MySQL Cluster --01
MySQL Cluster 是MySQL 官方集群部署方案, 支持自动分片、读写扩展;通过实时备份冗余数据。适合于分布式计算环境的高实用、高冗余版本,是可用性最高的方案,官方声称可做到99.999%的可用性。MySQL Cluster采用NDB Cluster 存储引擎,包括MySQL服务器、NDB Cluster数据节点、管理服务器,以及(可能)专门的数据访问程序。
NDB 是一种“内存中”的存储引擎,它具有可用性高和数据一致性等特点。
实际上,MySQL集群是把NDB 内存集群存储引擎与标准的MySQL服务器集成。它包含一组计算机,每个都跑一个或者多个进程,这可能包括一个MySQL服务器,一个数据节点,一个管理服务器和一个专有的数据访问程序。
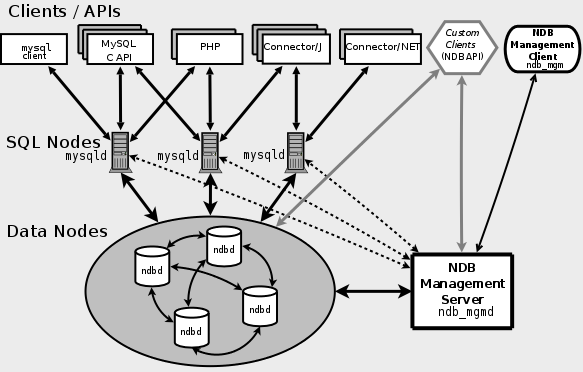
MySQL cluster配置中,由3个不同功能的服务构成,每个服务由一个专用的守护进程提供,一项服务也叫做一个节点,下面来介绍每个节点的功能:
一、管理(MGM)节点
MGM节点作用是管理MySQL Cluster内的其他节点,如提供配置数据、启动并停止节点、运行备份等。由于这类节点负责管理其他节点的配置,应在启动其他节点之前首先启动这类节点。理论上一般只启动一个,而且宕机也不影响 cluster 的服务,这个进程只在cluster 启动以及节点加入集群时起作用, 所以这个节点不是很需要冗余,理论上通过一台服务器提供服务就可以了。
管理服务器(MGM节点)负责管理 Cluster配置文件和 Cluster日志。 Cluster中的每个节点从管理服务器检索配置数据,并请求确定管理服务器所在位置的方式。当数据节点内出现新的事件时,节点将关于这类事件的信息传输到管理服务器,然后,将这类信息写入 Cluster日志。
二、数据节点
用于保存 Cluster的数据。数据节点的数目与副本的数目相关,是片段的倍数,分段的数目为节点总数除以NoOfReplicas 所得。例如,对于两个副本,每个副本有两个片段,那么就有4个数据节点,通常设置为两副本,两个以上时就能实现集群的高可用保证,数据副本节点增加时,集群的处理速度会变慢。
数据更新使用读已提交隔离级别(read-committed isolation)来保证所有节点数据的一致性,使用两阶段提交机制(two-phased commit:节点组内主从同步采用同步复制),保证所有节点都有相同的数据(如果任何一个写操作失败,则更新失败)。
无共享的对等节点使得某台服务器上的更新操作在其他服务器上立即可见。传播更新使用一种复杂的通信机制,这一机制专用来提供跨网络的高吞吐量。
Mysqlcluster将所有的索引列都保存在主存中,其他非索引列可以存储在内存中或者通过建立表空间存储到磁盘上。
如果数据发生改变(insert,update,delete等),mysql 集群将发生改变的记录写入重做日志,然后通过检查点定期将数据定入磁盘。由于重做日志是异步提交的,所以故障期间可能有少量事务丢失。为了减少事务丢失,mysql集群实现延迟写入(默认延迟两秒,可配置),这样就可以在故障发生时完成检查点写入,而不会丢失最后一个检查点。一般单个数据节点故障不会导致任何数据丢失,因为集群内部采用同步数据复制。
由于同步复制一共需要4次消息传递,故mysql cluster的数据更新速度比单机mysql要慢。所以mysql cluster要求运行在千兆以上的局域网内,节点可以采用双网卡,节点组之间采用直连方式。
对cluster进行扩容增加数据节点组时不会导致数据更新速度降低。相反,数据更新速度会变快,因为数据是分别处理,每个节点组所保存的数据是不一样的,也能减少锁定。
