05爬虫-requests模块基础(2)
今日重点:
1、代理服务器的设置
2、模拟登陆过验证码(静态验证码)
3、cookie与session
4、线程池
1、代理服务器的设置
有时候使用同一个IP去爬取同一个网站,久了之后会被该网站服务器屏蔽。那么我们应该1怎么处理这个问题呢?
解决思路:
如果我们爬取网站,对方服务器显示的是别人的IP地址,那么即使对方服务器把IP禁掉,屏蔽。也无关紧要,我们可以继续换其他的IP地址继续爬取。
因此使用代理服务器,就可以解决问题。
网上有很多代理服务器的网站一般情况花钱比较安全,当然,你要识别这个IP是否是安全的。
代理类型:
HTTP:只能发送http协议的
HTTPS:发送HTTPS协议的
匿名度:
透明:对方服务器能知道你用代理而且知道你的IP地址
匿名:对方服务器知道你用代理,不知道你服务器
高匿名:对方不知道你用代理。
代理网站:
https://www.kuaidaili.com/free/(快代理有免费的,不过还是危险)
其余随便百度,网上有很多代理服务器
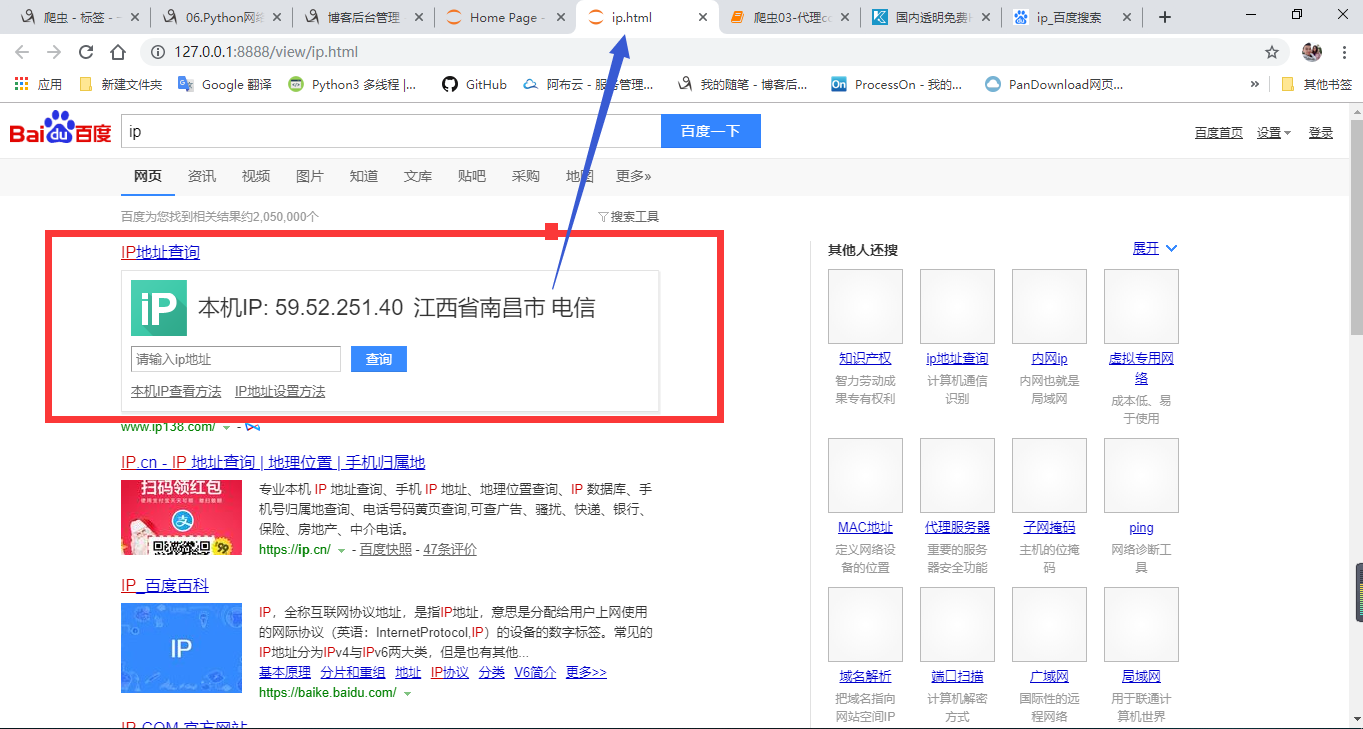
查看本机ip,接下来测试代理ip

代理服务代码展示如下:
import requests url = "https://www.baidu.com/s?wd=ip"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
#请求多携带一个proxies的参数,类型为http的键值对
response = requests.get(url = url,headers=headers,proxies={"http":"115.233.210.218:808"}).text
#存入当前目录下的文件
with open("./ip.html","w",encoding="utf-8") as fp:
fp.write(response)
print(response)
看结果显示的ip地址就是我找的代理里面的地址。
2、模拟登陆过验证码(静态验证码)
处理完代理问题,接下来比如我们爬取的网站需要登陆,然而登录多半都会出现让用户输入入验证码,因此我们需要用代码模拟出人输入验证码。
在遇到验证码的时候,在实际的项目中,验证码的处理方式有三种:
1)手动输入验证码。(对于小型的项目我们可以采取手动输入)
2)通过编写程序自动识别验证码。(这样效率会很低,机器学习识别验证码)
3)通过一些打码接口实现,让别人通过接口帮我们输入验证码,但是需要支付一点费用。
但实现以上方式,均要分析验证码的图片从哪里来,是不是验证码也会夹带cookie(cookie,稍后会提到cookie)。只要分析完成,将验证码识别出来,作为动态参数传入
下面即将提交的数据中,那么就完成静态验证码(文字输入)验证。
在这里可以有个大型平台,云打码(http://www.yundama.com/)充值了,添加软件,然后复制相关开发者python的源代码,登录自己的账号。识别的类型填入代码,将识别结果输出。作为动态参数传入。
接下来解决登录的问题。因此引出(cookie)
3、cookie与session
在爬虫的使用中,如果涉及登录等操作,经常会使用到Cookie。那么什么是Cookie呢?
简单来说,我们访问每一个互联网页面,都是通过HTP协议进行的,而HTTP协议是一个无状态协议,所谓的无状态协议即无法维持会话之间的状态。
比如,仅使用HTTP协议的话,我们登录一个网站的时候,假如登录成功了,但是当我们访问该网站的其他网页的时候,该登录状态则会消失,此时还需要再登录一次,只要页面涉及更新,就需要反复的进行登录,这是非常不方便的。
所以此时,我们需要将对应的会话信息,比如登录成功等信息通过- 些方式保存下来,比较常用的方式有两种:通过Cookie保存会话信息或通过Session保存会话信息。我们分别说一下这两种方式。
