数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型
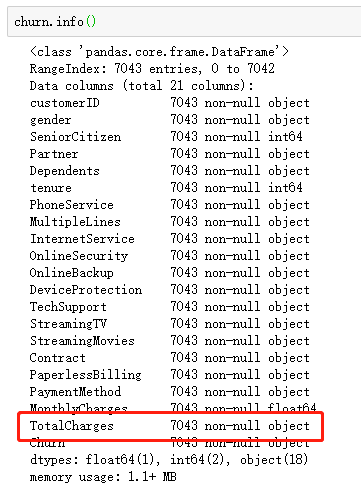
出现的问题:如图,总消费金额本应该为float类型,此处却显示object
需求:将 TotalCharges 的类型转换成float
使用 pandas.to_numeric(arg, errors='raise', downcast=None) 方法,可将参数转换为数字类型。
(别的类型转换,遇到再补充)
df = pd.read_excel('./data_files/Using_Customer-Churn.xlsx')
# 将df.TotalCharges 转成数字类型的数据,则将无效解析设置为NaN
df.TotalCharges = pd.to_numeric(df.TotalCharges, errors='coerce')
df.isnull().sum()
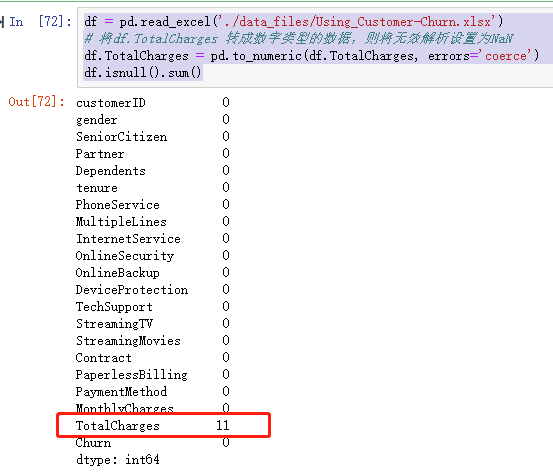
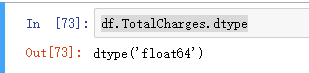
此时,转换完成!
关于pandas.to_numeric 方法的详细信息可参见:https://www.cjavapy.com/article/532/
—————————— 手动分隔,以下为原来的野生思路 —————————
1 首先要找出本特征中,包含的数据类型究竟有哪些
# 创建一个用于盛放数据类型的列表
test_type = list() for i in churn["TotalCharges"]: # 将数据类型 不重复的放入列表中
if type(i) not in test_type:
test_type.append(type(i))
print(test_type) """
[<class 'float'>, <class 'int'>, <class 'str'>]
"""
2 查看除 float 和 int 之外的类型的数据有哪些
# 创建用于盛放数据的列表
str_values= list() for i in churn["TotalCharges"]:
if type(i) != float and type(i) != int:
# 将既不是 float 也不是 int 的数据加到列表
str_values.append(i) print(str_values) """
[' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
"""
此时得到:非数值型数据均为空格。
3 将数据统一为 float 类型
# 空值替换所有空格
churn['TotalCharges'] = churn["TotalCharges"].replace(" ",np.nan)
# 去掉含有空值的样本
churn = churn[churn["TotalCharges"].notnull()]
# 将 TotalCharges 转换成 float类型
churn['TotalCharges'] = churn['TotalCharges'].astype(float)
此时
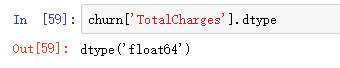
大功告成!
遍历的方法,相对来说效率略低,Pandas 应该有什么方法,更加直接吧
纯野生思路,找到更好的办法再更新~
数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型的更多相关文章
- 机器学习之数据预处理,Pandas读取excel数据
Python读写excel的工具库很多,比如最耳熟能详的xlrd.xlwt,xlutils,openpyxl等.其中xlrd和xlwt库通常配合使用,一个用于读,一个用于写excel.xlutils结 ...
- 数据预处理 | 使用 pandas.to_datetime 处理时间类型的数据
数据中包含日期.时间类型的数据可以通过 pandas 的 to_datetime 转换成 datetime 类型,方便提取各种时间信息 1 将 object 类型数据转成 datetime64 1&g ...
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
随机推荐
- 学习MVC框架,处理分页和删除分页转跳的问题
第一次写博客,文采不好请多见谅,这里主要是写一下,自己是如何处理分页问题,我想初学者也遇到过这个问题. 分页的情况下,编辑信息有返回和编辑2个按钮,操作后都是应该返回原分页界面,使用TempData把 ...
- jenkins 参数化运行性能测试脚本
概述 我们用jenkins做持续集成的时候,常常需要跑不同的脚本,传不同的参数.尤其是性能基准测试,线程数和持续时间需要实时调整以满足我们的测试需求.那么是不是需求变了,我们 就需要重新准备一套脚本? ...
- js中(function(){})()的写法用处
直到今天我才明白的一个玩意!!! 来来来,首先嘛,JS中函数有两种命名方式 1.一种是声明式. 而声明式会导致函数提升,function会被解释器优先编译.即我们用声明式写函数,可以在任何区域声明,不 ...
- MySql学习-2. NavicatforMySQL 与 MySql的对接以及一些操作:
1.连接: 2.数据库的创建: 3.数据库中表的创建: 4.表的设计: 4.1 设计表: 4.2 增加数据(自动递增只是保证唯一值,即使数据删除了也是得前进):
- 破解“低代码”的4大误区,拥抱低门槛高效率的软件开发新选择 ZT
最近,每个人似乎都在谈论“低代码”.以美国的Outsystems.Kinvey,以及国内的活字格为代表的低代码开发平台,正在风靡整个IT世界.毕竟,能够以最少的编码快速开发应用的想法本身就很吸引人.但 ...
- 使用springboot整合ActiveMQ
结构图 第一步:导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifact ...
- python进阶----深拷贝&浅拷贝
复制需要区分,,复制的是源文件的数据,还是指向源文件数据的地址 1.引用 b=a时,理解为b指向了a指向的数据,相当于引用复制 a=[1,2] b=a #验证复制的是数据还是地址 #1.查看ab的 ...
- JQuery调用WebService封装方法
//提交的webservice链接 //var url = "/wsstafffrate?OpenWebService"; //请求前拼接好的soap字符串 //var soapd ...
- Java多线程之互斥锁Syncharnized
public class Bank { private int money; private String name; public Bank(String name, int money) { th ...
- Android实战项目——家庭记账本(三)
今天完成的主要内容有: 1.主页面账单明细部分细节展示 2.对每个列表项,点击打开新的可编辑修改具体页面 3.实现了搜索页面的UI布局 4.优化了部分页面的UI,提升用户视觉和使用体验 实现效果如下: ...