Selenium选择web元素
获取html片段可以用来做什么?
可以用来分割,也可以分析HTML文档
beautifulsoup用法?
安装beautifulsoup库: pip install beautifulsoup4
因为bs里面缺省的库对html的兼容性不够,还要安装一个库来实现: pip install html5lib
下面附上bs1.html代码截图:
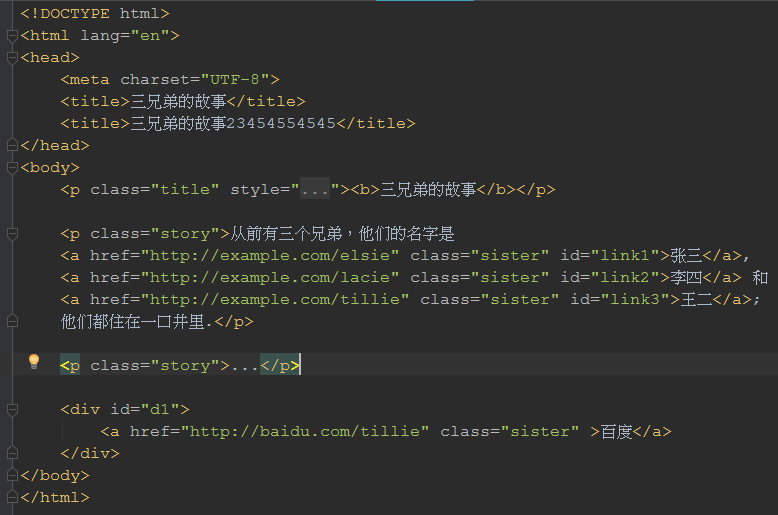
通过代码实现:
# BS操作对象是字符串,假设要对某个html文本作分析,就要先将文本的字符串读出来。
with open('bs.html',encoding='utf8') as f:
html_doc = f.read()
# 导入相关库,html5lib不用导入,BS会自动引用
from bs4 import BeautifulSoup
# 指定用HTML5lib来解析文档
soup = BeautifulSoup(html.doc, 'html5lib') # 第一个参数是要解析的文本,第二个参数指定是用htmllib库来解析的
# print(soup.title) # 打印出第一个title的内容
# print(soup.find('title'))
# print(soup.title.name) # 获取标签名
# 获取tag(标签)文本内容
# print(soup.title.string)
# 也可以:
# print(soup.title.get_text())
# 如果要获取tag的父节点tag
# print(soup.title.parent)
# print(soup.title.parent.name)
# 如果要获取元素的属性值
# print(soup.div['id'])
# print(soup.p['style'])
# print(soup.a) 只找到第一个标签
# print(soup.find_all('a')) 找到所有的a标签
# print(soup.find_all('a')[1]) 找到第二个a标签 根据下标
# print(soup.find('a', id='link1')) 根据id属性来查找相应的a标签
# print(soup.find('a', href='http://example.com/lacie')) # 根据超链接来查找相应的a标签
webdriver提供的八种基本元素定位:
通过id属性选择元素:find_element_by_id()
通过name属性选择元素:find_element_by_name()
通过classs属性选择元素:find_element_by_class_name()
通过tag(标签)属性选择元素:find_element_by_tag_name()
通过link选择元素:find_element_by_link_text()
通过partial_link(模糊匹配的方式)定位:find_element_by_partial_link_text()
通过xpath选择元素:find_element_by_xpath()
通过css选择元素:find_element_by_css_selector()
Selenium选择web元素的更多相关文章
- 选择、操作web元素-2
11月3日 等待web元素的出现 例子:百度搜索松勤网,点击操作后不等待页面刷新,下面选择页面元素的时候,该元素还是未出现 sleep方案的弊病:固定的等待时间,导致测试用例执行时间很长 为什么cli ...
- Web自动化 - 选择操作元素 1
文章转自 白月黑羽教Python 所有的 UI (用户界面)操作 的自动化,都需要选择界面元素. 选择界面元素就是:先让程序能找到你要操作的界面元素. 先找到元素,才能操作元素. 选择元素的方法 程序 ...
- 【Selenium03篇】python+selenium实现Web自动化:元素三类等待,多窗口切换,警告框处理,下拉框选择
一.前言 最近问我自动化的人确实有点多,个人突发奇想:想从0开始讲解python+selenium实现Web自动化测试,请关注博客持续更新! 这是python+selenium实现Web自动化第三篇博 ...
