SVM-SVR
高频率的接触到了SVM模型,而且还有使用SVM模型做回归的情况,即SVR。另外考虑到自己从第一次知道这个模型到现在也差不多两年时间了,从最开始的腾云驾雾到现在有了一点直观的认识,花费了不少时间。因此在这里做个总结,比较一下使用同一个模型做分类和回归之间的差别,也纪念一下与SVM相遇的两周年!这篇总结,不会涉及太多公式,只是希望通过可视化的方法对SVM有一个比较直观的认识。
由于代码比较多,没有放到正文中,所有代码都可以在github中:https://github.com/OnlyBelter/jupyter-note/blob/master/machine_learning/SVM/04_how%20SVM%20becomes%20to%20SVR.ipynb
0. 支持向量机(support vector machine, SVM)
原始SVM算法是由弗拉基米尔·万普尼克和亚历克塞·泽范兰杰斯于1963年发明的。1992年,Bernhard E. Boser、Isabelle M. Guyon和弗拉基米尔·万普尼克提出了一种通过将核技巧应用于最大间隔超平面来创建非线性分类器的方法。当前标准的前身(软间隔)由Corinna Cortes和Vapnik于1993年提出,并于1995年发表。
上个世纪90年代,由于人工神经网络(RNN)的衰落,SVM在很长一段时间里都是当时的明星算法。被认为是一种理论优美且非常实用的机器学习算法。
在理论方面,SVM算法涉及到了非常多的概念:间隔(margin)、支持向量(support vector)、核函数(kernel)、对偶(duality)、凸优化等。有些概念理解起来比较困难,例如kernel trick和对偶问题。在应用方法,SVM除了可以当做有监督的分类和回归模型来使用外,还可以用在无监督的聚类及异常检测。相对于现在比较流行的深度学习(适用于解决大规模非线性问题),SVM非常擅长解决复杂的具有中小规模训练集的非线性问题,甚至在特征多于训练样本时也能有非常好的表现(深度学习此时容易过拟合)。但是随着样本量mm的增加,SVM模型的计算复杂度会呈m2m2或m3m3增加。
在下面的例子中,均使用上一篇博客中提到的鸢尾属植物数据集。
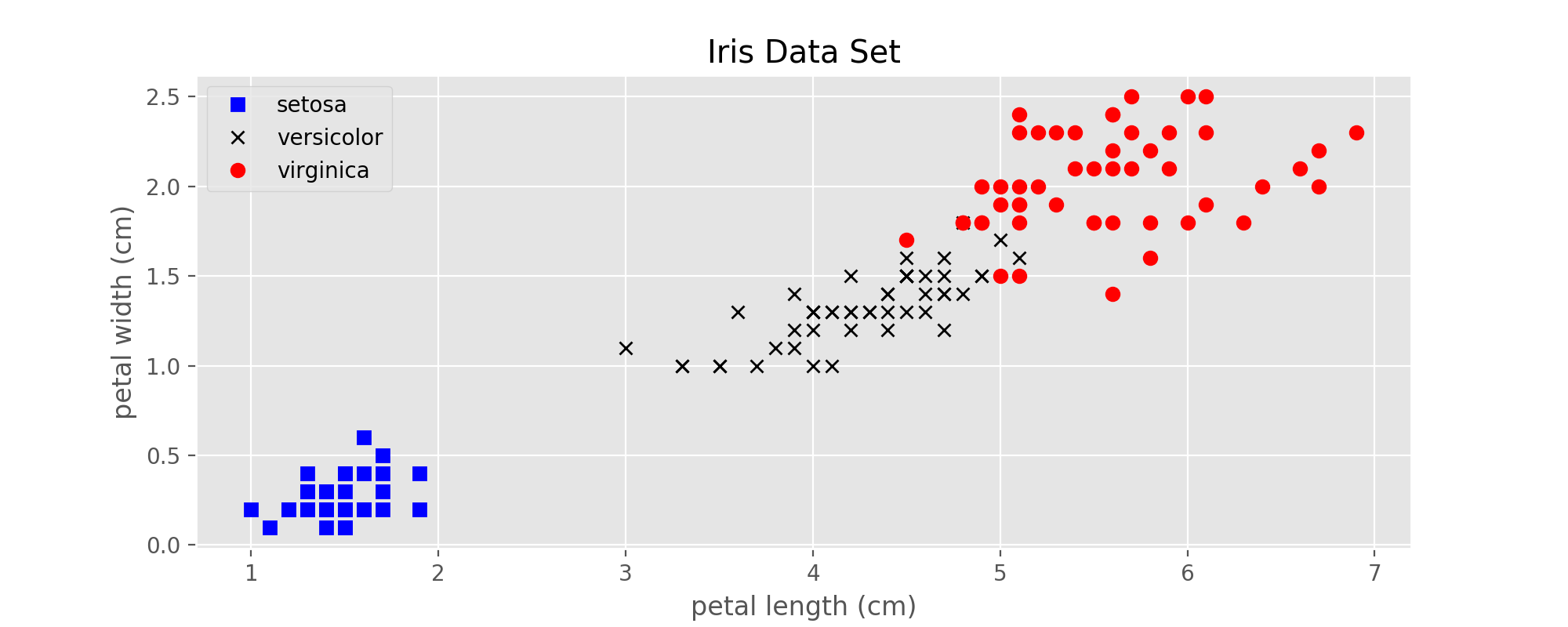
图1:Iris data set
1. SVM的前身:感知机(Perceptron)