三、SQL节点
用来访问 Cluster数据的节点。对于MySQL Cluster,客户端节点是使用NDB Cluster存储引擎的传统MySQL服务器。Cluster中可以有多个sql节点,通过每个sql节点查询到的数据都是一致的,通常来说,sql节点越多,分配到每个sql节点的负载就越小,系统的整体性能就越好。
所有的这些节点构成一个完成的MySQL集群体系: 数据保存在“NDB存储服务器”的存储引擎中,表(结构)则保存在“MySQL服务器”中。应用程序通过“MySQL服务器”访问这些数据表,集群管理服务器通过管理工具(ndb_mgmd)来管理“NDB存储服务器”。
通过将MySQL Cluster 引入开放源码世界,MySQL为所有需要它的人员提供了具有高可用性、高性能和可缩放性的 Cluster 数据管理。
【NDB存储引擎】
MySQL Cluster 使用了一个专用的基于内存的存储引擎NDB,这样做的好处是速度快, 没有磁盘I/O的瓶颈,但是由于是基于内存的,所以数据库的规模受系统总内存的限制, 如运行NDB的MySQL服务器一定要内存够大,比如4G, 8G, 甚至16G。NDB引擎是分布式的,它可以配置在多台服务器上来实现数据的可靠性和扩展性,理论上 通过配置2台NDB的存储节点就能实现整个数据库集群的冗余性和解决单点故障问题。
在ndb上可以建立两种类型的表:
1、内存表:所有数据(包括index)都在内存中。同时会在磁盘上保存数据,因此不用担心数据会丢失,datanode会在启动的时候把数据加载到内存。
2、磁盘表:仅主键、索引字段保存在内存中,其他字段保存在磁盘文件里。
MySQL Cluster 特性
- 通过自动分片实现高水平的写入扩展能力:MySQL Cluster 自动将表分片(或分区)到不同节点上,使数据库可以在低成本的商用硬件上横向扩展,同时保持对应用程序完全应用透明。
- 99.999% 的可用性:凭借其分布式、无共享架构,MySQL Cluster 可提供 99.999% 的可用性,确保了较强的故障恢复能力和在不停机的情况下执行预定维护的能力。
- SQL 和NoSQL API:MySQL Cluster 让用户可以在解决方案中整合关系数据库技术和NoSQL技术中的最佳部分,从而降低成本、风险和复杂性。
- 实时性能:MySQL Cluster 提供实时的响应时间和吞吐量,能满足最苛刻的 Web、电信及企业应用程序的需求。
- 具有跨地域复制功能的多站点集群:跨地域复制使多个集群可以分布在不同的地点,从而提高了灾难恢复能力和全球 Web 服务的扩展能力。
- 联机扩展和模式升级:为支持持续运营,MySQL Cluster 允许向正在运行的数据库模式中联机添加节点和更新内容,因而能支持快速变化和高度动态的负载。
缺点
- 基于内存,数据库的规模受集群总内存的大小限制,重启时,数据节点将数据load到内存耗时较长
- 多个节点通过网络实现通讯和数据同步、查询等操作,因此整体性受网络速度影响
MySQL Cluster --01的更多相关文章
- MySQL Cluster 数据分布(分区、分组)
数据分布 1.MySQL Cluster自动分区数据表(也可能使用用户自定义分区),将数据分布到分区中: 2.一个数据表被划分到多个Data Node分区中,数据在分区中被”striped”: 3.主 ...
- MySQL Cluster搭建与测试
MySQL Cluster是一个基于NDB Cluster存储引擎的完整的分布式数据库系统.不仅仅具有高可用性,而且可以自动切分数据,冗余数据等高级功能.和Oracle Real Cluster Ap ...
