TensorFlow数据集(一)——数据集的基本使用方法
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: dataset_test1.py
@time: 2019/2/10 10:52
@desc: 例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值。
""" import tensorflow as tf # 从一个数组创建数据集。
input_data = [1, 2, 3, 5, 8]
dataset = tf.data.Dataset.from_tensor_slices(input_data) # 定义一个迭代器用于遍历数据集。因为上面定义的数据集没有用placeholder作为输入参数
# 所以这里可以使用最简单的one_shot_iterator
iterator = dataset.make_one_shot_iterator()
# get_next() 返回代表一个输入数据的张量,类似于队列的dequeue()。
x = iterator.get_next()
y = x * x with tf.Session() as sess:
for i in range(len(input_data)):
print(sess.run(y))
运行结果:
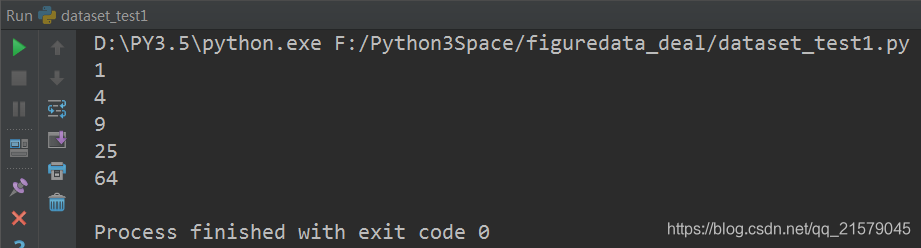

数据是文本文件:创建数据集。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: dataset_test2.py
@time: 2019/2/10 11:03
@desc: 数据是文本文件
""" import tensorflow as tf # 从文本文件创建数据集。假定每行文字是一个训练例子。注意这里可以提供多个文件。
input_files = ['./input_file11', './input_file22']
dataset = tf.data.TextLineDataset(input_files) # 定义迭代器用于遍历数据集
iterator = dataset.make_one_shot_iterator()
# 这里get_next()返回一个字符串类型的张量,代表文件中的一行。
x = iterator.get_next()
with tf.Session() as sess:
for i in range(4):
print(sess.run(x))
运行结果:
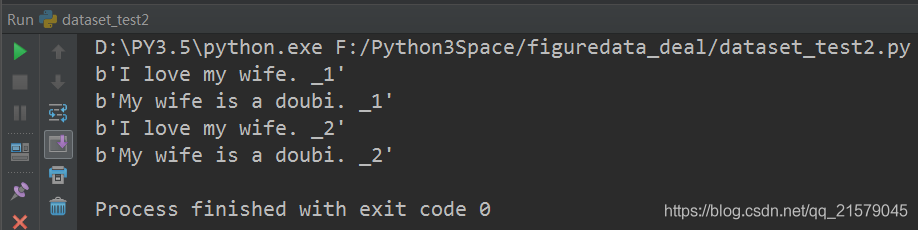
数据是TFRecord文件:创建TFRecord测试文件。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: dataset_createdata.py
@time: 2019/2/10 13:59
@desc: 创建样例文件
""" import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import time # 生成整数型的属性。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 生成字符串型的属性。
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) a = [11, 21, 31, 41, 51]
b = [22, 33, 44, 55, 66] # 输出TFRecord文件的地址
filename = './input_file2'
# 创建一个writer来写TFRecord文件
writer = tf.python_io.TFRecordWriter(filename)
for index in range(len(a)):
aa = a[index]
bb = b[index]
# 将一个样例转化为Example Protocol Buffer,并将所有的信息写入这个数据结构。
example = tf.train.Example(features=tf.train.Features(feature={
'feat1': _int64_feature(aa),
'feat2': _int64_feature(bb)
})) # 将一个Example写入TFRecord文件中。
writer.write(example.SerializeToString())
writer.close()
运行结果:
数据是TFRecord文件:创建数据集。(使用最简单的one_hot_iterator来遍历数据集)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: dataset_test3.py
@time: 2019/2/10 13:16