感知机可以看做是低配版的线性SVM,从数学上可以证明:
在线性可分的两类数据中,感知机可以在有限步骤中计算出一条直线(或超平面)将这两类完全分开。
如果这两类距离越近,所需的步骤就越多。此时,感知机只保证给出一个解,但是解不唯一,如下图所示:
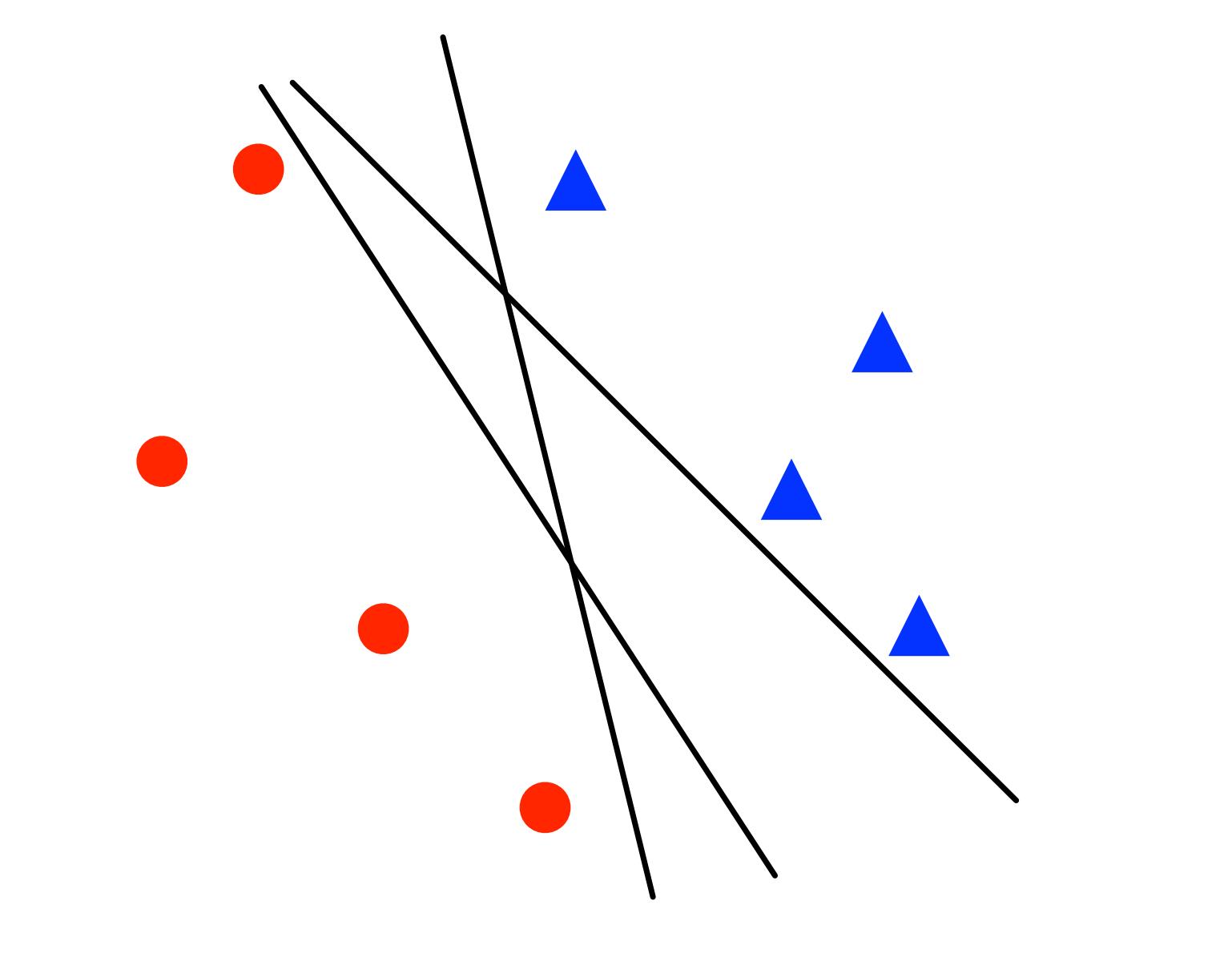
图2:感知机训练出来的3个不同的线性分类器

2. SVM - 线性可分
在两类样本线性可分的情况下,感知机可以保证找到一个解,完全正确的区分这两类样本。但是解不唯一,而且这些决策边界的质量也不相同,直观上来看这条线两边的间隔越大越好。那么有没有一种方法可以直接找到这个最优解呢?这就是线性SVM所做的事情。
从直观上来看,约束条件越多对模型的限制也就越大,因此解的个数也就越少。感知机的解不唯一,那么给感知机的代价函数加上更强的约束条件好像就可以减少解的个数。事实上也是这样的。
2.1 SVM的代价函数

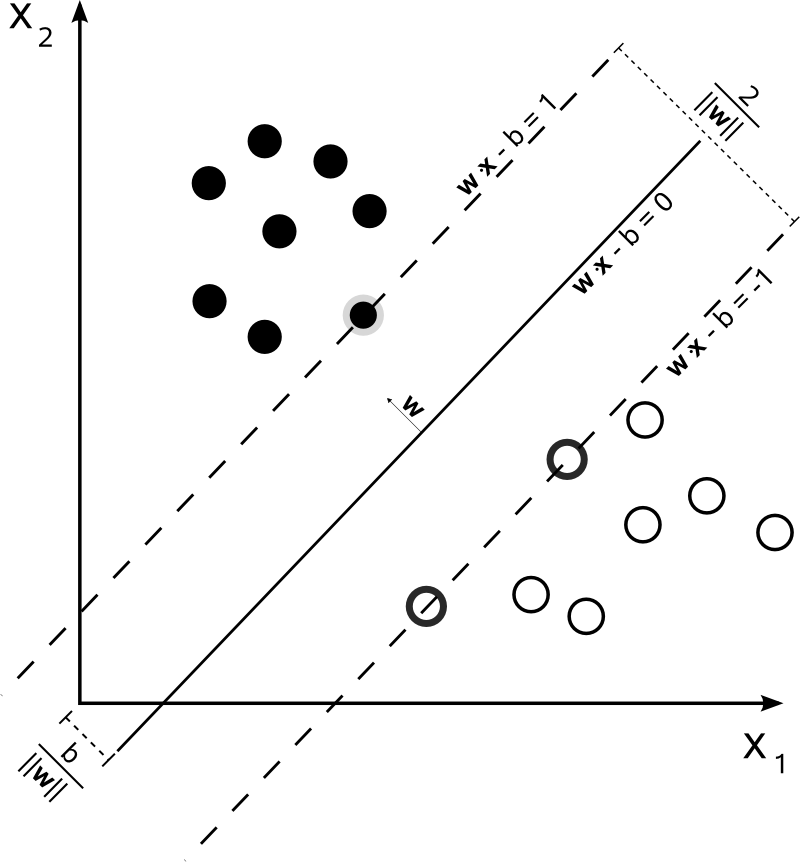
图3:设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在超平面上的样本点也称为支持向量。