如果是通过Cookie保存会话信息,此时会将所有的会话信息保存在客户端,当我们访问同一个网站的其他页面的时候,会从Cookie中读取对应的会话信息,从而判断目前的会话状态,比如可以判断是否已经登录等。显然,这种方式我们会用到Cookie。
如果是通过Session保存会话信息,会将对应的会话信息保存在服务器端,但是服务器端会给客户端发SessionID等信息,这些信息一般存在客户端的Cookie中,当然,如果客户端禁止了Cookie,也会通过其他方式存储。但是,目前来说,大部分的情况还是会将这一部分的信息存到Cookie中。然后,用户在访问该网站其他网页的时候,会从Cookie中读取这一部分信息, 然后从服务器中的Session中根据这部分Cookie信息检索出该客户端的所有会话信息,然后进行会话控制。显然,使用Session的方式来保存会话信息,大部分的时候,还是会到Cookie。
通过前面的分析,可以看到,不管是通过哪种方式进行会话控制,在大部分时候,都会用到Cookie。比如在爬虫的登录中,如果没有Cookie,我们登录成功了一个网页,但如果我们要爬去该网站的其他网页的时候,仍然会是未登录状态,如果有了Cookie,当我们登录成功后,爬取该网站的其他网页时,则会保持登录状态进行内容的爬取。
总结来说就是:
1)我们访问每一一个互联网页面,都是通过HTP协议进行的,而HTTP协议是一个无状态协议,所谓的无状态协议即无法维持会话之间的状态。
2)会话信息控制比较常用的方式有两种:通过Cookie保存会话信息、通过Session保存会话信息。
3)如果是通过Session保存会话信息,会将对应的会话信息保存在服务器端,但是服务器端会给客户端发SessionID等信息,这些信息一般存在客户端的Cookie中,当然,如果客户端禁止了Cookie,也会通过其他方式存储。但是,目前来说,大部分的情况还是会将这-部分的信息存到Cookie中。然后,用户在访问该网站其他网页的时候,会从Cookie中读取这一部分信息,然后从服务器中的Session 中根据这一部分 Cookie信息检索出该客户端的所有会话信息,然后进行会话控制。显然,使用Session的方式来保存会话信息,大部分的时候,还是会用的Cookie。
4)如果要获得真实的登录地址,我们需要进行分析,分析方法主要有两种,第种方法是通过F12调出调试界面进行分析,第二种方法是使用工具软件进行分析,常用的工具软件有Fiddler(一个伪服务器,你的客户端发送的都要经过它传输)。
登录人人网:
import requests
if __name__ == "__main__": #登录请求的url(通过抓包工具获取)
post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201873958471'
#创建一个session对象,该对象会自动将请求中的cookie进行存储和携带
session = requests.Session()
#伪装UA15675334817
formdata = {
'email': '',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '',
'captcha_type': 'web_login',
'password': '02eb37d2b5474eb9b086c7cdea2adea2f3af747d674cb598c1fab6732a62e555',
'rkey': '3c7c4d177b8f7edfa59e7f629fcee3bc',
'f': 'http%3A%2F%2Fwww.renren.com%2F972358414',
}
#使用session发送请求,目的是为了将session保存该次请求中的cookie
session.post(url=post_url,data=formdata,headers=headers) get_url = 'http://www.renren.com/972358414/profile'
#再次使用session进行请求的发送,该次请求中已经携带了cookie