- Web测试Selenium:如何选取元素
Web测试工具Selenium:如何选取元素 2009-02-17 23:23 by 敏捷的水, 5372 阅读, 22 评论, 收藏, 编辑 selenium是一个非常棒的Web测试工具,他对Aja ...
- [Selenium With C#学习笔记] Lesson-02 Web元素定位
使用Selenium来做自动化测试,一般的流程是:查找定位元素--->操作元素--->断言,那么第一步我们需要能够完成查找并定位元素,Selenium目前提供了8种基本定位方法,可根据实际 ...
- 选择、操作web元素
11月1日 什么是web元素 Selenium自动化主要就是:选择界面元素,操作界面元素(输入操作:点击.输入文字.拖拽等,输出操作:获取元素的各种属性),根据界面上获取的数据进行分析和处理 选择元素 ...
- Web自动化 - 选择操作元素 2
文章转自 白月黑羽教Python 前面我们看到了根据 id.class属性.tag名 选择元素. 如果我们要选择的 元素 没有id.class 属性, 这时候我们通常可以通过 CSS selector ...
- [Selenium With C#基础教程] Lesson-02 Web元素定位
作者:Surpassme 来源:http://www.jianshu.com/p/cfd4ed1daabd 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 使用Selenium ...
- 【Selenium01篇】python+selenium实现Web自动化:搭建环境,Selenium原理,定位元素以及浏览器常规操作!
一.前言 最近问我自动化的人确实有点多,个人突发奇想:想从0开始讲解python+selenium实现Web自动化测试,请关注博客持续更新! 二.话不多说,直接开干,开始搭建自动化测试环境 这里以前在 ...
随机推荐
- MySql——创建数据表,查询数据,排序查询数据
参考资料:<Mysql必知必会> 创建数据表 在学习前首先创建数据表和插入数据.如何安装mysql可以看看上个博客https://www.cnblogs.com/lbhym/p/11675 ...
- Thrift总结(四)Thrift实现双向通信
前面介绍过 Thrift 安装和使用,介绍了Thrift服务的发布和客户端调用,可以查看我之前的文章:https://www.cnblogs.com/zhangweizhong/category/10 ...
- nyoj 28-大数阶乘 (大数模板)
28-大数阶乘 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:19 submit:39 题目描述: 我们都知道如何计算一个数的阶乘,可是,如果这个数 ...
- Python3.7.1学习(六)RabbitMQ在Windows环境下的安装
Windows下安装RabbitMQ 环境配置 部署环境 部署环境:windows server 2008 r2 enterprise(本文安装环境Win7) 官方安装部署文档:http://www. ...
- 逆向libbaiduprotect(二)
首先要确保你所使用的gdb和gdbserver是配对的,最好(或必须)是sdk内相同platform(api level)下的gdb和gdbserver.否则你使用的gdb可能与运行测试机上的gdbs ...
- ACE框架 基于共享内存的分配器 (算法设计)
继承上一篇<ACE框架 基于共享内存的分配器设计>,本篇分析算法部分的设计. ACE_Malloc_T模板定义了这样一个分配器组件 分配器组件聚合了三个功能组件:同步组件ACE_LOCK, ...
- Condition对象以及ArrayBlockingQueue阻塞队列的实现(使用Condition在队满时让生产者线程等待, 在队空时让消费者线程等待)
Condition对象 一).Condition的定义 Condition对象:与锁关联,协调多线程间的复杂协作. 获取与锁绑定的Condition对象: Lock lock = new Reentr ...
- 攻防世界 4-ReeHY-main
检查保护机制: 发现 可以好像写got 然后 程序流程 这里 有double free 然后 再发现 这里很有趣 ,要是我的content为零了 且size 小于112 那就从栈上copy一些内容 ...
- [从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList
一.线性表 1,什么是线性表 线性表就是零个或多个数据元素的有限序列.线性表中的每个元素只能有零个或一个前驱元素,零个或一个后继元素.在较复杂的线性表中,一个数据元素可以由若干个数据项组成.比如牵手排 ...
- vim的各项指令
lesson1 <ESC> 保证进入正常模式 :q!回车 退出编辑器 x 删除光标所在的字母 i 添加内容 A 自动追加内容到行尾 :wq 保存文件并退出 lesson2 dw 删除某 ...