【六】强化学习之DQN---PaddlePaddlle【PARL】框架{飞桨}
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
代码链接:码云:https://gitee.com/dingding962285595/parl_work ;github:https://github.com/PaddlePaddle/PARL
1.前言铺垫
1.1值函数近似
用带参数的Q函数近似,比如使用:多项式函数,神经网络来代替Q表格。
这里近似可以有不同类别,如上图输入一个状态s和动作a得到一个q值,或者只输入状态s,有多少个动作就输出多少个Q值,右边容易求解最大Q值。
表格法的缺点: 使用值函数近似的优点:
➊表格可能占用极大内存 ➊仅需存储有限的参数
②当表格极大时,查表效率低下 ②状态泛化,相似的状态可以输出一样神经网络可以逼近任意连续函数
线性加权+激活函数 就可以拟合非线性函数。
这是一个简单的线性回归模型,来帮助我们快速求解4元一次方程。



代码对应如下:
#加载库
import paddle.fluid as fluid
import numpy as np
#生成数据
np.random.seed(0)
outputs = np.random.randint(5, size=(10, 4))
res = []
for i in range(10):
# 假设方程式为 y=4a+6b+7c+2d
y = 4*outputs[i][0]+6*outputs[i][1]+7*outputs[i][2]+2*outputs[i][3]
res.append([y])
# 定义数据
train_data=np.array(outputs).astype('float32')
y_true = np.array(res).astype('float32')
#定义网络
x = fluid.layers.data(name="x",shape=[4],dtype='float32')
y = fluid.layers.data(name="y",shape=[1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)
#定义损失函数
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
avg_cost = fluid.layers.mean(cost)
#定义优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.05)
sgd_optimizer.minimize(avg_cost)
#参数初始化
cpu = fluid.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
##开始训练,迭代500次
for i in range(500):
outs = exe.run(
feed={'x':train_data,'y':y_true},
fetch_list=[y_predict.name,avg_cost.name])
if i%50==0:
print ('iter={:.0f},cost={}'.format(i,outs[1][0]))
#存储训练结果
params_dirname = "result"
fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe)
# 开始预测
infer_exe = fluid.Executor(cpu)
inference_scope = fluid.Scope()
# 加载训练好的模型
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe)
# 生成测试数据
test = np.array([[[9],[5],[2],[10]]]).astype('float32')
# 进行预测
results = infer_exe.run(inference_program,
feed={"x": test},
fetch_list=fetch_targets)
# 给出题目为 【9,5,2,10】 输出y=4*9+6*5+7*2+10*2的值
print ("9a+5b+2c+10d={}".format(results[0][0]))
得到结果:
9a+5b+2c+10d=[99.946]
输出结果应是一个近似等于100的值,每次计算结果略有不同。
2.DQN
先回顾一下Qlearing

1.首先查表所有动作对应q值取出来,最有动作就是q值最大对应动作,2.在输出给环境,然后输出r和下一状态s Q(s,a)函数逼近目标值target,maxQ来更新。当然也用sample进行探索。

DQN改进就是用神经网络替代Q表格。

3.DQN创新点

- 本质上
DQN还是一个Q-learning算法,更新方式一致。为了更好的探索环境,同样的也采用ε-greedy方法训练。 - 在
Q-learning的基础上,DQN提出了两个技巧使得Q网络的更新迭代更稳定。- 经验回放
Experience Replay:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s',再从中随机抽取一批数据送去训练。 - 固定Q目标
Fixed-Q-Target:主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值。
- 经验回放
是预测的q和targetQ相近,通过loss更新神经网络。

2.1 经验回放
import random
import collections #导入队列库,可以定义经验池队列
import numpy as np class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size) #长度就是经验池容量 def append(self, exp):
self.buffer.append(exp)#增加一条经验(obs, action, reward, next_obs, done )
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], [] for experience in mini_batch: #每一条batch分解一下,加到对应数组里
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done) return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32') def __len__(self):
return len(self.buffer)
2.2 固定Q目标

2.3 DQN流程

在parl里面单独把DQN算法提取出来

4.PARL的架构DQN详细讲解如下:

可以比较方便的应用在其他深度学习环境下。这样的算法看起来会比较整洁5个文件:

Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL这种架构可以很方便的应用在各类深度强化学习问题中。
4.1 model:
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构。

4.2 algorithm:
Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。

将model的参数同步到target_model中,调用这个API就好。

预测:

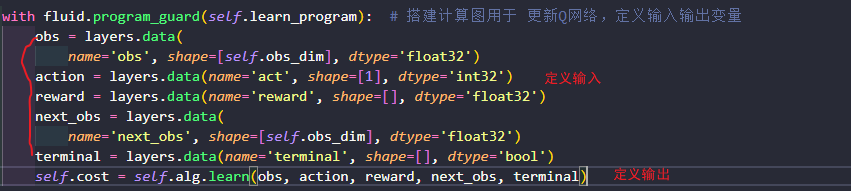
4.3 learn():
target Q计算公式 和Qlearing一样,if episode是最后一个则没有下一个状态,就是当前reward。

