第二十七篇 玩转数据结构——集合(Set)与映射(Map)
- 集合可以用来去重
- 集合可以用于进行客户的统计
- 集合可以用于文本词汇量的统计
- 定义集合的接口
Set<E>
·void add(E) // 不能添加重复元素
·void remove(E)
·boolean contains(E)
·int getSize()
·boolean isEmpty()集合接口的业务逻辑如下:
public interface Set<E> { void add(E e); void remove(E e); boolean contains(E e); int getSize(); boolean isEmpty();
}- 用二分搜索树作为集合的底层实现
public class BSTSet<E extends Comparable<E>> implements Set<E> { private BST<E> bst; // 构造函数
public BSTSet() {
bst = new BST<>();
} // 实现getSize方法
@Override
public int getSize() {
return bst.size();
} // 实现isEmpty方法
@Override
public boolean isEmpty() {
return bst.isEmpty();
} // 实现contains方法
@Override
public boolean contains(E e) {
return bst.contains(e);
} // 实现add方法
public void add(E e) {
bst.add(e);
} // 实现remove方法
public void remove(E e) {
bst.remove(e);
}
}- 用链表作为集合的底层实现
public class LinkedListSet<E> implements Set<E> { private LinkedList<E> list; // 构造函数
public LinkedListSet() {
list = new LinkedList<>();
} // 实现getSize方法
@Override
public int getSize() {
return list.getSize();
} // 实现isEmpty方法
@Override
public boolean isEmpty() {
return list.isEmpty();
} // 实现contains方法
@Override
public boolean contains(E e) {
return list.contains(e);
} // 实现add方法
@Override
public void add(E e) {
if (!list.contains(e)) {
list.addFirst(e);
}
} // 实现remove方法
@Override
public void remove(E e) {
list.removeElement(e);
}- 用二分搜索树实现的集合与用链表实现的集合的性能比较
import java.util.ArrayList; public class Main { public static double testSet(Set<String> set, String filename) { long startTime = System.nanoTime(); System.out.println(filename);
ArrayList<String> words = new ArrayList<>();
if (FileOperation.readFile(filename, words)) {
System.out.println("Total words: " + words.size()); for (String word : words) {
set.add(word);
}
System.out.println("Total different words: " + set.getSize());
} long endTime = System.nanoTime(); return (endTime - startTime) / 1000000000.0;
} public static void main(String[] args) {
String filename = "pride-and-prejudice.txt"; BSTSet<String> bstSet = new BSTSet<>();
double time1 = testSet(bstSet, filename);
System.out.println("BSTSet, time: " + time1 + " s"); System.out.println(); LinkedListSet<String> linkedListSet = new LinkedListSet<>();
double time2 = testSet(linkedListSet, filename);
System.out.println("LinkedListSet, time: " + time2 + " s");
}
}- 输出结果:
pride-and-prejudice.txt
Total words: 125901
Total different words: 6530
BSTSet, time: 0.109504342 s pride-and-prejudice.txt
Total words: 125901
Total different words: 6530
