hive 自定义函数(udf)
1.解压hive的压缩包
2.新建java项目,将hive压缩包里面lib文件夹的jar包导入新建的项目
3.编写java程序
package udfdemo;
import org.apache.hadoop.hive.ql.exec.UDF;
public class ToLower extends UDF{
public String evaluate(String field){
return field.toLowerCase();
}
}
注意:一定要继承UDF类
4.将项目作为jar包导出,注意将jar包也一并导出

5.将jar包上传到Linux
6.导入jar包
命令:add jar /root/tolower.jar;

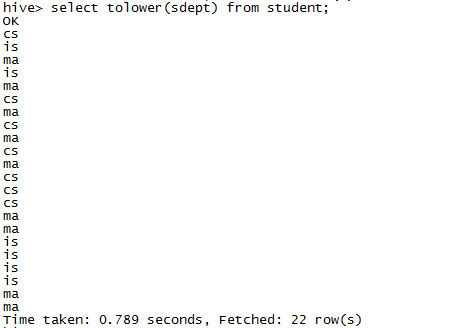
7.创建UDF函数并使用


hive 自定义函数(udf)的更多相关文章
- hive自定义函数UDF UDTF UDAF
Hive 自定义函数 UDF UDTF UDAF 1.UDF:用户定义(普通)函数,只对单行数值产生作用: UDF只能实现一进一出的操作. 定义udf 计算两个数最小值 public class Mi ...
- Hive自定义函数UDF和UDTF
UDF(user defined functions) 用于处理单行数据,并生成单个数据行. PS: l 一个普通UDF必须继承自“org.apache.hadoop.hive.ql.exec.UDF ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- Week08_day01 (Hive 自定义函数 UDF 一个输入,一个输出(最常用))
当我们进入企业就会发现,很多时候,企业的数据都是加密的,我们拿到的数据没办法使用Hive自带的函数去解决,我们就需要自己去定义函数去查看,哈哈,然而企业一般不会将解密的代码给你的,只需要会用,但是我们 ...
- 三 Hive 数据处理 自定义函数UDF和Transform
三 Hive 自定义函数UDF和Transform 开篇提示: 快速链接beeline的方式: ./beeline -u jdbc:hive2://hadoop1:10000 -n hadoop 1 ...
- 10_Hive自定义函数UDF
Hive官方的UDF手册地址是:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF 1.使用内置函数的快捷方法: 创 ...
- hive自定义函数(UDF)
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就 ...
- Hive自定义函数的学习笔记(1)
前言: hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到 ...
- hive -- 自定义函数和Transform
hive -- 自定义函数和Transform UDF操作单行数据, UDAF:聚合函数,接受多行数据,并产生一个输出数据行 UDTF:操作单个数据 使用udf方法: 第一种: add jar xxx ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
随机推荐
- 链表快排 & 基于链表的排序
以前只知道链表做插入(朴素.非二分)排序挺方便的.现在知道了(单)链表进行快速排序也是很好的(只是跟一般的快排的方式不一样). 参考: http://blog.csdn.net/otuhacker/a ...
- net_->ForwardBackward()的大致梳理
net_->ForwardBackward()方法在net.hpp文件中 Dtype ForwardBackward() { Dtype loss; Forward(&loss); Ba ...
- POJ 2607
一次FLOYD,再枚举. 注意题目要求的输出是什么哦. #include <iostream> #include <cstdio> #include <cstring&g ...
- [Javascript] Getter and Setter Abstractions
JavaScript provides primitive types and means of processing those. However, those are not enough. Re ...
- 多版本号并发控制(MVCC)在实际项目中的应用
近期项目中遇到了一个分布式系统的并发控制问题.该问题能够抽象为:某分布式系统由一个数据中心D和若干业务处理中心L1,L2 - Ln组成:D本质上是一个key-value存储,它对外提供基于HTTP协议 ...
- 百度2016研发project师笔试题(四)
百度2016研发project师笔试题(四) 2015/12/8 10:42(网上收集整理的,參考答案在后面.若有错误请大神指出) 1. 关于MapReduce的描写叙述错误的是() A. 一个Tas ...
- C++关键知识
<精通MFC>第一章节整理复习 //c++编程技术要点 /* //1.虚函数及多态的实现 //演示多态技术 #include <iostream> using namespac ...
- MEAN框架介绍
近期在Angular社区的原型开发人员间.一种全Javascript的开发架构MEAN正突然流行起来.其首字母分别代表的是:(M)ongoDB--NoSQL的文档数据库,使用JSON风格来存储数据,甚 ...
- HDU2034 人见人爱 A - B
2019-05-17 09:37:46 加油,加油 !!! 结果要从小到大输出 NULL后面没有空格 m && n == 0才结束 注意:看题仔细,罚时很严重 #include < ...
- Python笔记(九)
#encoding=utf-8 # python高级编程 # python面向对象 # 创建类 # 无意中把Visual Studio Code的窗口调小了,查了一下,可以使用Ctrl+=放大窗口,使 ...