2.2 决策边界以及间隔
图3来自wiki,为了统一起见,下面还是将决策边界定义为w⋅x+b=0 w⋅x+b=0,两边的边界(两条虚线)分别为w⋅x+b=1 和
下面是分别使用感知机和SVM对鸢尾属数据集中setosa这一类和非setosa进行分类的效果比较:
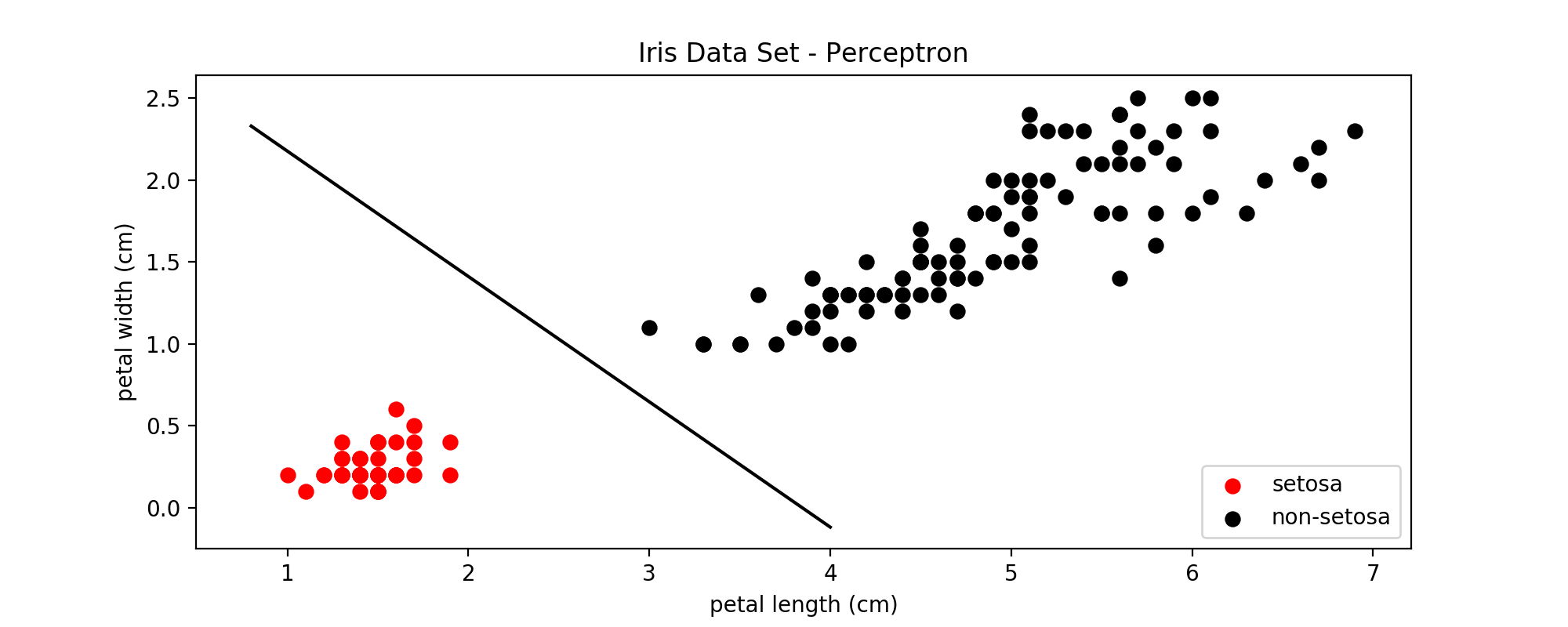
图5:感知机线性分类器
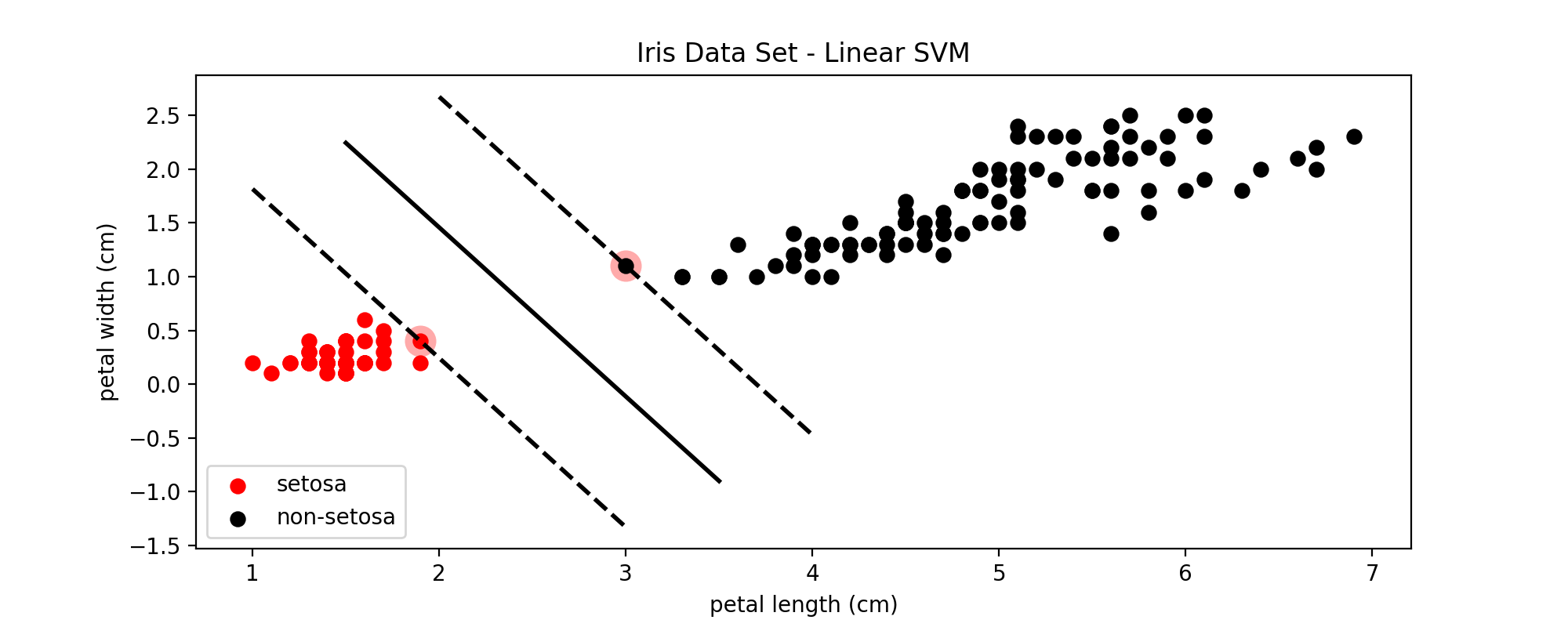
图6:线性SVM的分类效果
比较图5和图6可以看到,SVM确定的决策边界周围的margin更大一些,因此对更多未知的样本进行分类时,在边界上的一些点可以得到更准确的分类结果。
3. SVM - 线性不可分

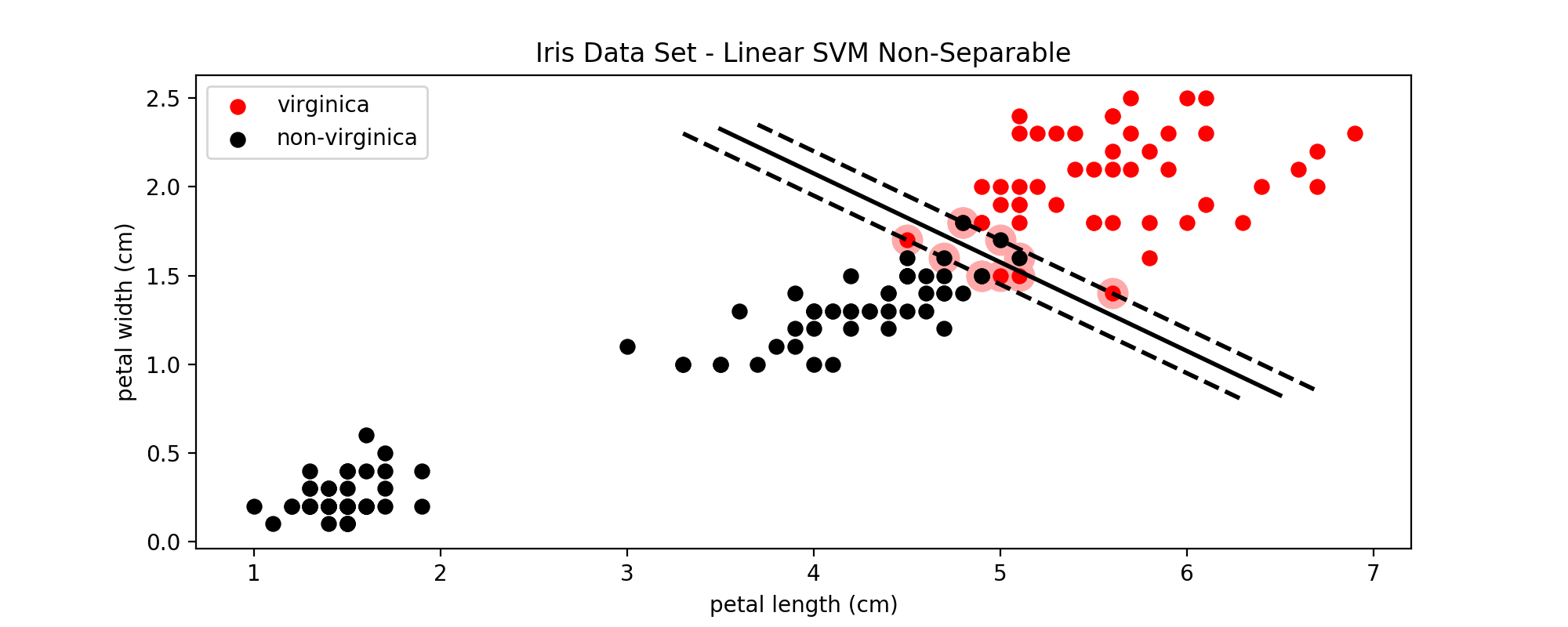
图8:加入松弛变量后的SVM分类效果
C作为SVM模型的超参数之一,需要从一个较大的范围中一步一步的筛选,直到找到最适合的C。C值越大,表示错误分类的代价越大,就越趋于拒绝错误分类,即hard margin;C值越小,表示错误分类的代价越小,就越能容忍错误分类,即soft margin。