LinkedListSet, time: 2.208894105 s
- 通过比较结果,我们发现,用二分搜索树实现的集合的比用链表实现的集合更加高效
3.. 集合的时间复杂度分析
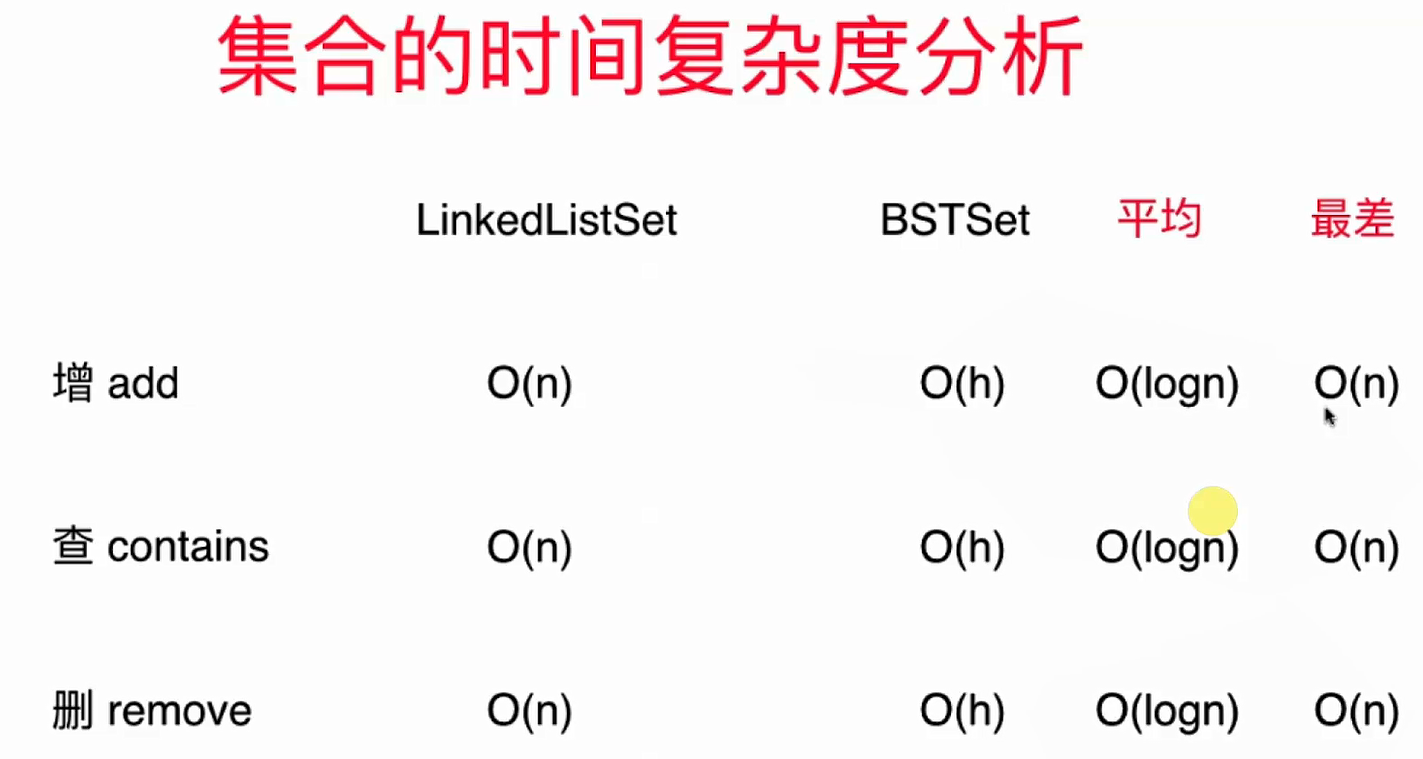
- 上图中"h"是二分搜索树的高度
- 当二分搜索树"满"的时候,性能是最佳的,时间复杂度为O(logn);当二分搜索树退化为链表的时候,性能是最差的,时间复杂度为O(n)

- 映射是存储(键,值)数据对的数据结构(Key, Value)
- 根据键(Key),寻找值(Value)
- 定义映射的接口
Map<K, V>
·void add(K, V)
·V remove(K)
·boolean contains(K)
·V get(K)
·void set(K, V)
·int getSize()
·boolean isEmpty()- 映射接口的业务逻辑如下
public interface Map<K, V> { void add(K key, V value); V remove(K key); boolean contains(K key); V get(K key); void set(K key, V value); int getSize(); boolean isEmpty();
}- 用链表作为映射的底层实现
public class LinkedListMap<K, V> implements Map<K, V> { private class Node {
public K key;
public V value;
public Node next; public Node(K key, V value, Node next) {
this.key = key;
this.value = value;
this.next = next;
} public Node(K key) {
this(key, null, null);
} public Node() {
this(null, null, null);
} @Override
public String toString() {
return key.toString() + " : " + value.toString();
}
} private Node dummyHead;
private int size; // 构造函数
public LinkedListMap() {
dummyHead = new Node();
size = 0;
} // 实现getSize方法
@Override
public int getSize() {
return size;
} // 实现isEmpty方法
@Override
public boolean isEmpty() {
return size == 0;
} private Node getNode(K key) {
Node cur = dummyHead;
while (cur != null) {
if (cur.key.equals(key)) {
return cur;
}
cur = cur.next;
}
return null;
} // 实现contains方法
@Override
public boolean contains(K key) {
return getNode(key) != null;
} // 实现get方法
@Override
public V get(K key) {
Node node = getNode(key); // return node == null ? null : node.value;
if (node != null) {
return node.value;
}
return null;
} // 实现add方法
public void add(K key, V value) {
Node node = getNode(key);
if (node == null) {
dummyHead.next = new Node(key, value, dummyHead.next);
size++;
} else {
node.value = value;
}
} // 实现set方法
public void set(K key, V newValue) {
Node node = getNode(key);
if (node == null) {
throw new IllegalArgumentException(key + " doesn't exist.");
} else {
node.value = newValue;
}
} // 实现remove方法
public V remove(K key) { Node node = getNode(key);
if (node == null) {
throw new IllegalArgumentException(key + " doesn't exist.");
} Node prev = dummyHead;
while (prev.next != null) {
if (prev.next.key.equals(key)) {
break;
}
prev = prev.next;
} if (prev.next != null) {
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
size--;
return delNode.value;
}
return null;
}
}- 用二分搜索树作为映射的底层实现
