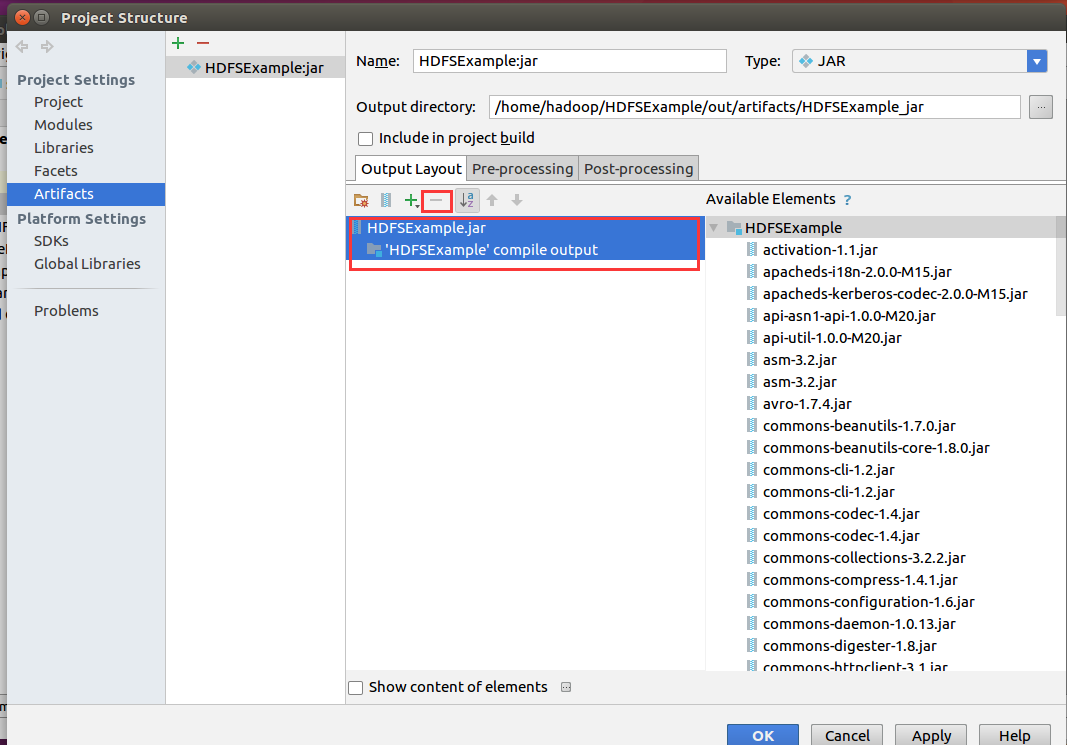
选择菜单栏的Build,选择Build Artifacts。
然后测试程序
cp out/artifacts/HDFSExample_jar/HDFSExample.jar /usr/local/hadoop/
./bin/hadoop jar HDFSExample.jar
我这里输出结果是
文件不存在
如果在上面导出设置时,不删除依赖类,则用下面的方法也可以运行:
java -jar ./HDFSExample.jar
得到一样的结果。
大数据-09-Intellij idea 开发java程序操作HDFS的更多相关文章
- Java程序操作HDFS
1.新建项目2.导包 解压hadoop-2.7.3.tar.gzE:\工具\大数据\大数据提升资料\01-软件资料\06-Hadoop\安装包\Java1.8环境下编译\hadoop-2.7.3\ha ...
- 大数据全栈式开发语言 – Python
前段时间,ThoughtWorks在深圳举办一次社区活动上,有一个演讲主题叫做“Fullstack JavaScript”,是关于用JavaScript进行前端.服务器端,甚至数据库(MongoDB) ...
- 为什么说Python 是大数据全栈式开发语言
欢迎大家访问我的个人网站<刘江的博客和教程>:www.liujiangblog.com 主要分享Python 及Django教程以及相关的博客 交流QQ群:453131687 原文链接 h ...
- 26.使用IntelliJ IDEA开发Java Web项目时,修改了JSP后刷新浏览器无法及时显示修改后的页面
转自:https://blog.csdn.net/yuxxz/article/details/51318908 使用IntelliJ IDEA开发Java Web项目时,修改了JSP后刷新浏览器无法及 ...
- 006 01 Android 零基础入门 01 Java基础语法 01 Java初识 06 使用Eclipse开发Java程序
006 01 Android 零基础入门 01 Java基础语法 01 Java初识 06 使用Eclipse开发Java程序 Eclipse下创建程序 创建程序分为以下几个步骤: 1.首先是创建一个 ...
- Java程序操作数据库SQLserver详解
数据库基本操作:增删改查(CRUD) crud介绍(增.删.改.查操作) CRUD是指在做计算处理时的增加(Create).查询(Retrieve)(重新得到数据).更新(Update)和删除(Del ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- 大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程 1.图示过程 输入:HDFS文件 /input/data.txt Mapper阶段: K1:数据偏移量(以单词记)V1:行数据 K2:单词 V2:记一次数 ...
随机推荐
- 在ASP.NET MVC 框架中调用 html文件及解析get请求中的参数值
在ASP.NET MVC 框架中调用 html文件: public ActionResult Index() { using (StreamReader sr = new StreamReader(P ...
- MapReduce(四)
MapReduce(四) 1.shuffle过程 2.map中setup,map,cleanup的作用. 一.shuffle过程 https://blog.csdn.net/techchan/arti ...
- forget sus,syn sym semi word out~s
1★ sus 在~下面 2★ syn 3★ sym 共同 4★ semi 半
- matlab plot line settings
- linux下iostat命令详解
iostat用于输出CPU和磁盘I/O相关的统计信息 iostat语法 用法:iostat [ 选项 ] [ <时间间隔> [ <次数> ]] 常用选项说明: -c:只显示系统 ...
- -L、-rpath和-rpath-link的区别
链接器ld的选项有 -L,-rpath 和 -rpath-link,看了下 man ld,大致是这个意思: -L:: “链接”的时候去找的目录,也就是所有的 -lFOO 选项里的库,都会先从 -L ...
- ubuntu启用root登陆
ubuntu系统不能够默认以root用户登陆系统如果你为了方便开发想每次登陆的时候以root用户登陆那么需要手动的做写更改打开终端 首先输入命令 sudo passwd root更新你的密码然后输入 ...
- Daily record-August
August11. A guide dog can guide a blind person. 导盲犬能给盲人引路.2. A guide dog is a dog especially trained ...
- QuickStart系列:docker部署之Mysql
这里配置只做开发用,生产环境请根据需要修改或自行搜索其他说明 使用docker安装mysql,目前版本5.7.4(当前时间 2018.1.11) 环境 vm: Centos7 镜像来源 https:/ ...
- python-第一类对象,闭包,迭代器
# def fn(): # print("我叫fn") # fn() # print(fn) # <function fn at 0x0000000001D12E18> ...