Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】所谓爬虫,就是通过编程的方式自动从网络上获取自己所需的资源,比如文章、图片、音乐、视频等多媒体资源。通过一定的方式获取到html的内容,再通过各种手段分析得到自己所需的内容,比如通过BeautifulSoup对网页内容进行解析提取。
本文通过selenium的webdriver模拟浏览器来浏览网页,通过lxml库解析得到咱所需的内容。下面开始我们的爬虫工作。
本文目录:
1.目标
我们今天的目标是自动加载多页新闻内容的:标题、图片、作者、类型、发布时间
在浏览器里,头条的首页是可以不断滑动到底自动加载下一页新闻内容的,我们在上一篇文章Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】 中实现的,只能获取第一页的10条新闻,因为这些新闻内容是通过异步请求刷新的,本节我们将实现自动循环加载N页新闻内容
2.实现
2.1、模拟页面滚动到底
我们看下在上一节实践中我们写的代码:
"""
获取头条首页内容
"""
def __getTouTiaoHtml(self, url):
# 简单的入参校验
if url and '' != url and url.startswith("http"):
# 浏览器打开页面
self.__browser.get(url)
try:
# 此处等到我们所需的热文元素加载出来了再进行下一步,避免页面还没加载完成就去解析内容导致内容为空
element = WebDriverWait(self.__browser, 10).until(
EC.presence_of_element_located((By.XPATH, "//ul/li/div[@ga_event=article_item_click]"))
)
except Exception as ex:
print(ex)
finally:
pass
resHtml = self.__browser.page_source
return resHtml
在try-catch 那里只是等待页面加载完成出现新闻内容的布局元素后,就往下继续执行了,所以这里只能加载一页数据。找到问题就好办了,那么我们在
resHtml = self.__browser.page_source这行代码之前,加一段代码实现循环模拟滑动滚动条到底部触发自动加载机制来加载更多内容:
1、简单实现:通过滑动到底后,sleep一定时间来保障分页内容加载完成:
try:
""" 模拟滚动到底部加载下一页,一共循环6次,每次等待4s,这个时间根据网速调整,如果你需要获取更多,那么把循环的范围加大就行了。
"""
for i in range(1, 6):
self.__browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(4)
except Exception as ex:
print(ex)
最后,重新执行下,就能看到效果了,总共获取了70条新闻内容
2、高逼格一点的方法:我们分析下图布局:
加载中…这个布局,在新的分页内容加载过程中,这个style的display值不是none,而当加载完成后,这个display值变为none了,根据这个规律,我们可以根据底部这个加载中的布局从可见到隐藏状态的切换,来表示分页内容加载完成了,具体代码如下,替换上面方法1中的sleep(4):
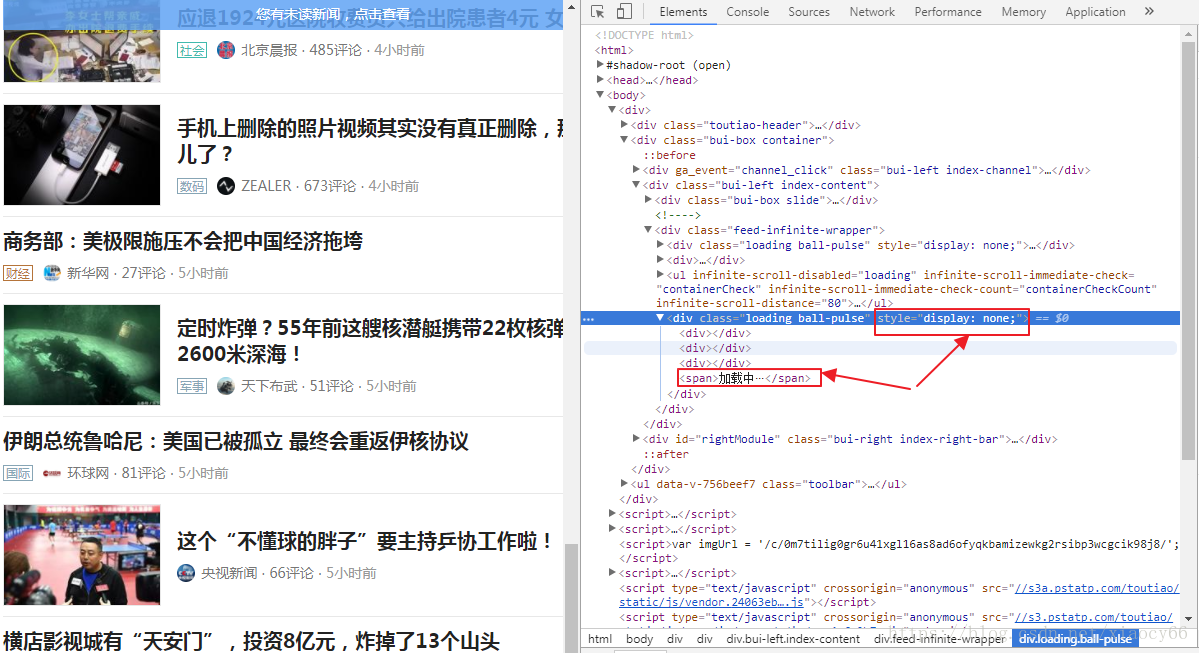
try:
# 模拟滚动到底部
for i in range(1, 6):
self.__browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# sleep(4) 替换为下面的方式来监听分页内容是否加载完成了。
try:
# 此处等到我们所需的热文元素加载出来了再进行下一步,避免页面还没加载完成就去解析内容导致内容为空
element = WebDriverWait(self.__browser, 10).until(
EC.presence_of_element_located((By.XPATH, '//span[contains(text(), "加载中")]/../div[@class="feed-infinite-wrapper"]/div[contains(@class, "ball-pulse")][contains(@class, "loading")][@style="display: none;"]'))