public class BSTMap<K extends Comparable<K>, V> implements Map<K, V> { private class Node {
private K key;
private V value;
private Node left;
private Node right; // 构造函数
public Node(K key, V value) {
this.key = key;
this.value = value;
this.left = null;
this.right = null;
} // public Node(K key) {
// this(key, null);
// }
} private Node root;
private int size; // 构造函数
public BSTMap() {
root = null;
size = 0;
} // 实现getSize方法
@Override
public int getSize() {
return size;
} // 实现isEmpty方法
public boolean isEmpty() {
return size == 0;
} // 实现add方法
@Override
public void add(K key, V value) {
root = add(root, key, value);
} // 向以node为根节点的二分搜索树中插入元素(key, value),递归算法
// 返回插入新元素后的二分搜索树的根
private Node add(Node node, K key, V value) { if (node == null) {
size++;
return new Node(key, value);
} if (key.compareTo(node.key) < 0) {
node.left = add(node.left, key, value);
} else if (key.compareTo(node.key) > 0) {
node.right = add(node.right, key, value);
} else {
node.value = value;
}
return node;
} // 返回以node为根节点的二分搜索树中,key所在的节点
private Node getNode(Node node, K key) { if (node == null)
return null; if (key.compareTo(node.key) < 0) {
return getNode(node.left, key);
} else if (key.compareTo(node.key) > 0) {
return getNode(node.right, key);
} else {
return node;
}
} @Override
public boolean contains(K key) {
return getNode(root, key) != null;
} @Override
public V get(K key) { Node node = getNode(root, key);
return node == null ? null : node.value;
} @Override
public void set(K key, V newValue) {
Node node = getNode(root, key);
if (node == null)
throw new IllegalArgumentException(key + " doesn't exist!"); node.value = newValue;
} // 返回以node为根的二分搜索树的最小元素所在节点
private Node minimum(Node node) {
if (node.left == null) {
return node;
}
return minimum(node.left);
} // 删除掉以node为根的二分搜索树中的最小元素所在节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node) {
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
node.left = removeMin(node.left);
return node;
} // 实现remove方法
// 删除二分搜索树中键为key的节点
@Override
public V remove(K key) {
Node node = getNode(root, key); if (node != null) {
root = remove(root, key);
return node.value;
}
return null;
} // 删除以node为根节点的二分搜索树中键为key的节点,递归算法
// 返回删除节点后新的二分搜索树的根
private Node remove(Node node, K key) {
if (node == null) {
return null;
} if (key.compareTo(node.key) < 0) {
node.left = remove(node.left, key);
return node;
} else if (key.compareTo(node.key) > 0) {
node.right = remove(node.right, key);
return node;
} else {
// 待删除节点左子树为空的情况
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
