Python 八大排序算法速度比较
这篇文章并不是介绍排序算法原理的,纯粹是想比较一下各种排序算法在真实场景下的运行速度。
算法由 Python 实现,用到了一些语法糖,可能会和其他语言有些区别,仅当参考就好。
测试的数据是自动生成的,以数组形式保存到文件中,保证数据源的一致性。
排序算法

直接插入排序
- 时间复杂度:O(n²)
- 空间复杂度:O(1)
- 稳定性:稳定
def insert_sort(array):
for i in range(len(array)):
for j in range(i):
if array[i] < array[j]:
array.insert(j, array.pop(i))
break
return array
希尔排序
- 时间复杂度:O(n)
- 空间复杂度:O(n√n)
- 稳定性:不稳定
def shell_sort(array):
gap = len(array)
while gap > 1:
gap = gap // 2
for i in range(gap, len(array)):
for j in range(i % gap, i, gap):
if array[i] < array[j]:
array[i], array[j] = array[j], array[i]
return array
简单选择排序
- 时间复杂度:O(n²)
- 空间复杂度:O(1)
- 稳定性:不稳定
def select_sort(array):
for i in range(len(array)):
x = i # min index
for j in range(i, len(array)):
if array[j] < array[x]:
x = j
array[i], array[x] = array[x], array[i]
return array
堆排序
- 时间复杂度:O(nlog₂n)
- 空间复杂度:O(1)
- 稳定性:不稳定
def heap_sort(array):
def heap_adjust(parent):
child = 2 * parent + 1 # left child
while child < len(heap):
if child + 1 < len(heap):
if heap[child + 1] > heap[child]:
child += 1 # right child
if heap[parent] >= heap[child]:
break
heap[parent], heap[child] = \
heap[child], heap[parent]
parent, child = child, 2 * child + 1 heap, array = array.copy(), []
for i in range(len(heap) // 2, -1, -1):
heap_adjust(i)
while len(heap) != 0:
heap[0], heap[-1] = heap[-1], heap[0]
array.insert(0, heap.pop())
heap_adjust(0)
return array
冒泡排序
- 时间复杂度:O(n²)
- 空间复杂度:O(1)
- 稳定性:稳定
def bubble_sort(array):
for i in range(len(array)):
for j in range(i, len(array)):
if array[i] > array[j]:
array[i], array[j] = array[j], array[i]
return array
快速排序
- 时间复杂度:O(nlog₂n)
- 空间复杂度:O(nlog₂n)
- 稳定性:不稳定
def quick_sort(array):
def recursive(begin, end):
if begin > end:
return
l, r = begin, end
pivot = array[l]
while l < r:
while l < r and array[r] > pivot:
r -= 1
while l < r and array[l] <= pivot:
l += 1
array[l], array[r] = array[r], array[l]
array[l], array[begin] = pivot, array[l]
recursive(begin, l - 1)
recursive(r + 1, end) recursive(0, len(array) - 1)
return array
归并排序
- 时间复杂度:O(nlog₂n)
- 空间复杂度:O(1)
- 稳定性:稳定
def merge_sort(array):
def merge_arr(arr_l, arr_r):
array = []
while len(arr_l) and len(arr_r):
if arr_l[0] <= arr_r[0]:
array.append(arr_l.pop(0))
elif arr_l[0] > arr_r[0]:
array.append(arr_r.pop(0))
