Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
几个常见的用到ajax的场景。
比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或者话题有了新动态的消息提示。
还比如,我们在看视频时,可以看到下面的评论没有完全全部加载出来,而是你向下拖动一点,它给你加载一点。
为什么要用到ajax呢?
从上述场景你应该也可以发现它的优点,
第一,方便与用户的交互,不用重新加载整个网页,就可以实现刷新,不用中断用户的行为。你正在看程序员如何找对象呢,此时来个消息推送,整个网页被刷新了,你说你气不气!
第二个呢,还是你在看程序员如何找对象,但是此时通信状况不好啊。回答加载不出来,页面就空白的卡那了,回答加载不出来,你说急不急!那这样咯,先给你看几个回答,在你看的时候我再悄悄的加载其它的数据,那不就解决了吗?就跟吃饭一个道理,你点了一桌子菜,难道菜全做好了再给你上吗?肯定不会的呀,做好一道上一道嘛,对不对。
第三,从服务端的发送过来的ajax数据,体积比较小。浏览器知道怎么渲染它,这样就减轻了服务端的压力,让客户端,也就是浏览器承担了一些任务。
Ajax技术的核心是XMLHttpRequest对象(简称XHR),可以通过使用XHR对象获取到服务器的数据,然后再通过DOM将数据插入到页面中呈现。虽然名字中包含XML,但Ajax通讯与数据格式无关,所以我们的数据格式可以是XML或JSON等格式。
