使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地
上
篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy
目标:
爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地

好了不多说,让我们实现下效果
我们仍用scrapy框架来编写我们的项目:
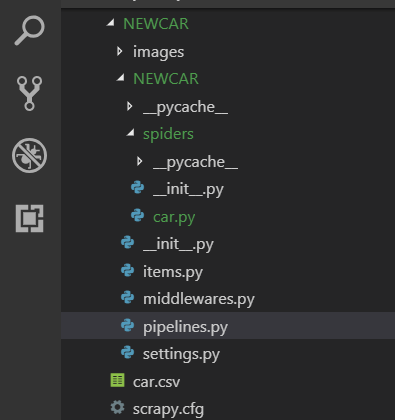
1.首先用命令创建一个爬虫项目(结合上篇博客),并到你的项目里如图所示
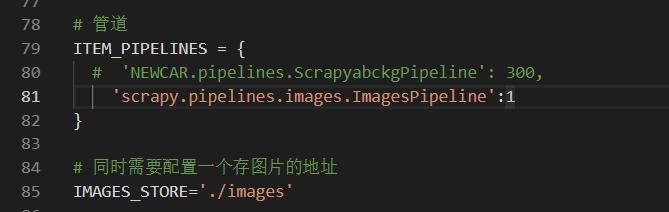
2.先到你的settings.py中配置 ,这里需要注意要 爬图(配置一个爬图管道 ImagesPipeline 为系统中下载图片的管道),
同时还有存图地址(在项目中创建一个为images的文件夹),
存图有多种方式,本人只是列举其中一种,大家可采取不同的方法
3.然后打开你的爬虫文件(即:car.py)开始编写你要爬取的数据,这里需要注意,要将start_urls[] 改为我们要爬取的Url 地址,然后根据xpath爬取图片
(这里代码得自己写,不要复制)

4.爬取的字段要跟 items.py里的一致

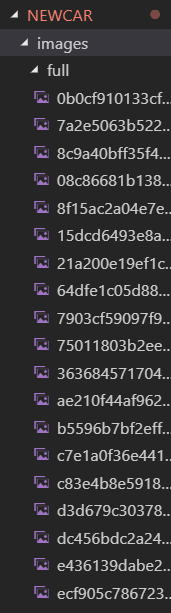
5.在命令行输入启动爬虫命令 scrapy crawl car 运行就能看到爬到图片存放在本地如下
6.最后入库,看你要入那个库,这里可入mysql和mongdb
mysql: 需提前创好库以及表,表中字段
import pymysql
# class NewcarPipeline(object):
# 连接mysql改为你的用户密码以及自己的库
# def __init__(self):
# self.conn = pymysql.connect(host='127.0.0.1',user='root', password='123456', db='zou')
# 建立cursor对象
# self.cursor = self.conn.cursor()
#
# 传值
# def process_item(self, item, spider):
# name = item['name']
# content = item['content']
# price = item['price']
# image = item['image_urls']
#
# insert into 你的表名,括号里面是你的字段要一一对应 # sql = "insert into zou(name,content,price) values(%s,%s,%s)"
# self.cursor.execute(sql, (name,content,price))
# self.conn.commit()
# return item
#关闭爬虫
# def close_spider(self, spider):
# self.conn.close()
mongdb: 不用提前建好库,表
from pymongo import MongoClient
# class NewcarPipeline(object):
# def open_spider(self, spider):
# # 连端口 ip
# self.con = MongoClient(host='127.0.0.1', port=27017)
# # 库
# db = self.con['p1']
# # 授权
# self.con = db.authenticate(name='wumeng', password='123456', source='admin')
# # 集合
# self.coll = db[spider.name] # def process_item(self, item, spider):
# # 添加数据
# self.coll.insert_one(dict(item))
# return item # def close_spider(self):
# # 关闭
# self.con.close()
7.运行 启动爬虫命令 scrapy crawl car 就可在库中看到数据.
至此爬虫项目做完了,这只是一个简单的爬虫,仅供参考,如遇其他方面的问题,可参考本人博客!尽情期待!
使用Scrapy爬取图片入库,并保存在本地的更多相关文章
- scrapy 爬取图片
scrapy 爬取图片 1.scrapy 有下载图片的自带接口,不用我们在去实现 setting.py设置 # 保存log信息的文件名 LOG_LEVEL = "INFO" # L ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- 【Python】- scrapy 爬取图片保存到本地、且返回保存路径
https://blog.csdn.net/xueba8/article/details/81843534
- scrapy爬取图片并自定义图片名字
1 前言 Scrapy使用ImagesPipeline类中函数get_media_requests下载到图片后,默认的图片命名为图片下载链接的哈希值,例如:它的下载链接是http://img.iv ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
随机推荐
- 安卓手机可以连上wifi但无法上网的解决办法
作者:朱金灿 来源:http://blog.csdn.net/clever101 前晚我的安卓手机还可以连接wifi上网,昨晚显示已经连接,但是死活打不开网页.于是到网上查了下,发现要将原来的DHCP ...
- 《Facebook效应》
前两年风靡了一阵子的电影<社交网络>毕竟是电影,一种艺术的方式的表达.虽然无法完全的印证<Facebook 效应>一书中记载的正确性,但其细节足以给人启示. 电影中,主人公炫酷 ...
- 买不起360随声wifi怎么办?这些都不是问题
只需轻松一步,点击开启共享 软件下载地址:http://download.csdn.net/detail/lxq_xsyu/6384265 如果身边没有数据线怎么办?? 使用方法: 1.用手机连接Wi ...
- C#中的interface没那么简单
最近在园子里闲逛看到一篇文章“(抽象)类和接口细节分析”,尽管作者很细心很细致.可事实上C#里面的interface没那么简单,interface有着大量不为人知的小秘密的说. 1.值类型也能实现接口 ...
- Swift 分类 结构体
感谢原作者:http://www.cocoachina.com/newbie/basic/2014/0612/8780.html 类和结构体是人们构建代码所用的一种通用且灵活的构造体.为了在类和结构体 ...
- s3c2410 cs8900a 网卡驱动程序
/* CS8900a.h */ #define CONFIG_CERF_CS8900A 1 /* * cs8900a.c: A Crystal Semiconductor (Now Cirrus Lo ...
- ude—基于udp的全双工可靠传输协议
ude是一款基于udp的可靠传输协议,专门用于在数据传输方面对实时性要求较高的应用领域. tcp协议虽然能保证数据的可靠传输,但它有以下几个缺点:1.tcp的数据确认机制会导致发送方重复发送一些 ...
- bootstrap学习之路
接触bootstrap也半年有余,从一开始不知道如何使用,到知道其各个模块的具体功能,再到提炼哪些使用的比较多,再此又体会到bootstrap源码的精髓,通过oocss写的类使其感觉更有易用性,开始本 ...
- TL9000 电信业质量体系管理标准
1.背景介绍:1987年国际标准化组织创立了ISO9000标准.标准发布后,在世界范围内得到了迅速的推广和广泛的认可,成为全世界衡量质量管理水平与质量保证能力的公共标准.九十年代,美国三大汽车公司和航 ...
- Hibernate4与hibernate3有错误的版本号的主要区别所造成的不一致
Hibernate版本号修改 Hibernate4的修改较大仅仅有spring3.1以上版本号可以支持,Spring3.1取消了HibernateTemplate,由于Hibernate4的事务管理已 ...