if len(arr_l) != 0:
array += arr_l
elif len(arr_r) != 0:
array += arr_r
return array def recursive(array):
if len(array) == 1:
return array
mid = len(array) // 2
arr_l = recursive(array[:mid])
arr_r = recursive(array[mid:])
return merge_arr(arr_l, arr_r) return recursive(array)
基数排序
- 时间复杂度:O(d(r+n))
- 空间复杂度:O(rd+n)
- 稳定性:稳定
def radix_sort(array):
bucket, digit = [[]], 0
while len(bucket[0]) != len(array):
bucket = [[], [], [], [], [], [], [], [], [], []]
for i in range(len(array)):
num = (array[i] // 10 ** digit) % 10
bucket[num].append(array[i])
array.clear()
for i in range(len(bucket)):
array += bucket[i]
digit += 1
return array
速度比较
from random import random
from json import dumps, loads # 生成随机数文件
def dump_random_array(file='numbers.json', size=10 ** 4):
fo = open(file, 'w', 1024)
numlst = list()
for i in range(size):
numlst.append(int(random() * 10 ** 10))
fo.write(dumps(numlst))
fo.close() # 加载随机数列表
def load_random_array(file='numbers.json'):
fo = open(file, 'r', 1024)
try:
numlst = fo.read()
finally:
fo.close()
return loads(numlst)
数据生成函数
from _datetime import datetime # 显示函数执行时间
def exectime(func):
def inner(*args, **kwargs):
begin = datetime.now()
result = func(*args, **kwargs)
end = datetime.now()
inter = end - begin
print('E-time:{0}.{1}'.format(
inter.seconds,
inter.microseconds
))
return result return inner
显示执行时间
如果数据量特别大,采用分治算法的快速排序和归并排序,可能会出现递归层次超出限制的错误。
解决办法:导入 sys 模块(import sys),设置最大递归次数(sys.setrecursionlimit(10 ** 8))。
@exectime
def bubble_sort(array):
for i in range(len(array)):
for j in range(i, len(array)):
if array[i] > array[j]:
array[i], array[j] = array[j], array[i]
return array array = load_random_array()
print(bubble_sort(array) == sorted(array))
↑ 示例:测试直接插入排序算法的运行时间,@exectime 为执行时间装饰器。
算法执行时间
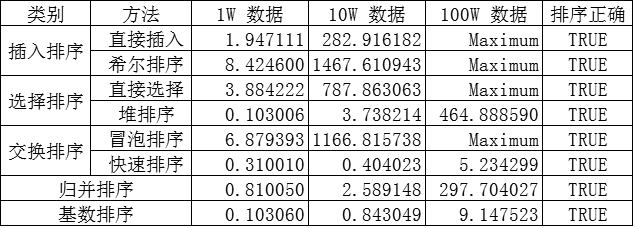
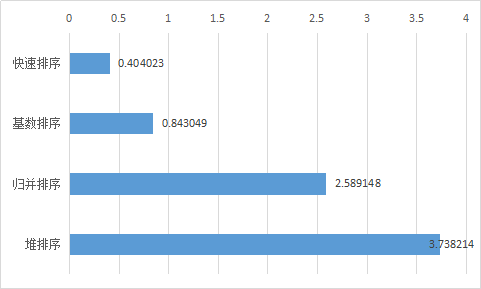
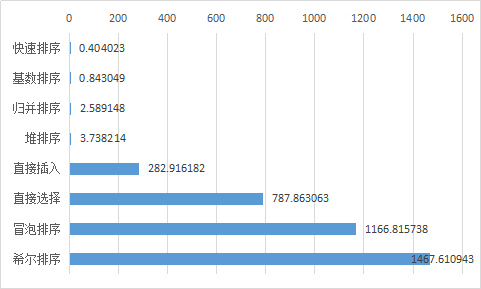
算法速度比较
Python 八大排序算法速度比较的更多相关文章
- Python - 八大排序算法
1.序言 本文使用Python实现了一些常用的排序方法.文章结构如下: 1.直接插入排序 2.希尔排序 3.冒泡排序 4.快速排序 5.简单选择排序 6.堆排序 7.归并排序 8.基数排序 上述所有的 ...
- 八大排序算法的 Python 实现
转载: 八大排序算法的 Python 实现 本文用Python实现了插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个 ...
- Python实现八大排序算法(转载)+ 桶排序(原创)
插入排序 核心思想 代码实现 希尔排序 核心思想 代码实现 冒泡排序 核心思想 代码实现 快速排序 核心思想 代码实现 直接选择排序 核心思想 代码实现 堆排序 核心思想 代码实现 归并排序 核心思想 ...