// 待删除节点右子树为空的情况
} else if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
// 待删除节点左右子树均不为空
// 找到比待删除节点大的最小节点,即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点
} else {
Node successor = minimum(node.right);
successor.right = removeMin(node.right); //这里进行了size--操作
successor.left = node.left;
node.left = null;
node.right = null;
return successor;
}
}
}
}- 用二分搜索树实现的映射与用链表实现的映射的性能比较
import java.util.ArrayList; public class Main { public static double testMap(Map<String, Integer> map, String filename) { long startTime = System.nanoTime(); System.out.println(filename);
ArrayList<String> words = new ArrayList<>();
if (FileOperation.readFile(filename, words)) {
System.out.println("Total words: " + words.size());
for (String word : words) {
if (map.contains(word)) {
map.set(word, map.get(word) + 1);
} else {
map.add(word, 1);
}
} System.out.println("Total different words: " + map.getSize());
System.out.println("Frequency of PRIDE: " + map.get("pride"));
System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));
} long endTime = System.nanoTime(); return (endTime - startTime) / 1000000000.0;
} public static void main(String[] args) { String filename = "pride-and-prejudice.txt"; LinkedListMap<String, Integer> linkedListMap = new LinkedListMap<>();
double time1 = testMap(linkedListMap, filename);
System.out.println("Linked List Map, time: " + time1 + " s"); System.out.println();
System.out.println(); BSTMap<String, Integer> bstMap = new BSTMap<>();
double time2 = testMap(bstMap, filename);
System.out.println("BST Map, time: " + time2 + " s"); }
}- 输出结果
pride-and-prejudice.txt
Total words: 125901
Total different words: 6530
Frequency of PRIDE: 53
Frequency of PREJUDICE: 11
Linked List Map, time: 9.692566895 s pride-and-prejudice.txt
Total words: 125901
Total different words: 6530
Frequency of PRIDE: 53
Frequency of PREJUDICE: 11
BST Map, time: 0.085364242 s- 通过比较结果,我们发现,用二分搜索树实现的映射的比用链表实现的映射更加高效
6.. 映射的时间复杂度

- 上图中"h"是二分搜索树的高度
- 当二分搜索树"满"的时候,性能是最佳的,时间复杂度为O(logn);当二分搜索树退化为链表的时候,性能是最差的,时间复杂度为O(n)
第二十七篇 玩转数据结构——集合(Set)与映射(Map)的更多相关文章
- 第二十三篇 玩转数据结构——栈(Stack)
1.. 栈的特点: 栈也是一种线性结构: 相比数组,栈所对应的操作是数组的子集: 栈只能从一端添加元素,也只能从这一端取出元素,这一端通常称之为"栈顶": 向栈中添加元 ...
- 第二十八篇 玩转数据结构——堆(Heap)和有优先队列(Priority Queue)
1.. 优先队列(Priority Queue) 优先队列与普通队列的区别:普通队列遵循先进先出的原则:优先队列的出队顺序与入队顺序无关,与优先级相关. 优先队列可以使用队列的接口,只是在 ...
- 第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)
1.. 二叉树 跟链表一样,二叉树也是一种动态数据结构,即,不需要在创建时指定大小. 跟链表不同的是,二叉树中的每个节点,除了要存放元素e,它还有两个指向其它节点的引用,分别用Node l ...