response = session.get(url=get_url,headers=headers)
#设置响应内容的编码格式
#将响应内容写入文件
with open('./renren.html','w',encoding="utf-8") as fp:
fp.write(response.text)
4、线程池
基于multiprocessing.dummy线程池的数据爬取
练习:需求:爬取梨视频的视频信息
import requests
from lxml import etree
import re
import random
from multiprocessing.dummy import Pool #爬取视频的下载和保存都需要等待很长时间 这时候 可以采取IO密集型多线程解决
#因此引入线程池
pool = Pool() headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
} url = "https://www.pearvideo.com/category_1" vedio_page = requests.get(url=url,headers=headers).text tree = etree.HTML(vedio_page)
name_url = tree.xpath('//*[@id="listvideoList"]/ul/li/div/a/@href') vedio_urls = []#存储视频的url for i in name_url:
vedios_url = "https://www.pearvideo.com/" + i
res = requests.get(url=vedios_url,headers=headers).text
tre = etree.HTML(res)
ex = 'srcUrl="(.*?)",vdoUrl'
vedio = re.findall(ex,res,re.S)[]
vedio_urls.append(vedio)
print(vedio_urls)
#使用线程池进行视频数据下载
def load(link):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
resul = requests.get(url=link,headers=headers).content
return resul
video_data_list = pool.map(load,vedio_urls)
#使用线程池进行视频数据保存
def save(vedioa):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
name = str(random.randint(,)) + ".mp4"
with open(name,"wb") as fp:
fp.write(vedioa)
print(name,":下载成功")
pool.map(save,video_data_list) pool.close()#关闭线程
pool.join()#继续下一个线程
总结:爬取梨视频思路,首先找到视频所在标签位置,在进入视频地址所在位置,接下来请求视频地址为空,仔细寻找发现视频的地址是由js控制显示的。
bs4与lxml都是对标签进行解析的,而我们需要的是js中的代码,因此我们需要用到正则表达式。正则表达式匹配出视频后缀为.mp4的。然后利用线程池
爬取下载数据,再利用线程池保存数据,二进制数据。(思路一定要分析清楚,才开始写代码,不然容易出现问题)
05爬虫-requests模块基础(2)的更多相关文章
- 03爬虫-requests模块基础(1)
requests模块基础 什么是requests模块 requests模块是python中原生基于网络模拟浏览器发送请求模块.功能强大,用法简洁高效. 为什么要是用requests模块 用以前的url ...
