Distilling the Knowledge in a Neural Network
url: https://arxiv.org/abs/1503.02531
year: NIPS 2014
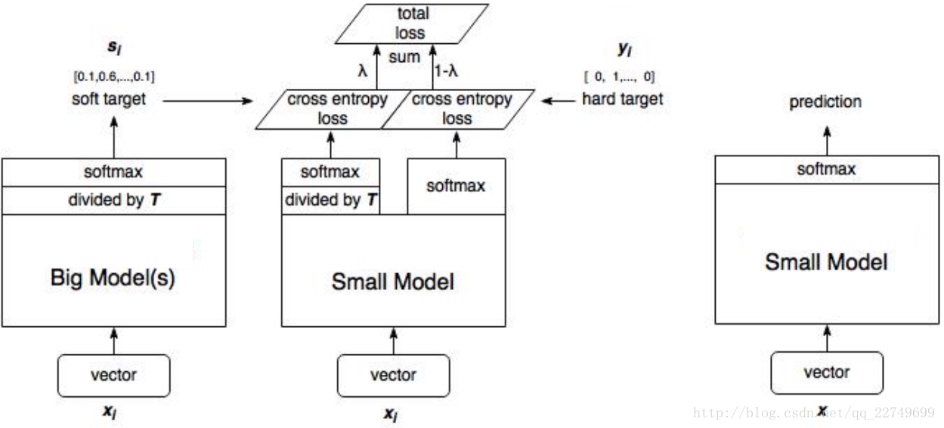 


简介
将大模型的泛化能力转移到小模型的一种显而易见的方法是使用由大模型产生的类概率作为训练小模型的“软目标”
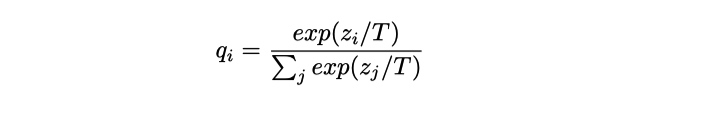 

其中, T(temperature, 蒸馏温度), 通常设置为1的。使用较高的T值可以产生更软的类别概率分布。 也就是, 较高的 T 值, 让学生的概率分布可以更加的接近与老师的概率分布,
下面通过一个直观的例子来感受下
def softmax_with_T(logits, temperature):
for t in temperature:
total = 0
prob = []
for logit in logits:
total += np.exp(logit/t)
for logit in logits:
prob.append(np.exp(logit/t) / total)
print('T={:<4d}'.format(t), end=' ')
for p in prob:
print('{:0.3f}'.format(p), end=' ')
print()
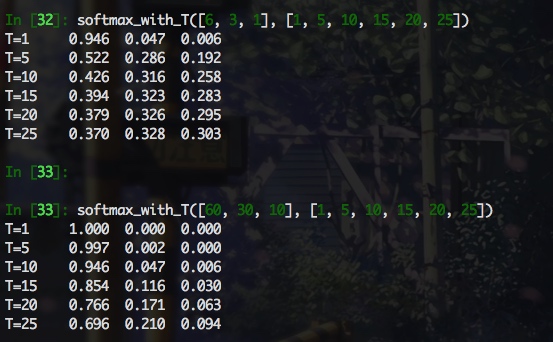 

可以看出, softmax 输出的项比例与 logits原始比例之间的关系与 logits 本身的模长以及 T 值大小相关, 感觉 T 值需要仔细调整下, 至少能反应 logits 之间的大致关系, 而且可以看出, softmax_with_T 受两个变量的影响, 直接来比较的话, 比较难分析. 当 T 远大于 logits 的模长时, softmax 的输出尺度在相同的数量级下(如logits=[6,3,1], T=25), 这样看的话, 即使老师和学生的 logit 相差很远, 经过具有很大 T 的 softamx 之后, 数量级几乎相同, 这样是不合理的. 但是, 下面的公式推导结果加上实验结果表明, 认真看梯度才是王道, 看输出的话, 完全找不到感觉, 对于软标签交叉熵损失
梯度推导
= \frac{1}{T} \left( \frac{e^{z_i/T}}{\sum_je^{z_j/T}} - \frac{e^{v_i/T}}{\sum_je^{v_j/T}}\right)}}
\]
\(e^x\)泰勒展开
x\rightarrow 0, \quad e^x \approx 1+x}
\]
\(T\rightarrow \infty\)时, \(\frac{Z_i}{T}\rightarrow 0\)
\]
假设logits已经单独进行了zero-center中心化处理,那么,
\Downarrow \\
\bf{\frac{\partial{C}}{\partial{z_i}} \approx \frac{1}{NT^2}{(z_i-v_i)}}
\]
这样的话, 当T值最够大, 方法就变为求老师和学生的 logits 的 L2 距离了.
| 术语 | 说明 |
|---|---|
| \(q^{soft}\) | 老师模型的 softmax 输出软标签 |
| \(q^{hard}\) | 训练集 one-hot 硬标签 |
| \(p^{soft}\) | 学生模型的 softmax 输出软标签 |
| \(p^{hard}\) | 学生模型的 softmax 输出硬标签(T=1) |
\]
论文中发现通常给予硬标签损失函数 \(\color{red}{可忽略不计的较低权重}\) 可以获得最佳结果。 由于软目标产生的梯度的大小为 \(\frac{1}{T^2}\),因此当使用硬目标和软目标时,将它们乘以 \(T^2\) 是很重要的, 这确保软硬标签对梯度相对贡献在一个数量级。
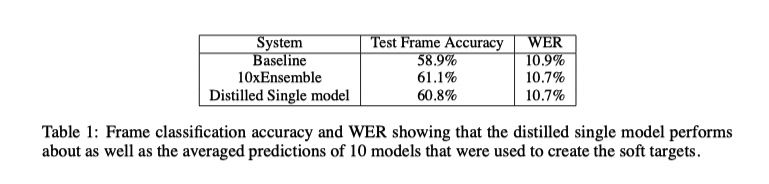
实验结果