- 第二十五篇 玩转数据结构——链表(Linked List)
1.. 链表的重要性 我们之前实现的动态数组.栈.队列,底层都是依托静态数组,靠resize来解决固定容量的问题,而"链表"则是一种真正的动态数据结构,不需要处理固定容 ...
- 第二十四篇 玩转数据结构——队列(Queue)
1.. 队列基础 队列也是一种线性结构: 相比数组,队列所对应的操作数是队列的子集: 队列只允许从一端(队尾)添加元素,从另一端(队首)取出元素: 队列的形象化描述如下图: 队列是一种先进 ...
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- 第二十七篇:Windows驱动中的PCI, DMA, ISR, DPC, ScatterGater, MapRegsiter, CommonBuffer, ConfigSpace
近期有些人问我PCI设备驱动的问题, 和他们交流过后, 我建议他们先看一看<<The Windows NT Device Driver Book>>这本书, 个人感觉, 这本书 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
- 第二十七篇 -- QTreeWidget总结
前言 之前写过几篇关于TreeWidget的文章,不过不方便查阅,特此重新整合作为总结.不过关于QtDesigner画图,还是不重新写了,看 第一篇 就OK. 准备工作 1. 用QtDesigner画 ...
随机推荐
- UVA12124 | Assemble (二分)
原题 题目大意:给出你的预算和各类待选硬件来组装计算,同种类的硬件只需且必须选购一种,在保证预算足够的情况下求出最优的合计硬件质量. 根据木桶原理,合计硬件质量 = 所选购硬件中数值最低质量的硬件质量 ...
- 获取mybaties插入记录自动增长的主键值
首先在Mybatis Mapper文件中insert语句中添加属性“useGeneratedKeys”和“keyProperty”,其中keyProperty是保存主键值的属性. 例如: <in ...
- VMware该虚拟机似乎正在使用中。如果该虚拟机未在使用,请按“获取所有权(T)”按钮获取它的所有权
原文链接:https://blog.csdn.net/helloxiaozhe/article/details/81176684 VMware该虚拟机似乎正在使用中.如果该虚拟机未在使用,请按“获取所 ...
- 微服务读取不到config配置中心配置信息,Spring Boot无法找到PropertySource:找不到标签Could not locate PropertySource: label not found
服务出现报这个错, o.s.c.c.c.ConfigServicePropertySourceLocator - Could not locate PropertySource: label not ...
- HTML span标签
span:行内标签,不会换行用于:组合文档中的行内元素.元素和文档的组合
- Eclipse项目转到MyEclipse中出错
原因如下. JDK的编译版本和JRE的运行版本不一致导致了这个问题. 在MyEclipse中,对项目进行Build path 逐一设置即可. 还有关于类型转换的问题,由于JDK版本的不一致,下载下来的 ...
- 2019牛客多校第五场B generator 十进制快速幂
generator 1 题意 给出\(x_0,x_1,a,b\)已知递推式\(x_i=a*x_{i-1}+b*x_{i-2}\),出个n和mod,求\(x_n\) (n特别大) 分析 比赛的时候失了智 ...
- 使用Python发送、订阅消息
使用Python发送.订阅消息 使用插件 paho-mqtt 官方文档:http://shaocheng.li/post/blog/2017-05-23 Paho 是一个开源的 MQTT 客户端项目, ...
- 使用Vue-MUI轮播图失效问题解决案例(在Vue的update中执行)
我使用的是mui+vue,社区关于轮播图失效的问题也有几个.我这边遇到的一个情况是我把所有的东西都写到plusReady事件中会导致轮播图搞死都不动,按照其他问答解决了vue生命周期等等的问题.提出来 ...
- 一键安装各个版本boost库(无需编译)
1.NuGet 最简单的,用VS自带的NuGet包管理器安装,一般比较常用的上面都有 2.下载exe安装包 在这里https://sourceforge.net/projects/boost/file ...