【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一、写在前面
之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验。所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对IP的检测。本文介绍的是利用Redis数据库实现的分布式爬虫,Redis是一种常用的菲关系型数据库,常用数据类型包括String、Hash、Set、List和Sorted Set,重要的是Redis支持主从复制,主机能将数据同步到从机,也就能够实现读写分离。因此我们可以利用Redis的特性,借助requests模块发送请求,再解析网页和提取数据,实现一个简单的分布式爬虫。
二、基本环境
Python版本:Python3
Redis版本:5.0
IDE: Pycharm
三、环境配置
由于Windows下的安装配置比较简单,所以这里只说Linux环境下安装和配置Redis(以Ubuntu为例)。
1.安装Redis
1)apt安装:
$ sudo apt-get install redis-server
2)编译安装:
$ wget http://download.redis.io/releases/redis-5.0.0.tar.gz
$ tar -xzvf redis-5.0.0.tar.gz
$ cd redis-5.0.0
$ make
$ make install
2.配置Redis
首先找到redis.conf文件,然后输入命令sudo vi redis.conf,进行如下操作:
注释掉bind 127.0.0.1 # 为了远程连接,这一步还可以将bind 127.0.0.1改为bind 0.0.0.0
protected-mode yes 改为 protected-mode no
daemonized no 改为 daemonized yes
如果6379端口被占用,还需要改一下端口号。除此之外,要远程连接还需要关闭防火墙。
chkconfig firewalld off # 关闭防火墙
systemctl status firewalld # 检查防火墙状态
3.远程连接Redis
使用的命令为redis-cli -h <IP地址> -p <端口号>
注:Windows查看IP地址用ipconfig,Linux查看IP地址用ifconfig。
四、基本思路
这次我爬取的网站为:http://www.shu800.com/,在这个网站的首页里有五大分类,分别是性感美女、清纯可爱、明星模特、动漫美女和丝袜美腿,所以要做的第一件事就是获取这几个分类的URL。然后,对每个分类下的网页进行爬取,通过查看网页元素可以发现如下信息:

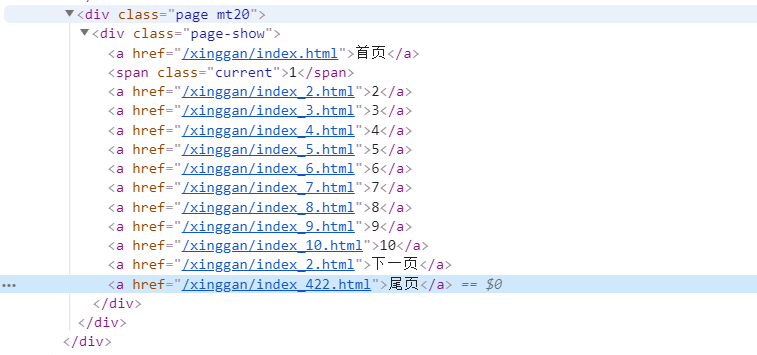
可以很明显地看到每一页的URL都是符合一定规律的,只要获取到了尾页的URL,将其中的页数提取出来,也就能构造每一页的URL了,这就比每次去获取下一页的URL简单多了。而对于每一个图集下的图片,也是用同样的方法得到每一页图片的URL。最后要做的就是从图片网页中将图片的URL提取出来,然后下载保存到本地。