- mysql集群 MySQL Cluster
<?php /* 郑重说明2015年6月11日16:28:14,目前为止MySQL Cluster 社区版不支持INNODB,商业版支持,但是授权价格20W左右,so看此文档之前,考虑下钱 My ...
- Windows Server 2008R2配置MySQL Cluster
目录 配置环境 相关知识 配置过程 配置 ini参数解释 启动集群 检查配置 同步测试 故障测试 写在之后 配置环境 VMware:(版本10.0.01) 操作系统:Windows Server 20 ...
- MySQL Cluster 集群
本文转载 http://www.cnblogs.com/gomysql/p/3664783.html MySQL Cluster是一个基于NDB Cluster存储引擎的完整的分布式数据库系统.不仅仅 ...
- mysql集群之MYSQL CLUSTER
1. 参考文档 http://xuwensong.elastos.org/2014/01/13/ubuntu-%E4%B8%8Bmysql-cluster%E5%AE%89%E8%A3%85%E5%9 ...
- 转centos65安装简测mysql cluster 7.3.7
MySQLCluster是sharednothing分布式架构,ndb存储引擎把数据放置于内存中.可以做到无单点故障.由运行于不同服务器上的的多种进程构成,组件包括SQL节点,NDBD数据节点,管理程 ...
- MySQL Cluster测试过程中的错误汇总--ERROR 1296 (HY000)等等
参考资料: http://dev.mysql.com/doc/refman/5.1/en/mysql-cluster-privilege-distribution.html http://www.cl ...
- Installation and Configuration MySQL Cluster 7.2 on CentOS 5 (include MySQL 5.5)
Architecture Manager Node mysql-mag1 192.168.1.31 mysql-mag2 192.168.1.32 SQL Node mysql-sql1 ...
随机推荐
- ReentrantLock的底层实现机制 AQS
ReentrantLock的底层实现机制是AQS(Abstract Queued Synchronizer 抽象队列同步器).AQS没有锁之类的概念,它有个state变量,是个int类型,为了好理解, ...
- python3_ftp多线程上传图片
项目中研发人员自己写了ftp服务,没有标准ftp中的列表,准备用jmeter对ftp压力测试时发现jmeter要验证列表(如果有同学用jmeter测试过类似的分享一下方法谢谢了),没办法只能用pyth ...
- 在vue项目中使用codemirror插件实现代码编辑器功能(代码高亮显示及自动提示
在vue项目中使用codemirror插件实现代码编辑器功能(代码高亮显示及自动提示) 1.使用npm安装依赖 npm install --save codemirror; 2.在页面中放入如下代码 ...
- Vuejs开发环境搭建及热更新
一.安装NPM 1.1最新稳定版本: npm install vue 二.命令行工具安装 国内速度慢,使用淘宝镜像: npm install -g cnpm --registry=https://re ...
- Web安全学习笔记之Nmap扫描原理与用法
1 Nmap介绍 Nmap扫描原理与用法PDF:下载地址 Nmap是一款开源免费的网络发现(Network Discovery)和安全审计(Security Auditing)工具.软件名字N ...
- path.join()和path.resolve()的区别
现在写代码的时候有时候使用path.join(__dirname,'dist')有时候用path.resolve(__dirname,'dist'),都是能拼接处来一个绝对路径,但是具体有什么区别呢? ...
- LVS-net
一.LVS基本情况 lvs:Linux Virtual Server,是一种负载均衡集群,其主要是由工作在内核的ipvs与用户空间的命令行工具ipvsadm组成.支持TCP,UDP,AH,EST,AH ...
- mybatis中的映射类型
- 解决github访问慢的问题
在windows hosts文件末尾增加以下内容 # GitHub Start 192.30.253.112 github.com 192.30.253.119 gist.github.com 151 ...
- 【cs231n】最优化笔记
): W = np.random.randn(10, 3073) * 0.0001 # generate random parameters loss = L(X_train, Y_train, W) ...