XMLHttpRequest对象用于在后台与服务器交换数据,具体作用如下:
- 在不重新加载页面的情况下更新网页
- 在页面已加载后从服务器请求数据
- 在页面已加载后从服务器接收数据
- 在后台向服务器发送数据
2. Ajax对爬虫有什么影响?
还是对应着上述的场景,我爬虫肯定要爬取一个完整数据。但是你一次就只教我两种找对象的方法。还不够我举一反三呢,万一其中还有几个段子,那这样的数据不具有完整性,不够全面。但是不滑动浏览器,数据不出来怎么办?
更坑爹是什么,ajax加载出来的数据是通过浏览器渲染给我们的呀,源代码不一定能找到我们要的数据。那该肿么办!浏览器知道怎么加载, 我们不知道呀!
3.如何爬取这样的ajax动态加载的网页。
1. Selenium + PhantomJs
PhantomJS是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。它的作用是和浏览器类似,可以渲染js处理的页面。
selenium是什么呢?它本来是个自动化测试工具,但是被广泛的用户爬虫啊。它是一个工具,这个工具可以用代码操作浏览器。比如控制浏览器的下滑之类。不过我并不是很熟悉,以前了解过一点。
不过,我没用这种方法。为啥呢,因为慢。操作浏览器的时间加起来好多好多了呗,而且又不是没有更好的办法。
2. 自己找,找真实请求。
只要是有数据发送过来,那肯定是有发送到服务器的请求的吧。我们只需找出它悄悄加载出的页面的真实请求在哪发送的。
寻找实例:爬取杭州萧山机场一天的航班信息。
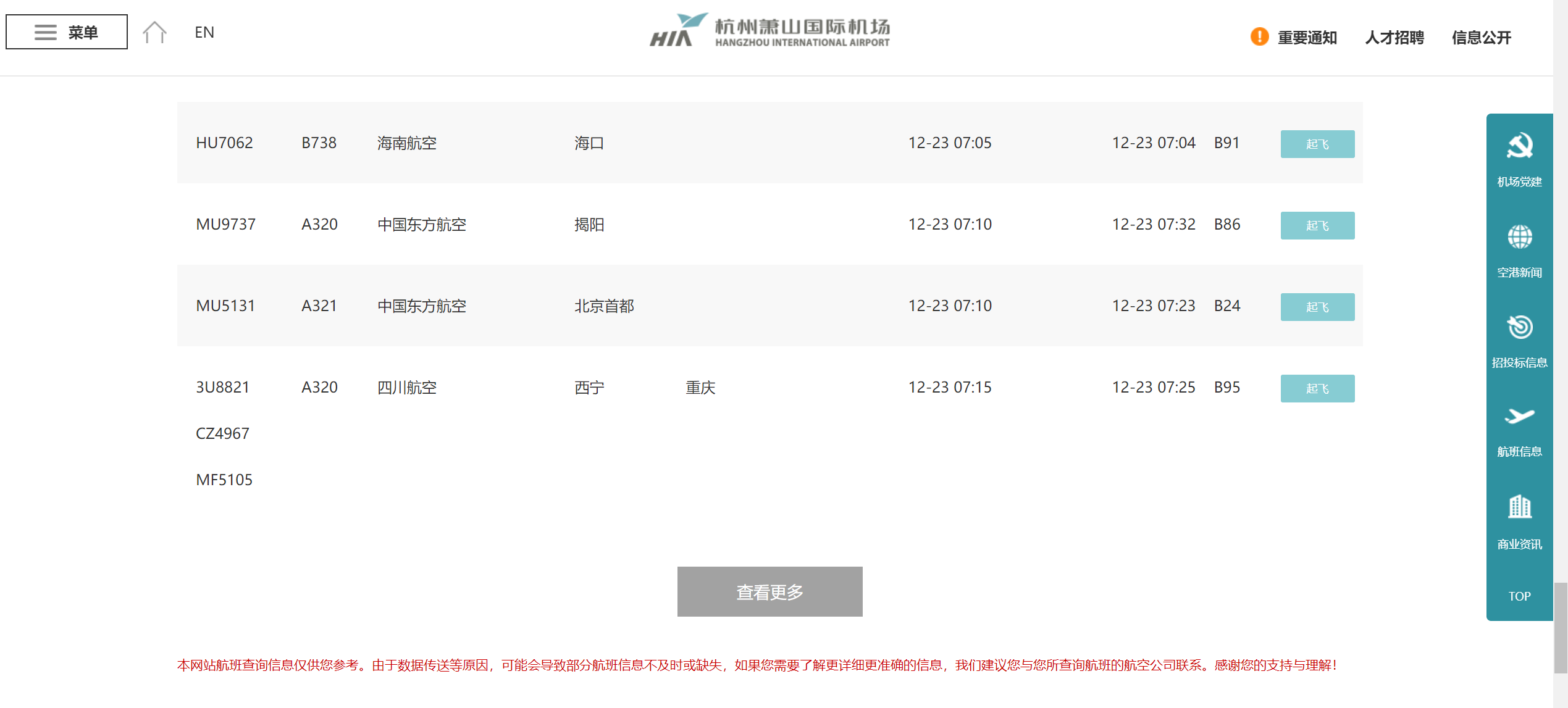
1)右键单击查看网页源码,发现点击“查看更多”之后的页面源码里没有新出现的航班信息,所以猜测它是使用了Ajax技术。用Wireshark抓个包先。
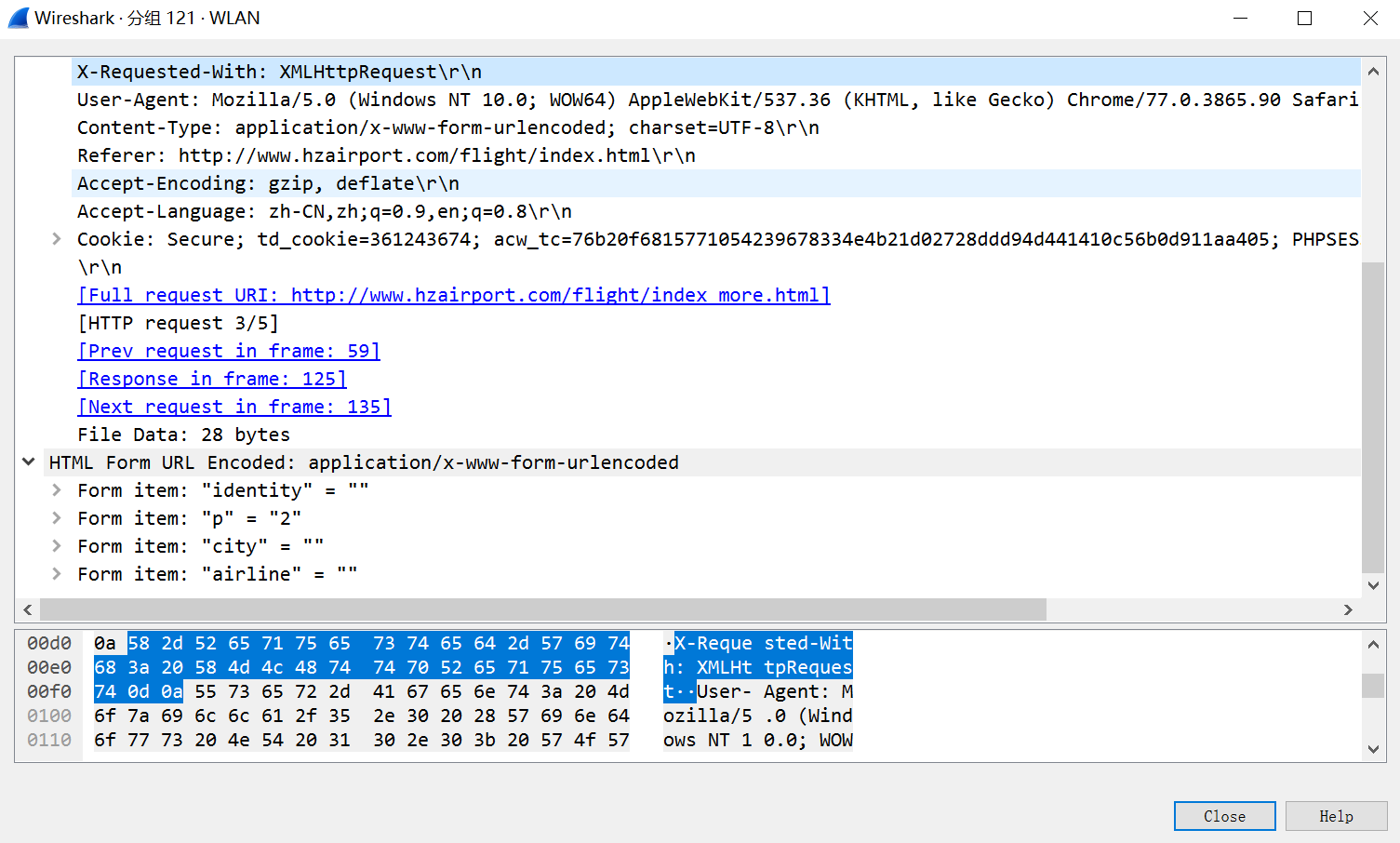
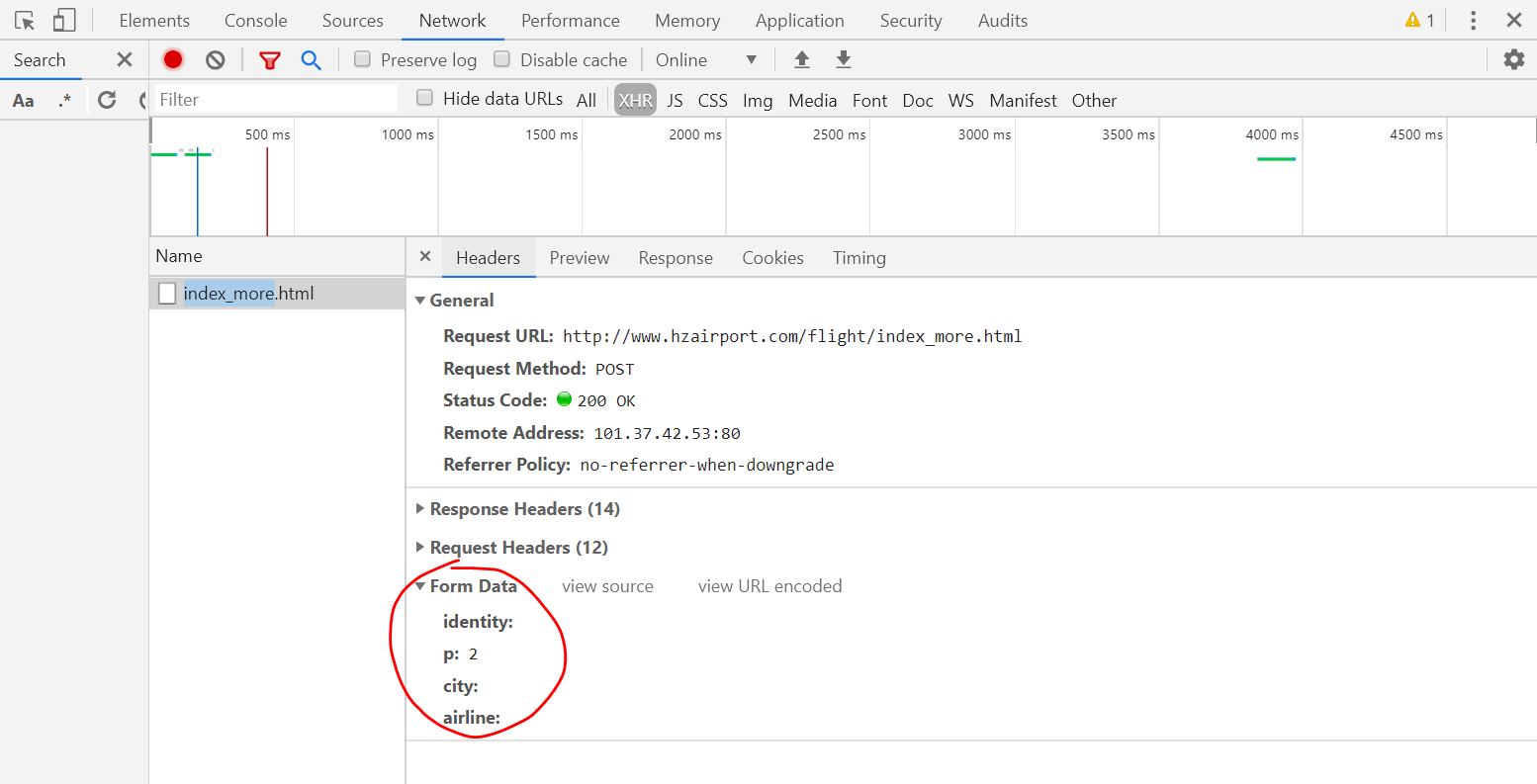
2.寻找传送XMLHttpRequest对象的参数。目测服务器是依据这个p值来选择传送的数据。
json格式检测:http://www.bejson.com/
原文链接:https://zhuanlan.zhihu.com/p/27346009
Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页的更多相关文章
- 爬虫——爬取Ajax动态加载网页
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 ...