@desc: 数据是TFRecord文件
""" import tensorflow as tf # 解析一个TFRecord的方法。record是从文件中读取的一个样例。前面介绍了如何解析TFRecord样例。
def parser(record):
# 解析读入的一个样例
features = tf.parse_single_example(
record,
features={
'feat1': tf.FixedLenFeature([], tf.int64),
'feat2': tf.FixedLenFeature([], tf.int64),
}
)
return features['feat1'], features['feat2'] # 从TFRecord文件创建数据集。
input_files = ['./input_file1', './input_file2']
dataset = tf.data.TFRecordDataset(input_files) # map()函数表示对数据集中的每一条数据进行调用相应方法。使用TFRecordDataset读出的是二进制的数据。
# 这里需要通过map()函数来调用parser()对二进制数据进行解析。类似的,map()函数也可以用来完成其他的数据预处理工作。
dataset = dataset.map(parser) # 定义遍历数据集的迭代器
iterator = dataset.make_one_shot_iterator() # feat1, feat2是parser()返回的一维int64型张量,可以作为输入用于进一步的计算。
feat1, feat2 = iterator.get_next() with tf.Session() as sess:
for i in range(10):
f1, f2 = sess.run([feat1, feat2])
print(f1, f2)
运行结果:
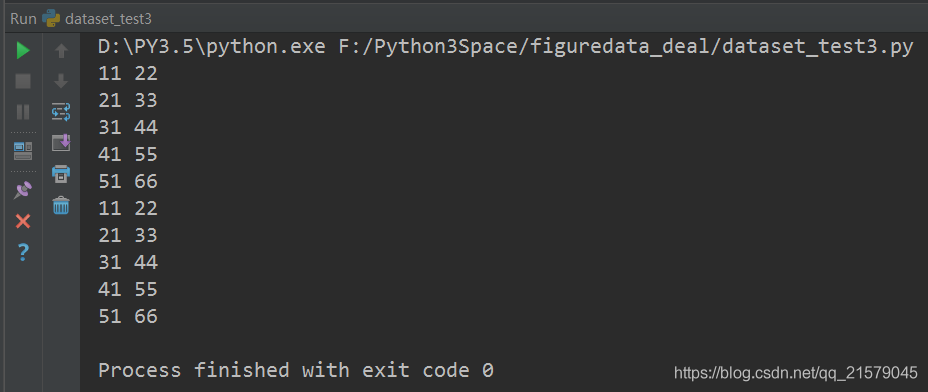
数据是TFRecord文件:创建数据集。(使用placeholder和initializable_iterator来动态初始化数据集)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: dataset_test4.py
@time: 2019/2/10 13:44
@desc: 用initializable_iterator来动态初始化数据集的例子
""" import tensorflow as tf
from figuredata_deal.dataset_test3 import parser # 解析一个TFRecord的方法。与上面的例子相同不再重复。
# 从TFRecord文件创建数据集,具体文件路径是一个placeholder,稍后再提供具体路径。
input_files = tf.placeholder(tf.string)
dataset = tf.data.TFRecordDataset(input_files)
dataset = dataset.map(parser) # 定义遍历dataset的initializable_iterator
iterator = dataset.make_initializable_iterator()
feat1, feat2 = iterator.get_next() with tf.Session() as sess:
# 首先初始化iterator,并给出input_files的值。
sess.run(iterator.initializer, feed_dict={input_files: ['./input_file1', './input_file2']}) # 遍历所有数据一个epoch,当遍历结束时,程序会抛出OutOfRangeError
while True:
try:
sess.run([feat1, feat2])
except tf.errors.OutOfRangeError:
break
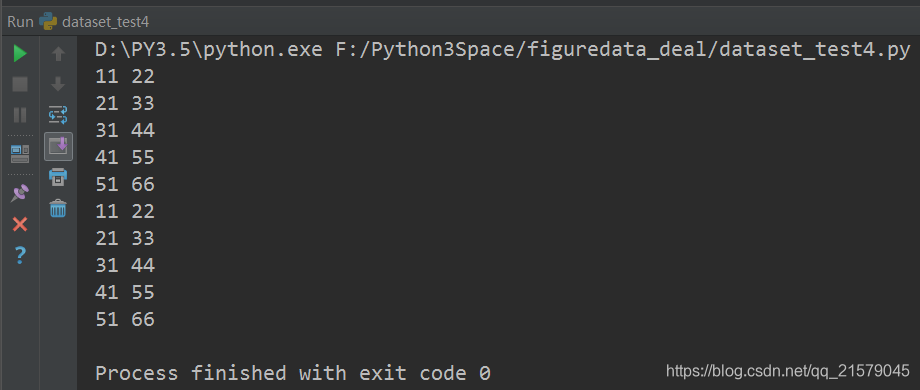
运行结果:
TensorFlow数据集(一)——数据集的基本使用方法的更多相关文章
- 一个简单的TensorFlow可视化MNIST数据集识别程序
下面是TensorFlow可视化MNIST数据集识别程序,可视化内容是,TensorFlow计算图,表(loss, 直方图, 标准差(stddev)) # -*- coding: utf-8 -*- ...
- 获取器操作都是针对数据而不是数据集的,要通过append()方法添加数据表不存在的字段
获取器操作都是针对数据而不是数据集的,要通过append()方法添加数据表不存在的字段 public function getMembership(){ //加入会员s_id = 1 $busines ...