即使是在线性可分的情况下,如果C设置的非常小,也可能导致错误分类的出现;在线性不可分的情况下,设置过大的C值会导致训练无法收敛。
4. SVR - 利用SVM做回归分析
支持向量回归模型(Support Vector Regression, SVR)是使用SVM来拟合曲线,做回归分析。分类和回归问题是有监督机器学习中最重要的两类任务。与分类的输出是有限个离散的值(例如上面的{−1,1}{−1,1})不同的是,回归模型的输出在一定范围内是连续的。下面不再考虑不同鸢尾花的类型,而是使用花瓣的长度(相当于自变量x)来预测花瓣的宽度(相当于因变量y)。
下图中从所有150个样本中,随机取出了80%作为训练集:
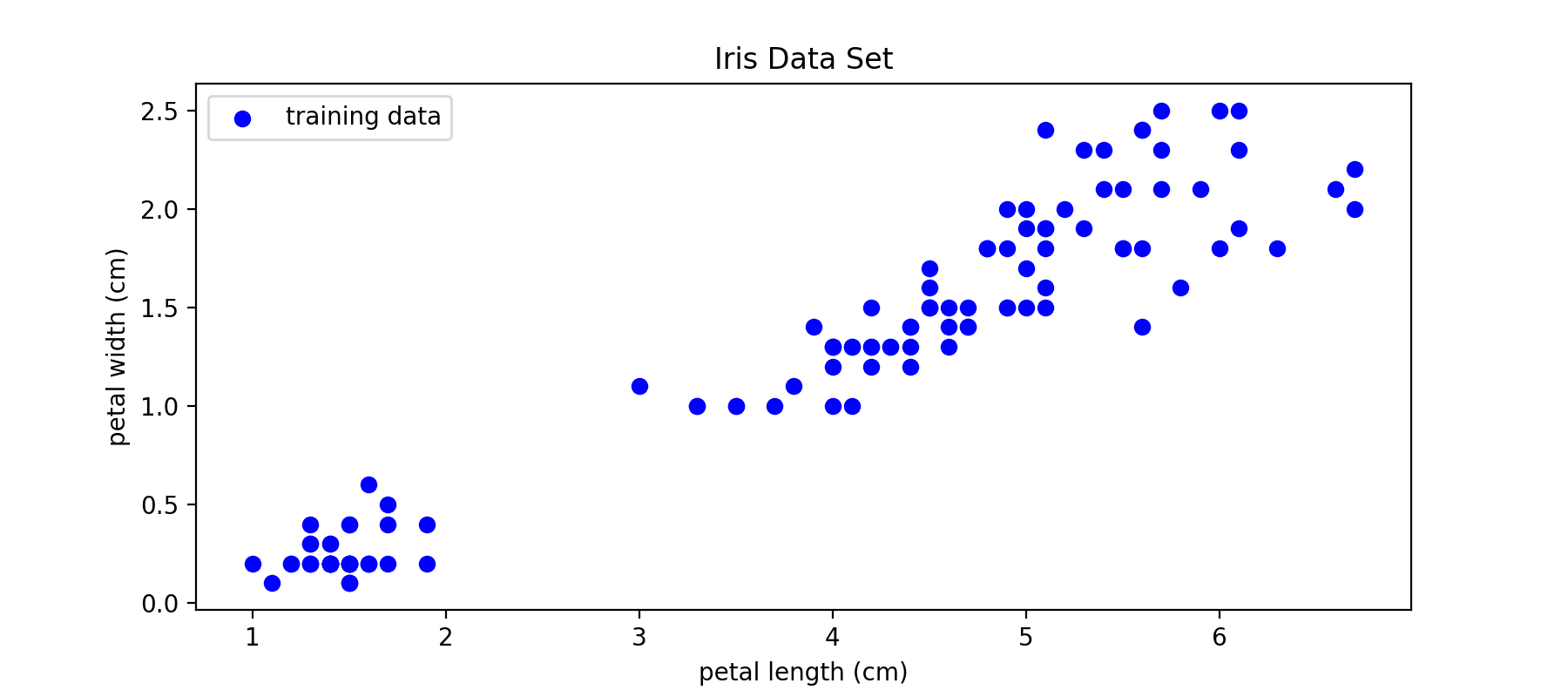
图9:训练SVR模型的训练样本
下面是使用线性SVR训练出来的回归线:
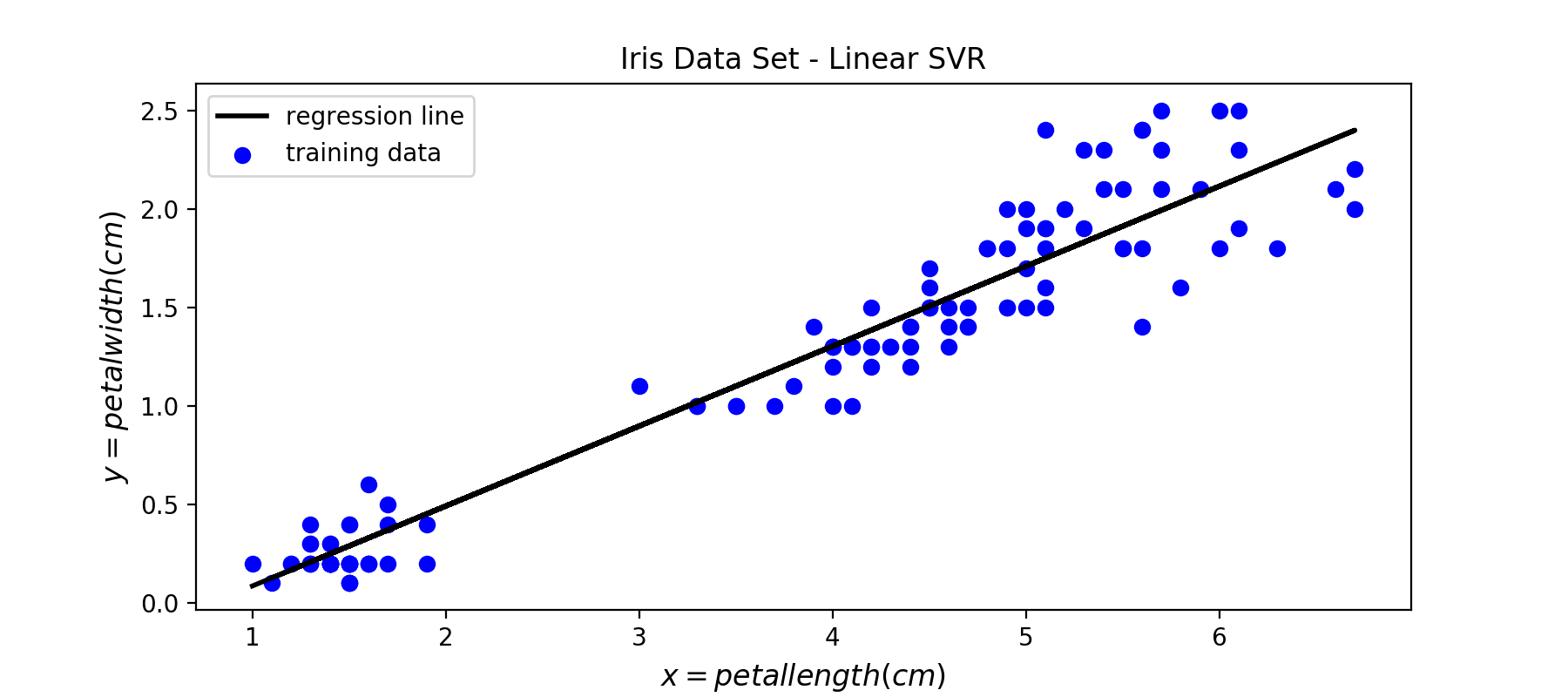
图10:SVR模型训练出来的回归线
与SVM是使用一个条带来进行分类一样,SVR也是使用一个条带来拟合数据。这个条带的宽度可以自己设置,利用参数ϵϵ来控制:
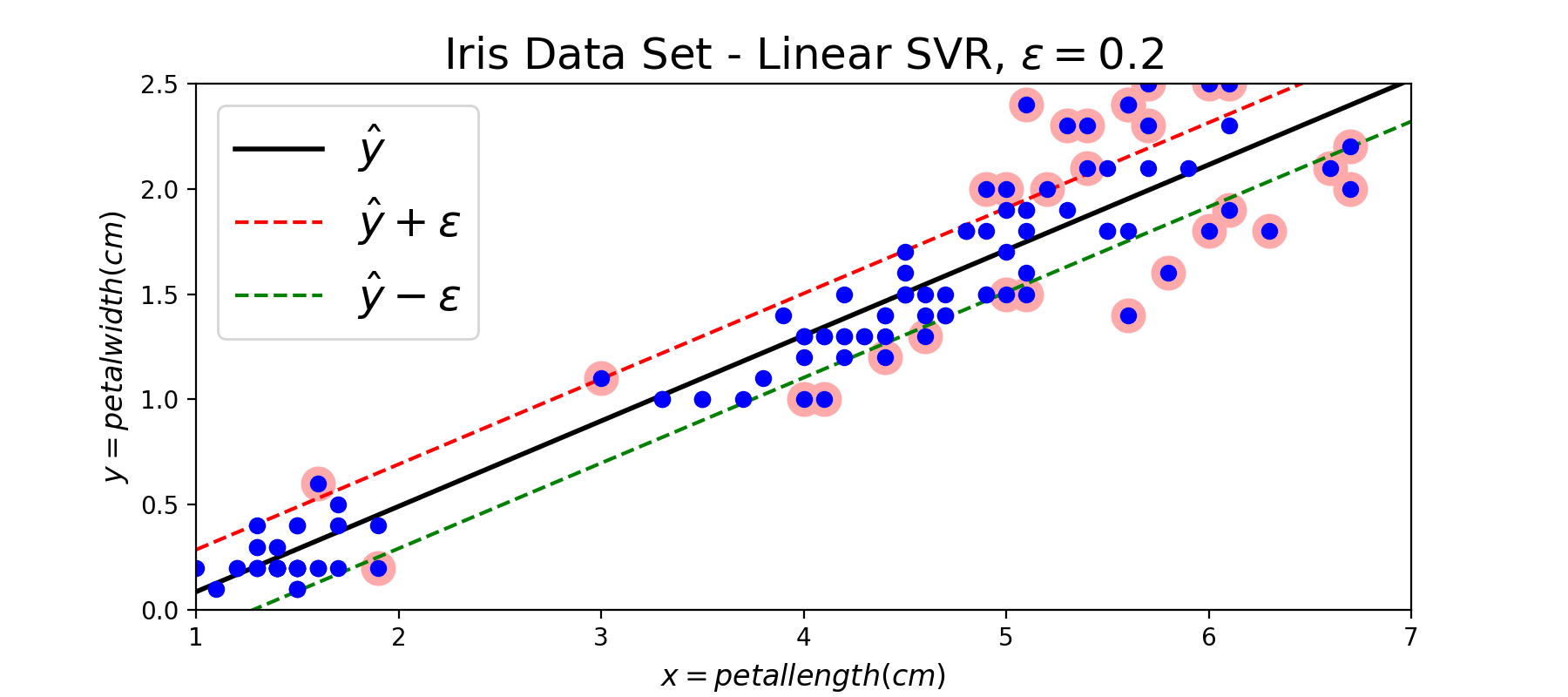
图11:SVR模型回归效果示意图,其中带红色环的点表示支持向量
在SVM模型中边界上的点以及两条边界内部违反margin的点被当做支持向量,并且在后续的预测中起作用;在SVR模型中边界上的点以及两条边界以外的点被当做支持向量,在预测中起作用。按照对偶形式的表示,最终的模型是所有训练样本的线性组合,其他不是支持向量的点的权重为0. 下面补充SVR模型的代价函数的图形:
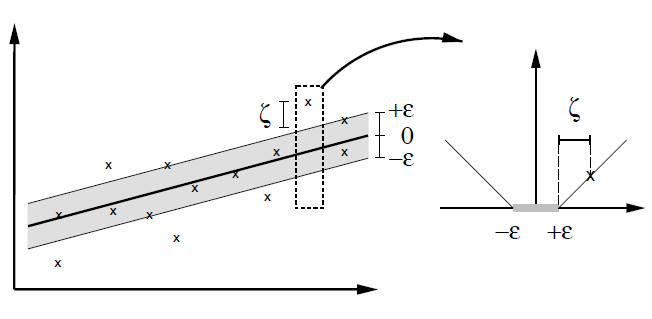
图12:soft margin SVR的代价函数
从图12中可以看到,在margin内部的这些点的error都为0,只有超出了margin的点才会计算error。因此SVR的任务就是利用一条固定宽度的条带(宽度由参数ϵϵ来控制)覆盖尽可能多的样本点,从而使得总误差尽可能的小。
Reference
https://zh.wikipedia.org/wiki/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA
https://zhuanlan.zhihu.com/p/26263309, 直线方程的各种形式
https://github.com/ageron/handson-ml/blob/master/05_support_vector_machines.ipynb
http://www.svms.org/regression/SmSc98.pdf
http://www.robots.ox.ac.uk/~az/lectures/ml/
edx: UCSanDiegoX - DSE220x Machine Learning Fundamentals
https://github.com/OnlyBelter/jupyter-note/blob/master/machine_learning/SVM/04_how%20SVM%20becomes%20to%20SVR.ipynb, 文中代码
SVM-SVR的更多相关文章
- 机器学习之sklearn——SVM
sklearn包对于SVM可输出支持向量,以及其系数和数目: print '支持向量的数目: ', clf.n_support_ print '支持向量的系数: ', clf.dual_coef_ p ...