- scrapy项目5:爬取ajax形式加载的数据,并用ImagePipeline保存图片
1.目标分析: 我们想要获取的数据为如下图: 1).每本书的名称 2).每本书的价格 3).每本书的简介 2.网页分析: 网站url:http://e.dangdang.com/list-WY1-dd ...
- Python3 网络爬虫:漫画下载,动态加载、反爬虫这都不叫事
一.前言 作者:Jack Cui 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那 ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- Python爬虫学习——使用selenium和phantomjs爬取js动态加载的网页
1.安装selenium pip install selenium Collecting selenium Downloading selenium-3.4.1-py2.py3-none-any.wh ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
随机推荐
- 【Python开发】python PIL读取图像转换为灰度图及另存为其它格式(也可批量改格式)
例如有一幅图,文件名为"a.jpg'. 读取: from PIL import Image #或直接import Image im = Image.open('a.jpg') 将图片转换成 ...
- BUUOJ misc 二维码
一个二维码,扫一下是提示:secret is here 用binwalk看一下: binwalk QR_code.png DECIMAL HEXADECIMAL DESCRIPTION ------- ...
- 如何解决Oracle11g使用dmp命令无法导出空表问题
如何解决Oracle11g使用dmp命令无法导出空表问题 导出:exp username/password@orcl file=路径 tables=(tb1) //tables=(tb1)可有 ...
- 算法 - k-means++
Kmeans++算法 Kmeans++算法,主要可以解决初始中心的选择问题,不可解决k的个数问题. Kmeans++主要思想是选择的初始聚类中心要尽量的远. 做法: 1. 在输入的数据点中随机选 ...
- 01串LIS(固定串思维)--Kirk and a Binary String (hard version)---Codeforces Round #581 (Div. 2)
题意:https://codeforc.es/problemset/problem/1204/D2 给你一个01串,如:0111001100111011101000,让你改这个串(使0尽可能多,任意 ...
- HTTPS原理(三次握手)
第一步: 客户端向服务器发送HTTPS请求,服务器将公钥以证书的形式发送到客户端(服务器端存放私钥和公钥). 第二步: 浏览器生成一串随机数,然后用公钥对随机数和hash签名进行加密,加密后发送给服务 ...
- MYSQL中的UNION和UNION ALL
SQL UNION 操作符 UNION 操作符用于合并两个或多个 SELECT 语句的结果集. 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列.列也必须拥有相似的数据类型.同时,每 ...
- RPC 框架 介绍 (转)
出处: 谁能用通俗的语言解释一下什么是 RPC 框架? 知乎: 问题:了解到最近 Java 的 Netty 很火,只知道它是这样类型的一种框架.想了解一下它主要用于解决了什么问题?适用于什么样的场景? ...
- Redis安全策略
1. 开启redis密码认证,并设置高复杂度密码 描述 redis在redis.conf配置文件中,设置配置项requirepass, 开户密码认证. redis因查询效率高,auth这种命令每秒能处 ...
- [Next] 四.在next中引入redux
添加 redux 写过 react 稍微复杂一些应用的话,应该都对 redux(mobx)有一定的了解.这次将 redux 引入到项目中 因为之前写项目的习惯,更喜欢使用 redux-thunk 改写 ...