这次分布式爬虫我使用了两台电脑,一台作为主机master,另一台作为从机slave。主机开启Redis服务,爬取每一页图片的URL,并将爬取到的URL保存到Redis的集合中,从机远程连接主机的Redis,监听Redis中是否有URL,如果有URL则提取出来进行下载图片,直至所有URL都被提取和下载。
五、主要代码
1.第一段代码是爬取每个页面里的美女图集的URL,并且把这些URL保存到数据库中,这里使用的是Redis中的集合,通过使用集合能够达到URL去重的目的,代码如下:
def get_page(url):
"""
爬取每个页面下的美女图集的URL
:param url: 页面URL
:return:
"""
try:
r = Redis(host="localhost", port=6379, db=1) # 连接Redis
time.sleep(random.random())
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
et = etree.HTML(res.text)
href_list = et.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/ul/li/a/@href')
for href in href_list:
href = "http://www.shu800.com" + href
r.sadd("href", href) # 保存到数据库中
except requests.exceptions:
headers["User-Agent"] = ua.random
get_page(url)
2.第二段代码是从机监听Redis中是否有URL的代码,如果没有URL,等待五秒钟再运行,因为如果不稍作等待就直接运行,很容易超过Python的递归深度,所以我设置了一个等待五秒钟再运行。反之,如果有URL被添加到Redis中,就要将URL提取出来进行爬取,使用的方法是redis模块里的spop()方法,该方法会从Redis的集合中返回一个元素。需要注意的是,URL被提取出来后要先转成str。
def get_urls():
"""
监听Redis中是否有URL,如果没有就一直运行,如果有就提取出来进行爬取
:return:
"""
if b"href" in r.keys():
while True:
try:
url = r.spop("href")
url = url.decode("utf-8") # unicode转str
print("Crawling URL: ", url)
get_image(url)
get_img_page(url)
except:
if b"href" not in r.keys(): # 爬取结束,退出程序
break
else:
continue
else:
time.sleep(5)
get_urls()
六、运行结果
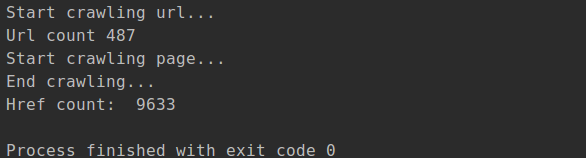
下图是在主机master上运行的截图,这里爬取到的图集总共有9633个:
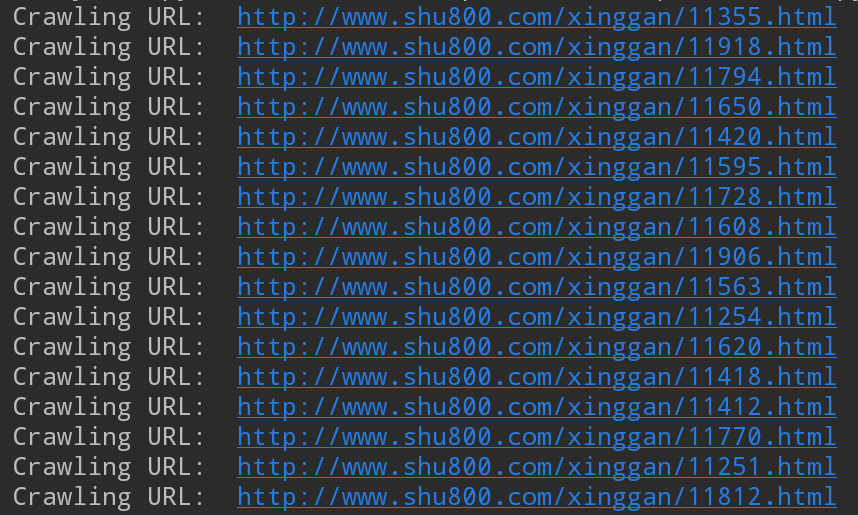
从机slave会不断地从Redis数据库中提取URL来爬取,下图是运行时的截图:
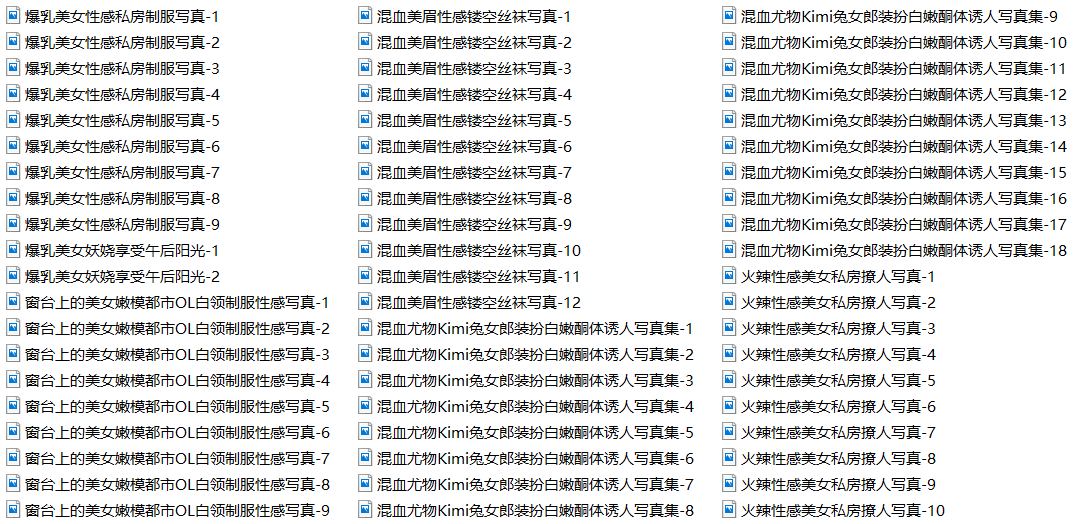
打开文件夹看看爬下来的图片都有什么(都是这种标题,有点难顶啊...):
完整代码已上传到GitHub!