思考
软标签交叉熵函数与 KL 散度的联系
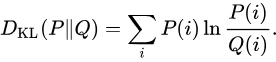 

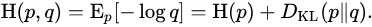 

上式中, 由于 p 为老师的预测结果, 模型蒸馏时候, 老师模型被冻结, 从梯度反传来看, 软标签交叉熵函数 等价于 KL 散度.
对于我而言, 这篇论文相对于 Do Deep Nets Really Need to be Deep? 贡献就在于, 将 L2距离 和 KL 散度统一到一个公式中了, 由于到 T 足够大, KL 散度的梯度与 L2 距离的一样. 这篇论文中其他部分没有读懂, 没有看到其他想要的东西. 后面知识积累了有机会在看看有没有新感受吧.
蒸馏入门的话, 推荐 Do Deep Nets Really Need to be Deep? 这篇论文. 从实验分析来说, 各种分析都很到位, 分析的方式也是易读的, 容易理解. 就工程效果来看, 实际上Distilling the Knowledge in a Neural Network 这篇论文有效时候, T一般都挺大的, 那么KL 散度的实际的效果就是 L2 距离, 不如直接用 L2 距离, 理解上简单, 调节超参少, 效果也非常好.
Distilling the Knowledge in a Neural Network的更多相关文章
- 【DKNN】Distilling the Knowledge in a Neural Network 第一次提出神经网络的知识蒸馏概念
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复"DKNN",即可获得课件电子资源. 文章已经表明,对于将知识从整体模型或高度正则化的大型模型转换为较小的蒸馏模型,蒸馏非常 ...
- 【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容 G. Hinton, O. Vinyals, and J. Dean, "Distilling the Knowledge in a Neural Network." 2 ...
- 1503.02531-Distilling the Knowledge in a Neural Network.md
原来交叉熵还有一个tempature,这个tempature有如下的定义: \[ q_i=\frac{e^{z_i/T}}{\sum_j{e^{z_j/T}}} \] 其中T就是tempature,一 ...
- 论文笔记:蒸馏网络(Distilling the Knowledge in Neural Network)
Distilling the Knowledge in Neural Network Geoffrey Hinton, Oriol Vinyals, Jeff Dean preprint arXiv: ...
- 论文笔记之:Progressive Neural Network Google DeepMind
Progressive Neural Network Google DeepMind 摘要:学习去解决任务的复杂序列 --- 结合 transfer (迁移),并且避免 catastrophic f ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- [Tensorflow] Cookbook - Neural Network
In this chapter, we'll cover the following recipes: Implementing Operational Gates Working with Gate ...
- (zhuan) Recurrent Neural Network
Recurrent Neural Network 2016年07月01日 Deep learning Deep learning 字数:24235 this blog from: http:/ ...
- 课程一(Neural Networks and Deep Learning),第四周(Deep Neural Networks)——2.Programming Assignments: Building your Deep Neural Network: Step by Step
Building your Deep Neural Network: Step by Step Welcome to your third programming exercise of the de ...
随机推荐
- [C]表达式结合规律和运算符优先级
表达式结合规律 如果运算符具有相同的优先级(precedence)有些表达式的结合方式是从左往右,有些则是从右往左结合的(例如赋值运算符): 表达式 结合律 组合方式 a/b%c 从左往右 (a/b) ...
- fiddler添加IP列
willow一个规则管理插件 Ctrl+F查找“static function Main()”字符串,然后添加以下代码: FiddlerObject.UI.lvSessions.AddBoundCol ...
- Linux下安装Redis以及遇到的问题
参考链接:https://www.cnblogs.com/zdd-java/p/10288734.html https://www.cnblogs.com/uncleyong/p/9882843.ht ...
- PHPStorm 初遇 Xdebug (xdebug代码调试及性能分析)
centos 7 下PHP7安装xdebug # 下载xdebug wget https://xdebug.org/files/xdebug-2.7.2.tgz # 解压 tar -xf xdebug ...
- 在CV尤其是CNN领域的一些想法
现在的CNN还差很多,未来满是变数. 你看,现在的应用领域也无非merely就这么几类----分类识别,目标检测(定位+识别),对象分割......,但是人的视觉可不仅仅这么几个功能啊!是吧. 先说说 ...
- Python 接口自动化常用方法封装
#!/usr/bin/env python # -*- coding:utf-8 -*- # ************************************* # @Time : 2019/ ...
- spark log4j 日志配置
现在我们介绍spark (streaming) job独立配置的log4j的方法,通过查看官方文档,要为应用主程序(即driver端)或执行程序使(即executor端)自定义log4j配置,需要两步 ...
- (转)GitHub Desktop 拉取 GitHub上 Tag 版本代码
转自:GitHub Desktop 拉取 GitHub上 Tag 版本代码 一直在使用 GitHub Desktop 图形化 git 管理工具,统一项目框架版本时需要切换到ThinkPHP Tag 分 ...
- Microsoft Visual Studio 2017 找不到 Visual Studio Installer
Microsoft Visual Studio 2017 找不到 Visual Studio Installer ? 打开vs2017 ,选择 工具 --> 扩展和更新 --> 联机,搜索 ...
- 查询物料单位PAC成本
select cpp.period_name 期间名称, ccga.organization_id 组织ID, ood.ORGANIZATION_CODE 组织代码, OOD.ORGANIZATION ...