02_HBase集群部署
HBase集群部署
HBase是分布式数据库,本身也需要借助zookeeper进行集群节点间的协调(Master, RegionServer), 可以使用HBase自带的zookeeper,也可以使用外部独立部署的zookeeper, 从练习的角度讲,可以使用HBase内部自带的zookeeper
在开始部署HBase前,要先检查下Hadoop集群上的java和HBase的配套关系

1)上传安装包到待部署节点,解压并得到安装目录
以我的为例,安装包上传到3个待部署节点的/usr/local/src/目录,解压后得到HBase安装目录,同时修改安装目录名为hbase-0.98.24
[/usr/local/src] chmod hbase-0.98.-hadoop1-bin.tar.gz
[/usr/local/src] tar -xzvf hbase-0.98.-hadoop1-bin.tar.gz
[/usr/local/src] mv hbase-0.98.-hadoop1 hbase-0.98.
2) HBase配置文件修改
任选1个节点,修改HBase配置文件目录conf下的 hbase-site.xml, regionservers, hbase-env.sh
hbase-site.xml
配置参数说明
*hbase.tmp.dir:本地目录上存放的hbase临时数据
*hbase.rootdir: HDFS上HBase真正存储数据的根路径(用户表的表结构,用户表对应的各个HFile, 各个RegionServer自己维护的Hlog)
*hbase.cluster.distributed: HBase是否以集群模式运行
*hbase.zookeeper.quorum: HBase依赖的zookeeper集群在哪些节点上,填入节点主机名即可
*hbase.zookeeper.property.dataDir: 本地目录上存储的zookeeper快照
<configuration>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/src/hbase-0.98./tmp</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/src/hbase-0.98./zookeeper</value>
</property>
</configuration>
hbase-env.sh
# The java implementation to use. Java 1.6 required.
export JAVA_HOME=/usr/local/src/jdk1.6
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib # Tell HBase whether it should manage it's own instance of Zookeeper or not.
# 使用HBase自带的zookeeper, 生产环境设置为False,使用外部zk集群
export HBASE_MANAGES_ZK=true
regionservers
哪些节点将作为regionserver, 写入主机名即可,每行一个
Master也作为了1个regionserver, 即Hbase的主节点,同时也作为Regionserver
master
slave1
slave2
3) HBase配置文件分发到其他待部署HBase的各个节点
# scp –rp hbase-site.xml root@slave1:/usr/local/src/hbase-0.98./conf
# scp –rp hbase-env.sh root@slave1:/usr/local/src/hbase-0.98./conf
# scp –rp regionservers root@slave1:/usr/local/src/hbase-0.98./conf # scp –rp hbase-site.xml root@slave2:/usr/local/src/hbase-0.98./conf
# scp –rp hbase-env.sh root@slave2:/usr/local/src/hbase-0.98./conf
# scp –rp regionservers root@slave2:/usr/local/src/hbase-0.98./conf
4)配置所有待部署HBase的各个节点的环境变量
/etc/profile文件增加如下内容
export HBASE_HOME=/usr/local/src/hbase-0.98./
export HBASE_CLASSPATH=$HBASE_HOME/conf
export HBASE_LOG_DIR=$HBASE_HOME/logs
export PATH=$PATH:$HBASE_HOME/bin
通过source命令,让环境变量生效
# source /etc/profile
5)检查待部署Hbase的各个节点,HDFS是否正常启动,zk是否关闭
HBase的数据存储,依赖于HDFS,因此要先保证各个节点上的HDFS进程已经正常启动, JPS命令在各个节点上进行查询即可
由于配置是使用HBase自带的zk集群,因此先通过zkServer.sh stop将各个节点上的zookeeper进行关闭
6)只需要在主节点Master上启动HBase,从节点RegionServer自动被拉起
进入HBase安装目录下的bin目录,执行start-hbase.sh启动整个集群, 执行stop-hbase.sh停止整个集群
# ./start-hbase.sh
# ./stop-hbase.sh
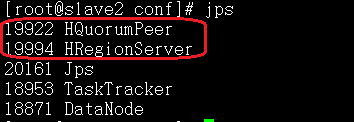
7)集群启动后检查各个节点的HBase进程,部署完成
主节点:同时具有Master和RegionServer角色,并且启动了HBase自带zk

从节点:具RegionServer角色,并且启动了HBase自带zk

02_HBase集群部署的更多相关文章
- Quartz.net持久化与集群部署开发详解
序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我的罪过. 但是quart.net是经过许多大项 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- CAS 集群部署session共享配置
背景 前段时间,项目计划搞独立的登录鉴权中心,由于单独开发一套稳定的登录.鉴权代码,工作量大,最终的方案是对开源鉴权中心CAS(Central Authentication Service)作适配修改 ...
- Windows下ELK环境搭建(单机多节点集群部署)
1.背景 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安全性,从而及时 ...
- 理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
- HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程: 安装Hbase之前首先系统应该做通 ...
- SolrCloud-5.2.1 集群部署及测试
一. 说明 Solr5内置了Jetty服务,所以不用安装部署到Tomcat了,网上部署Tomcat的资料太泛滥了. 部署前的准备工作: 1. 将各主机IP配置为静态IP(保证各主机可以正常通信,为避免 ...
随机推荐
- 图片预览-兼容IE
直接贴代码吧: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www ...
- 【转】 Oracle 用户权限管理方法
sys;//系统管理员,拥有最高权限 system;//本地管理员,次高权限 scott;//普通用户,密码默认为tiger,默认未解锁 sys;//系统管理员,拥有最高权限 system;//本地管 ...
- apply、map、applymap、Dropna
DataFrame常用易混淆方法 apply && map && applymap 1.apply():作用在一维的向量上时,可以使用apply来完成,如下所示 2.m ...
- matlab 以excel格式将字符串数组写入TXT文件
[m, n] = size(FFoutpu);fp = fopen('FFoutpu.txt','wt');fprintf(fp, 'name CODE ROTC EBIT_EV SHIZHI ROT ...
- excel 批量在一列数据添加单引号以及逗号
在A列后插入一列B1输入="'"&a1&"'," 然后向下填充 就ok 了 向下填充:选中上方连续单元格,鼠标放在选中区域右下角处(会显示“十” ...
- 通俗理解RxJS(一)
自学 Rx 快有一个周了, 它非常适合处理复杂的异步场景.结合自己所学,决定写系列教程. 我认为, Rx 中强大的地方在于两处 管道思想,通过管道,我们订阅了数据的来源,并在数据源更新时响应 . 强大 ...
- Codeforces 1144G Two Merged Sequences
题意: 将一个序列分成两个序列,两个序列中元素的相对顺序保持和原序列不变,使得分出的两个序列一个严格上升,一个严格下降. 思路: 我们考虑每个元素都要进入其中一个序列. 那么我们维护一个上升序列和一个 ...
- Understanding Convolutional Neural Networks for NLP
When we hear about Convolutional Neural Network (CNNs), we typically think of Computer Vision. CNNs ...
- java opencv使用相关
Using OpenCV Java with Eclipse http://docs.opencv.org/2.4/doc/tutorials/introduction/java_eclipse/ja ...
- webstorm的个性化设置settings
如何更改主题(字体&配色):File -> settings -> Editor -> colors&fonts -> scheme name.主题下载地址 如 ...