【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验的更多相关文章
- python爬虫爬取大众点评并导入redis
直接上代码,导入redis的中文编码没有解决,日后解决了会第一时间上代码!新手上路,多多包涵! # -*- coding: utf-8 -*- import re import requests fr ...
- python爬虫爬取腾讯招聘信息 (静态爬虫)
环境: windows7,python3.4 代码:(亲测可正常执行) import requests from bs4 import BeautifulSoup from math import c ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
随机推荐
- Bzoj 2281 [Sdoi2011]黑白棋 题解
2281: [Sdoi2011]黑白棋 Time Limit: 3 Sec Memory Limit: 512 MBSubmit: 592 Solved: 362[Submit][Status][ ...
- java学习笔记(基础篇)—数组模拟实现栈
栈的概念 先进后出策略(LIFO) 是一种基本数据结构 栈的分类有两种:1.静态栈(数组实现) 2.动态栈(链表实现) 栈的模型图如下: 需求分析 在编写代码之前,我习惯先对要实现的程序进行需求分析, ...
- Image Classification
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 【最短路径之dijkstra(迪杰斯特拉)算法】
这一章主要介绍最短路径的算法之一,dijkstra算法. 概念 :迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点 ...
- R030---手把手教程:你有一条RPA发送的工资条待查收
一.缘起 前2天写了<R029---简述:用UiPath实现RPA(工作流程自动化)(基础知识篇)>,本篇作为补充. 实战出真知,以做代学,下面以一个HR的真实场景举例实践,用UiPat ...
- MYSQL数据库数据类型
07.14自我总结 MYSQL数据库数据类型 一.整数类型和浮点数典型 1.有符号/没符号 对于整数和负整数来说,默认情况下是有符号范围的 默认是有符号 有符号和没符号其实就是有没有包括负数,有符号是 ...
- SCADA开源项目lite版本
一.引子 自从看了老坏猫(江湖人称猫总)的SharpSCADA项目后,让我感觉耳目一新同时也对自动化数据采集有了更深入的认识,我相信有不少做上位机的朋友和我一样对这个项目非常好奇.我们做上位机的应用场 ...
- 分享一个 Linux 环境下,强力的Python 小工具
场景 Linux 用户,经常需要在终端查看一些数据,从文件里看 或者网络协议获取数据并查看. 比如,查看文件里的json数据:比如,查看etcd里存下的数据. 如果直接看cat 或者 curl 得到的 ...
- JSTL和EL简介
EL Expression Language,表达式语言,通过操作存在于PageContext等的数据,实现JSP的编写更加简单,单纯使用EL不用引入jar包,只要容器支持即可. EL的隐含对象 EL ...
- +CIMG+彩色图片边缘提取实验记录_canny/hough transfrom
前言: 书到用时方恨少 正文: 边缘提取技术一直都有接触,最通用的莫过于拉普拉斯,sobel几个算子,两个算子都可通过简单的模板运算进行,而现在比较好的一个边缘提取技术是canny,文章中我是用的ca ...