)
except Exception as ex:
pass
except Exception as ex:
print(ex)
本文完整代码 →:下载地址
全文完结,后续实现用其它框架来爬虫新闻资源。敬请期待~
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
参考资料:
[1]: XPath语法参考
[2]: 廖雪峰老师的Python3 在线学习手册
[3]: Python3官方文档
[4]: 菜鸟学堂-Python3在线学习
[5]: 其他所有分享过python学习填坑网友的经验
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】的更多相关文章
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- 使用python-aiohttp爬取今日头条
http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用python-aiohttp爬取网易云音乐>中, ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
随机推荐
- Tomcat配置域名/IP访问及其中遇到的问题注意事项
1.先在tomcat下的conf下找到server.xml文件,用记事本打开后,首先对端口号进行修改,以前一直以为8080是默认的端口号,其实默认的端口号是80 <Connector port= ...
- 笔记本如何设置插入USB鼠标自动禁用触摸板
Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Software\Synaptics\SynTPEnh] [HKEY_LOCAL_MAC ...
- 函数wait和waitpid
函数wait 一个进程在终止时会关闭所有文件描述符,释放在用户空间释放的内存,但它的PCB还保留着,内核在其中保存一些信息:如果是正常终止时则保存着退出状态,如果是异常终止则保存着导致该进程终止的信号 ...
- SSD垃圾回收
A complete GC typically:includes four steps: selecting some blocks that contain somestale data as vi ...
- lua和java防注入
lua样例 local sql = "SELECT * FROM t_base_person WHERE person_id=%s and bureau_id=%s" sql = ...
- CentOS 6.9 NFS安装和配置
1.安装依赖包 yum install nfs-utils rpcbind -y 2.开机启动 chkconfig rpcbind on chkconfig nfs on 3.创建一个共享目录和加权限 ...
- Multi-Fiber Networks for Video Recognition (MFNet)
Motivation:减少时空网络的计算量,保持视频分类精度的基础上,使速度尽可能接近对应网络的2D版本. 为此提出 Multi-Fiber 网络,将复杂网络拆分成轻量网络的集成,利用 fibers ...
- Java集合源码学习(三)LinkedList
前面学习了ArrayList的源码,数组是顺序存储结构,存储区间是连续的,占用内存严重,故空间复杂度很大.但数组的二分查找时间复杂度小,为O(1),数组的特点是寻址容易,插入和删除困难.今天学习另外的 ...
- Ncurses - Panel
当你需要创建许多窗口时,你很快就会发现它们会变得难以管理.Panel library提供了很好的解决方案. Panel 实际上是一个窗口,通过容器 - 栈 来管理,栈顶的 panel 是完全可见的,其 ...
- Note for "Some Remarks on Writing Mathematical Proofs"
John M. Lee is a famous mathematician, who bears the reputation of writing the classical book " ...