- 转载:scikit-learn学习之SVM算法
转载,http://blog.csdn.net/gamer_gyt 目录(?)[+] ========================================================= ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 机器学习——支持向量机(SVM)
支持向量机原理 支持向量机要解决的问题其实就是寻求最优分类边界.且最大化支持向量间距,用直线或者平面,分隔分隔超平面. 基于核函数的升维变换 通过名为核函数的特征变换,增加新的特征,使得低维度空间中的 ...
- LibSVM使用指南
LibSVM使用指南 一. SVM简介 在进行下面的内容时我们认为你已经具备了数据挖掘的基础知识. SVM是新近出现的强大的数据挖掘工具,它在文本分类.手写文字识别.图像分类.生物序列分析等实 ...
- LBP特征学习(附python实现)
LBP的全称是Local Binary Pattern即局部二值模式,是局部信息提取中的一种方法,它具有旋转不变性和灰度不变性等显著的优点.在人脸识别领域有很多案例,此外,局部特征的算法还有 SIFT ...
- Python & 机器学习之项目实践
机器学习是一项经验技能,经验越多越好.在项目建立的过程中,实践是掌握机器学习的最佳手段.在实践过程中,通过实际操作加深对分类和回归问题的每一个步骤的理解,达到学习机器学习的目的. 预测模型项目模板不能 ...
- sklearn11_函数汇总
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Kaggle 自行车租赁预测比赛项目实现
作者:大树 更新时间:01.20 email:59888745@qq.com 数据处理,机器学习 回主目录:2017 年学习记录和总结 .caret, .dropup > .btn > . ...
随机推荐
- PAT_A1089#Insert or Merge
Source: PAT A1089 Insert or Merge (25 分) Description: According to Wikipedia: Insertion sort iterate ...
- 接口调用post请求参数在body中
package com.ynhrm.common.utils; import com.alibaba.fastjson.JSONObject; import lombok.Data; import o ...
- KMP算法及实现
#include<cstdio> #include<cmath> #include<cstring> #include<iostream> #inclu ...
- 案例:forEach和some区别
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【转载】vue install报错run `npm audit fix` to fix them, or `npm audit` for details html
原链接https://www.jianshu.com/p/60591cfc6952 执行npm install 出现如下提醒 added 253 packages from 162 contribut ...
- 【学术篇】CF833B TheBakery 分治dp+主席树
题目の传送门~ 题目大意: 将\(n\)个蛋糕分成恰好\(k\)份, 求每份中包含的蛋糕的种类数之和的最大值. 这题有两种做法. 第一种是线段树优化dp, 我还没有考虑. 另一种就是分治+主席树. 然 ...
- Tomcat 在IE中下载rar文件直接以乱码方式打开解决方案
这几天一直很纳闷,在Tomcat部署的网站中的下载文件中,如果文件是rar类型的,一点击下载rar文件就直接打开,并且出现乱码,右键另存为浏览器也是默认为html格式,一直以为是浏览器IE的问题,后来 ...
- vue+cesiumjs的环境搭建【script引入】
[可以看我的博客里另外一篇----- import引入 ,可以不用script引入] 最近做项目要用到cesium,然后参照网上的一些步骤,最后发现报错了,其中有两种错比较多: ① This dep ...
- Java多线程常用方法的使用
Java多线程的常用方法基本分为:获取当前线程的操作,线程休眠sleep()方法,线程让步yield()方法,等待其他线程终止join()方法,线程停止的一系列方法. 一.获取当前线程的操作 1. ...
- python3-xlwt-Excel设置(字体大小、颜色、对齐方式、换行、合并单元格、边框、背景、下划线、斜体、加粗)
搬运出处: https://blog.csdn.net/weixin_44065501/article/details/88899257 # coding:utf-8 import patterns ...