- 【Python】八大排序算法的比较
排序是数据处理比较核心的操作,八大排序算法分别是:直接插入排序.希尔排序.简单选择排序.堆排序.冒泡排序.快速排序.归并排序.基数排序 以下是排序图解: 直接插入排序 思想 直接插入排序是一种最简单的 ...
- python实现排序算法 时间复杂度、稳定性分析 冒泡排序、选择排序、插入排序、希尔排序
说到排序算法,就不得不提时间复杂度和稳定性! 其实一直对稳定性不是很理解,今天研究python实现排序算法的时候突然有了新的体会,一定要记录下来 稳定性: 稳定性指的是 当排序碰到两个相等数的时候,他 ...
- 八大排序算法总结与java实现(转)
八大排序算法总结与Java实现 原文链接: 八大排序算法总结与java实现 - iTimeTraveler 概述 直接插入排序 希尔排序 简单选择排序 堆排序 冒泡排序 快速排序 归并排序 基数排序 ...
- [Data Structure & Algorithm] 八大排序算法
排序有内部排序和外部排序之分,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存.我们这里说的八大排序算法均为内部排序. 下图为排序 ...
- Python之排序算法:快速排序与冒泡排序
Python之排序算法:快速排序与冒泡排序 转载请注明源地址:http://www.cnblogs.com/funnyzpc/p/7828610.html 入坑(简称IT)这一行也有些年头了,但自老师 ...
- 八大排序算法Java实现
本文对常见的排序算法进行了总结. 常见排序算法如下: 直接插入排序 希尔排序 简单选择排序 堆排序 冒泡排序 快速排序 归并排序 基数排序 它们都属于内部排序,也就是只考虑数据量较小仅需要使用内存的排 ...
随机推荐
- Spring的Aspect切面类不能拦截Controller中的方法
根本原因在于<aop:aspectj-autoproxy />这句话是在spring的配置文件内,还是在springmvc的配置文件内.如果是在spring的配置文件内,则@Control ...
- 使用FreeSWITCH做电话自动回访设置
一.背景介绍: 目前公司在处理客户回访方面,需要人工进行电话回访,尤其是逢年过节的时候,电话问候更能体现服务的品质: 在某些公司,电话销售员需要给大批量的陌生用户打电话,如果能过滤掉不关心的用户,销售 ...
- mysql分组排序取最大值所在行,类似hive中row_number() over partition by
如下图, 计划实现 :按照 parent_code 分组, 取组中code最大值所在的整条记录,如红色部分.(类似hive中: row_number() over(partition by)) sel ...
- OCM_第七天课程:Section3 —》数据库可用性
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- laravel使用when搜索遇到状态参数(有0的状态)的坑
今天,使用when()方法写活动列表的接口,有两个状态搜索,都有0这个状态,当传参为0时when()就失效了... 反反复复的验证参数,传参确实是0和1啊...百思不得其解~~~后面仔细想想when( ...
- Java String str = new String(value)和String str = value区别
示例代码: public class StringDemo2 { public static void main(String[] args) { String s1 = new String(&qu ...
- IntelliJ IDEA 下的SVN使用
最近公司的很多同事开始使用IntelliJ Idea,便尝试了一下,虽然快捷键与eclipse 有些不同,但是强大的搜索功能与“漂亮的界面”(个人认为没有eclipse好看 ),还是值得我们去使用的. ...
- 【C++ Primer 第11章】4. 无序容器
一.介绍 1. Hashtable和bucket 由于unordered_map内部采用的hashtable的数据结构存储,所以,每个特定的key会通过一些特定的哈希运算映射到一个特定的位置,我们知道 ...
- 安卓在代码中设置TextView的drawableLeft、drawableRight、drawableTop、drawableBottom
Drawable rightDrawable = getResources().getDrawable(R.drawable.icon_new); //调用setCompoundDrawables时, ...
- hdu 1385 Floyd 输出路径
Floyd 输出路径 Sample Input50 3 22 -1 43 0 5 -1 -122 5 0 9 20-1 -1 9 0 44 -1 20 4 05 17 8 3 1 //收费1 3 // ...