分成三部分,得到Q目标值、在获取预测值,最后得到LOSS。
阻止梯度传递,target_q 用到的是target_model的值,而target_model的值需要固定不动的,所以切断联系,避免优化器找到所有和cost有关的参数进行一起优化。
- 小技巧:terminal就是done,

这行代码把if else都写出来了,如果是true就是1 false就是0

true的话就是1,后项式整体为0.
- pred_value拿到的是pred_value = [[2.3, 5.7, 1.2, 3.9, 1.4]],拿到所有a对应的Q了,然后把Q先转换到onehot向量3 => [0,0,0,1,0] 2 => [0,0,1,0,0]

安位相乘再相加,就得到3.9了。即Q(s,a)

计算均方差、在用adm优化器优化。
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。

每200step同步一次网络。

每运行一次run就完成一次网络的更新。
获取计算Q值
with fluid.program_guard(self.pred_program): # 搭建计算图用于 预测动作,定义输入输出变量
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
self.value = self.alg.predict(obs)
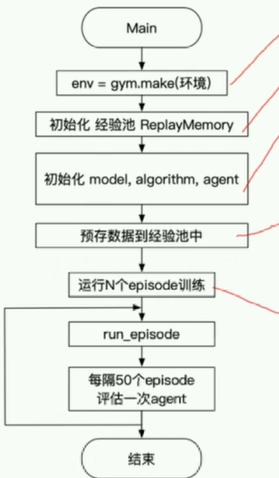
5.cartpole测试

5.1 main.py 代码流程图体现:
每训练50个episode,评估5次【多次】再求平均,避免偶然性。
训练时运行learn更新Q算法。
render为true,则显示需打印内容,等于设置了一个标记。



6.PARL常用APi

7.总结:

软更新:应该是指每次更新参数的时候利用一个衰减的比例
硬更新:则是指每隔一定步数完全Copy参数
【六】强化学习之DQN---PaddlePaddlle【PARL】框架{飞桨}的更多相关文章
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 谷歌重磅开源强化学习框架Dopamine吊打OpenAI
谷歌重磅开源强化学习框架Dopamine吊打OpenAI 近日OpenAI在Dota 2上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不 ...
- 谷歌推出新型强化学习框架Dopamine
今日,谷歌发布博客介绍其最新推出的强化学习新框架 Dopamine,该框架基于 TensorFlow,可提供灵活性.稳定性.复现性,以及快速的基准测试. GitHub repo:https://git ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 强化学习(十)Double DQN (DDQN)
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性.但是还是有其他 ...
随机推荐
- 🔥 DeepVideo 智能视频生产训练营火热报名中!
阿里云视频云和阿里云开发者学堂联合打造 国内首个视频云训练营11月8日启幕 四天直播,技术大咖亲临授课干货 全面介绍视频智能生产技术和产品 帮助开发者迅速入门视频云 已超千人报名,丰富打卡玩法礼品 活 ...
- Woodpecker CI 设计分析|一个 Go 编写的开源持续集成引擎
一.前言 大家好,这里是白泽.随着 Go 语言在云原生领域大放异彩,开发者逐渐将目光转移到了这门语言上,而容器则是云原生时代最核心的载体. <Woodpecker CI 设计分析>系列文章 ...
- 区间DP练习题题解
算法讲解:Here AcWing 282. 石子合并 (模板) 题目链接:Here const int N = 310; int a[N], s[N]; int dp[N][N]; void solv ...
- 2018年第九届 蓝桥杯A组 C/C++决赛题解
蓝桥杯历年国赛真题汇总:Here 1.三角形面积 已知三角形三个顶点在直角坐标系下的坐标分别为: (2.3, 2.5) (6.4, 3.1) (5.1, 7.2) 求该三角形的面积. 注意,要提交的是 ...
- 如果很好说出finalize用法,面试官会认为你很资深
我在面试Java候选人的时候,有时候会通过finalize问及候选人在JVM方面的技能,一般的问法是:你知不知道finalize方法,在项目里有没有重写过这个方法?在本文里就将详细来说下这个知识点. ...
- 七、mycat-ER分片
系列导航 一.Mycat实战---为什么要用mycat 二.Mycat安装 三.mycat实验数据 四.mycat垂直分库 五.mycat水平分库 六.mycat全局自增 七.mycat-ER分片 一 ...
- 深度学习(三)——Transforms的使用
一.Transforms的结构及用法 导入transforms from torchvision import transforms 作用:图片输入transforms后,可以得到一些预期的变换 1. ...
- ICDM'23 BICE论文解读:基于双向LSTM和集成学习的模型框架
本文分享自华为云社区<ICDM'23 BICE论文解读>,作者:云数据库创新Lab. 导读 本文<Efficient Cardinality and Cost Estimation ...
- AHB 局限性
AHB's problem SoC bus 架构 AXI is used more and more 频率200M使用AHB,频率再升高就使用AXI AHB的问题 AHB协议本身限制要求较高,比如co ...
- 【C++】const 常类型
常引用 格式:const 类型说明符 &引用名 注意:常引用所引用的对象不能修改 常对象 格式:类名 const 对象名 或 const 类名 对象名 注意:常对象其数据成员在生存期内不能修改 ...