机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了。

在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!
一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人,跟他们聊一段时间。技术能够让模型起飞,前提是你和业务人员一样理解数据。
所以特征选择的第一步,其实是根据我们的目标,用业务常识来选择特征。来看完整版泰坦尼克号数据中的这些特征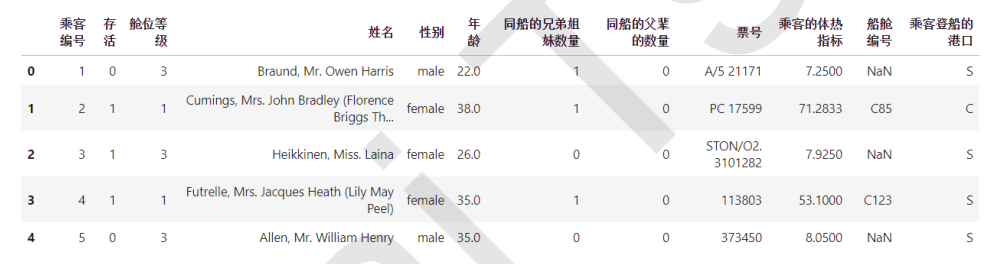
其中是否存活是我们的标签。很明显,以判断“是否存活”为目的,票号,登船的舱门,乘客编号明显是无关特征,可以直接删除。姓名,舱位等级,船舱编号,也基本可以判断是相关性比较低的特征。
性别,年龄,船上的亲人数量,这些应该是相关性比较高的特征。
所以,特征工程的第一步是:理解业务。
当然了,在真正的数据应用领域,比如金融,医疗,电商,我们的数据不可能像泰坦尼克号数据的特征这样少,这样明显,那如果遇见极端情况,我们无法依赖对业务的理解来选择特征,该怎么办呢?我们有四种方法可以用来选择特征:过滤法,嵌入法,包装法,和降维算法。
#导入数据,让我们使用digit recognizor数据来一展身手 import pandas as pd
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 3 Preprocessing\digit
recognizor.csv") X = data.iloc[:,1:]
y = data.iloc[:,0] X.shape """
这个数据量相对夸张,如果使用支持向量机和神经网络,很可能会直接跑不出来。使用KNN跑一次大概需要半个小时。
用这个数据举例,能更够体现特征工程的重要性。
"""
机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介的更多相关文章
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
随机推荐
- Python语言基础-语法特点、保留字与标识符、变量、基本数据类型、运算符、基本输入输出、Python2.X与Python3.X区别
Python语言基础 1.Python语法特点 注释: 单行注释:# #注释单行注释分为两种情况,例:第一种#用于计算bim数值bim=weight/(height*height)第二种:bim=we ...
- Python itchat.get_chatrooms() 抓取群聊不全的问题
1 rooms = itchat.get_chatrooms() 2 f = codecs.open("3.txt","w","utf-8" ...
- ORA-12514:监听程序无法识别
使用plsql远程登录oracle数据库时,出现无法识别监听程序的错误.很大机率是配置文件出错. 配置文件如下: listener.ora是服务器端用的,oracle监听程序,就是读的这个文件,里面有 ...
- 能被 K 整除的最大连续子串长度
[来源]网上流传的2017美团秋招笔试题 [问题描述] 两个测试样例输出都是5 [算法思路] 暴力解法时间会超限,使用一种很巧妙的数学方法.用在读取数组arr时用数组sum记录其前 i 项的和,即 s ...
- WeChair项目Alpha冲刺(1/10)
团队项目进行情况 1.昨日进展 因为是Alpha冲刺第一天,所以昨日进展无 2.今日安排 前端:完成前端页面的首页html+css部分 后端:搭建好SpringBoot项目以及完成实体类代码的编 ...
- 关于word2vec的一些问题
CBOW v.s. skip-gram CBOW 上下文预测中心词,出现次数少的词会被平滑,对出现频繁的词有更高的准确率 skip-gram 中心词预测上下文,训练次数比CBOW多,表示罕见词更好 例 ...
- SpringCloud 入门(三)
前文我们介绍了简单的创建一个客户端,并介绍了它是如何提供服务的,接下来介绍它的另外一个组件:zuul. zuul 提供了微服务的网关功能,通过它提供的接口,可以转发不同的服务,可以当作一个中转站. 搭 ...
- xutils工具上传日志文件--使用https并且带进度条显示
package logback.ecmapplication.cetcs.com.myapplication; import android.app.Activity; import android. ...
- 入门大数据---Hbase容灾与备份
一.前言 本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable.Export/Import.Snapshot.分别介绍如下: 二.CopyTable 2.1 简介 CopyTa ...
- 【MonogDB帮助类】
using System; using System.Collections.Generic; using System.Linq; using System.Web; using MongoDB; ...