Convolutional Neural Networks(4):Feature map size,Padding and Stride
在CNN(1)中,我们用到下图来说明卷积之后feature maps尺寸和深度的变化。这一节中,我们讨论feature map size, padding and stride。
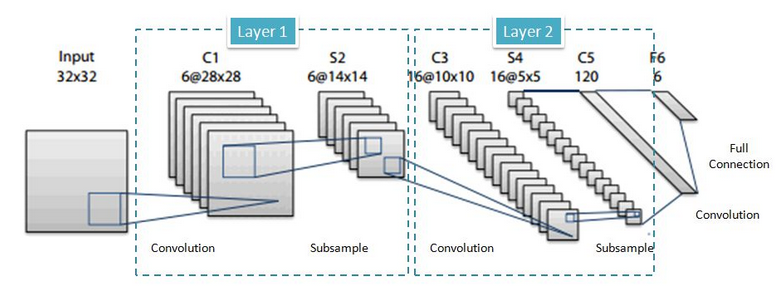
首先,在Layer1中,输入是32x32的图片,而卷积之后为28x28,试问filter的size(no padding)? (答案是5x5)。 如果没答上来,请看下图:
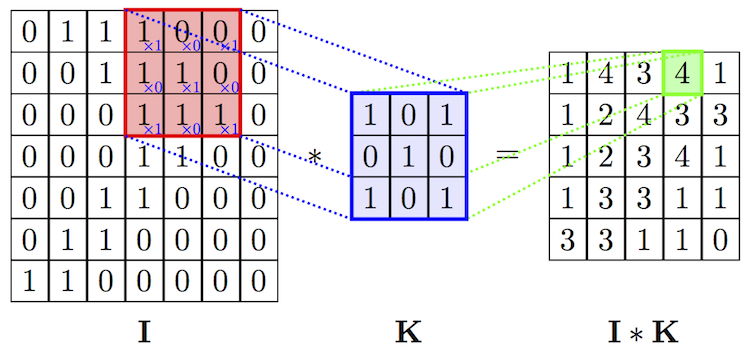
I是一张7x7的图片,filter是3x3的,I*K生成的feature map是5x5的。所以我们推出feature map size公式为:

其中n(l)表示在l层中图片的大小,f(l)是filter的大小所以在最初的问题中filtersize=32-28+1=5。
而在convolution操作中,有一个padding参数可以在原图外围加上空白格,从而使feature map的size不发生变化。通常不使用padding的Convolution称为Valid Convolution,而使用padding输出相同size的feature map,则称为Same Convolution。Feature map和Padding的Size计算公式为:
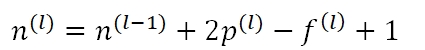
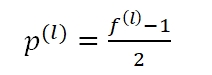
其中,p(l)是padding的大小。使用Padding的原因主要有二:
第一,因为architecture的原因,不希望图片尺寸发生变化;
其二,如果不使用padding,在图片边缘的pixel只被计算了一次,其数据被低估了。
Stride是表示filter工作间隔的参数,默认是1,根据需要可以设置为其他值,在设置了Stride之后,feature map的计算公式为:

其中,s(l)是stride步幅的大小。当然,图片并不都是正方的,我们可以分别计算feature map的width和height
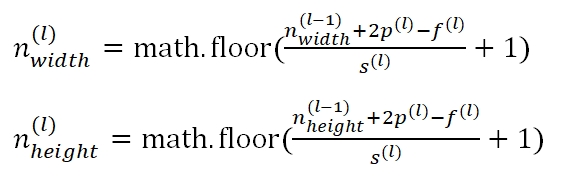
Convolutional Neural Networks(4):Feature map size,Padding and Stride的更多相关文章
- 机器视觉:Convolutional Neural Networks, Receptive Field and Feature Maps
CNN 大概是目前 CV 界最火爆的一款模型了,堪比当年的 SVM.从 2012 年到现在,CNN 已经广泛应用于CV的各个领域,从最初的 classification,到现在的semantic se ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- A Beginner's Guide To Understanding Convolutional Neural Networks(转)
A Beginner's Guide To Understanding Convolutional Neural Networks Introduction Convolutional neural ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks Part 2
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- [转]An Intuitive Explanation of Convolutional Neural Networks
An Intuitive Explanation of Convolutional Neural Networks https://ujjwalkarn.me/2016/08/11/intuitive ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- 【论文翻译】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文链接:https://arxi ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
随机推荐
- [常用类]Math、Random、System、BigInteger、BigDecimal
Math类中的成员全是静态成员,构造方法是 私有的,以避免被创建对象 常用方法: int abs() double ceil() //向上取整 double floor() //向下取整 int ma ...
- P2835 刻录光盘 (tarjan缩点)
[题目描述] 现在假设总共有N个营员(2<=N<=200),每个营员的编号为1~N.LHC给每个人发了一张调查表,让每个营员填上自己愿意让哪些人到他那儿拷贝资料.当然,如果A愿意把资料拷贝 ...
- 时间选择器moment格式化存在时差问题
时间选择器moment格式化存在时差问题解决方法: return moment(date).utc().zone(+6).format('YYYY-MM-DD')解决IE9时间选择器不能回显数据解决方 ...
- linux tcp/ip 调优
sysctl 变量修改方法:sysctl –a 使用 sysctl 命令修改系统变量,和通过编辑 sysctl.conf 文件来修改系统变量两种.但并不是所有的 变量都可以在这个模式下设定. 注:sy ...
- Sql Server 出现此数据库没有有效所有者问题
在新建数据库或附加数据库后,想添加关系表,结果出现下面的错误: 此数据库没有有效所有者,因此无法安装数据库关系图支持对象.若要继续,请首先使用“数据库属性”对话框的“文件”页或ALTER AUTHO ...
- Oracle 数字转为字符串 to_char()
格式:TO_CHAR(number,'format_model') 9 -->Represents a number 0 --> Forces a zero to be displayed ...
- paste 合并文件
1.命令功能 paste 用于合并文件的列,把每个文件以列对列的方式,一列列地加以合并. 2.语法格式 paste option file 参数选项 参数 参数说明 -d 指定间隔符合并文件(默 ...
- mv 移动或重命名文件
1. 命令功能 mv:移动或改文件名 2. 语法格式 mv [option] source dest mv 选项 源文件 目标文件 参数 参数说明 -f 如果目标文件存在,则不会询问而是直接覆 ...
- Java类加载器初识
类加载器基本概念 类加载器(class loader)用来加载 Java 类到 Java 虚拟机中.一般来说,Java虚拟机使用Java类的方式如下:Java 源程序(.java 文件)在经过 Jav ...
- [BZOJ] 书堆
问题描述 蚂蚁是勤劳的动物,他们喜欢挑战极限?现在他们迎来了一个难题!蚂蚁居住在图书馆里,图书馆里有大量的书籍.书是形状大小质量都一样的矩形.蚂蚁要把这些书摆在水平桌子的边緣.蚂蚁喜欢整洁的布置,所以 ...