- tensorflow实现基于LSTM的文本分类方法
tensorflow实现基于LSTM的文本分类方法 作者:u010223750 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实 ...
- Tensorflow读取大数据集的方法,tf.train.string_input_producer()和tf.train.slice_input_producer()
1. https://blog.csdn.net/qq_41427568/article/details/85801579
- 学习笔记TF056:TensorFlow MNIST,数据集、分类、可视化
MNIST(Mixed National Institute of Standards and Technology)http://yann.lecun.com/exdb/mnist/ ,入门级计算机 ...
- 深度学习原理与框架-Tensorflow基本操作-mnist数据集的逻辑回归 1.tf.matmul(点乘操作) 2.tf.equal(对应位置是否相等) 3.tf.cast(将布尔类型转换为数值类型) 4.tf.argmax(返回最大值的索引) 5.tf.nn.softmax(计算softmax概率值) 6.tf.train.GradientDescentOptimizer(损失值梯度下降器)
1. tf.matmul(X, w) # 进行点乘操作 参数说明:X,w都表示输入的数据, 2.tf.equal(x, y) # 比较两个数据对应位置的数是否相等,返回值为True,或者False 参 ...
- TensorFlow 训练MNIST数据集(2)—— 多层神经网络
在我的上一篇随笔中,采用了单层神经网络来对MNIST进行训练,在测试集中只有约90%的正确率.这次换一种神经网络(多层神经网络)来进行训练和测试. 1.获取MNIST数据 MNIST数据集只要一行代码 ...
- 基于 tensorflow 的 mnist 数据集预测
1. tensorflow 基本使用方法 2. mnist 数据集简介与预处理 3. 聚类算法模型 4. 使用卷积神经网络进行特征生成 5. 训练网络模型生成结果 how to install ten ...
- 《Hands-On Machine Learning with Scikit-Learn&TensorFlow》mnist数据集错误及解决方案
最近在看这本书看到Chapter 3.Classification,是关于mnist数据集的分类,里面有个代码是 from sklearn.datasets import fetch_mldata m ...
- 基于TensorFlow的MNIST数据集的实验
一.MNIST实验内容 MNIST的实验比较简单,可以直接通过下面的程序加上程序上的部分注释就能很好的理解了,后面在完善具体的相关的数学理论知识,先记录在这里: 代码如下所示: import tens ...
随机推荐
- Qtree3
题目描述 给出N个点的一棵树(N-1条边),节点有白有黑,初始全为白 有两种操作: 0 i : 改变某点的颜色(原来是黑的变白,原来是白的变黑) 1 v : 询问1到v的路径上的第一个黑点,若无,输出 ...
- sdut oj 3058 路线冲突问题(BFS+记录路径算法,回溯路径 )
路线冲突问题 题目描述 给出一张地图,地图上有n个点,任意两点之间有且仅有一条路.点的编号从1到n. 现在兵团A要从s1到e1,兵团B要从s2到e2,问两条路线是否会有交点,若有则输出交点个数,否出输 ...
- ansible操作模块相关
1. 查看模块可用参数命令 ansible-doc -s module_name
- java反射技术实例
java反射技术实例1. [代码][Java]代码 package com.gufengxiachen.java.reflectiontest; public class Person {p ...
- Python:递归
递归两个基本要素: (1) 边界条件:确定递归到何时终止,也称为递归出口. (n = 1)(2) 递归模式:大问题是如何分解为小问题的,也称为递归体.(n*(n-1)! n>1) 例:累加 ...
- I.MX6 Surfaceflinger 机制
/**************************************************************************** * I.MX6 Surfaceflinger ...
- 初学Java(一)
基本语法: 编写Java程序时,应注意以下几点: 1.大小写敏感:java是大小写敏感的,这就意味着标识符Hello与hello是不同的. 2.类名:对于所有的类来说,类名的首字母应该大写.如果类名由 ...
- yolo-开源数据集coco kitti voc
1.kitti数据集(参考博客:https://blog.csdn.net/jesse_mx/article/details/65634482 https://blog.csdn.net/baoli ...
- Quicklz压缩算法
以前对压缩算法一无所知,只是知道哈弗曼编码能做这种事情,但是感觉这样的方法奇慢无比.昨天下午看了下号称世界上最快的压缩算法Quicklz,对压缩的基本思路有了一定的了解.一般的压缩程序的要求读入文件之 ...
- TCP 错误代码 10013: 试图以其访问权限所禁止的方式访问套接字
大家遇到的问题可能是登录没反应,这时,大家要充分利用调试工具,调试工具可能会提示下面错误: 未能连接到 net.tcp://swk-pc:4502/chatservice.svc.连接尝试的持续时间为 ...