- 爬虫之requests模块基础
一.request模块介绍 1. 什么是request模块 - python中原生的基于网络请求的模块,模拟浏览器发起请求. 2. 为什么使用request模块 - urllib需要手动处理url编码 ...
- requests模块基础
requests模块 .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bor ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
- 爬虫 requests模块的其他用法 抽屉网线程池回调爬取+保存实例,gihub登陆实例
requests模块的其他用法 #通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下 Host Referer #大型网站通常都会根据该参数判断请求的来源 ...
- 爬虫——requests模块
一 爬虫简介 #1.什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样. #2.互联网建立的目的? 互联网的核心价值在于数据的共享/传递:数据是 ...
- 2 爬虫 requests模块
requests模块 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,reques ...
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- 爬虫--requests模块学习
requests模块 - 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能 ...
随机推荐
- 表单生成器(Form Builder)之mongodb表单数据查询——统计查询求和
上一篇笔记仅是记录了一下简单的关联查询,根据笔记中的场景:将某一车辆关联的耗损记录全部放在了一个字段当中.不知道现在中有没有这种场景,我们的应用中没有类似的场景,可能我们更关注的是某车辆的总耗损金额和 ...
- Ubuntu下配置IP地址
17.10版本之前: Ubuntu的网卡配置文件跟CentOS的不一样,Ubuntu的网卡配置文件是/etc/network/interfaces.我们用vi /etc/network/interfa ...
- Lua 5.1 学习笔记
1 简介 2 语法 2.1 语法约定 2.1.1 保留关键字 2.1.2 操作符 2.1.3 字符串定义 2.2 值与类型 2.2.1 强制转换 2.3 变量 2.3.1 索引 2.3.2 环境表 2 ...
- mysql研究跟进
count(1)对比 count(*) count(N),N指的是列的序列号,innodb引擎下一般为主键列:count(*),mysql优化器也会将统计列自动优化.所以日常使用区别不大 阿里规范里的 ...
- Excel上下标如何设置?
Excel表格怎么设置上下标?Excel上下标设置技巧 在21世纪的我们,平时的工作和学习中,经常会使用到一些专业的文档,比如方程式.数据的公式和科学计数等,其中均会涉及到许多的上下标符号输入以及使用 ...
- 剑指Offer-39.把数组排成最小的数(C++/Java)
题目: 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323. 分析: 将数组 ...
- android屏幕监视工具 android screen monitor使用
android screen monitor是一个非常好用的手机屏幕监视工具,可以将你的手机界面动态的显示出来,可用于项目演示. 这个工具就是其实一个jar文件,不到300KB大小,依赖jdk,并且还 ...
- 在Asp.Net或.Net Core中配置使用MarkDown富文本编辑器有开源模板代码(代码是.net core3.0版本)
研究如何使用Markdown你们可能要花好几天才能搞定,但是看我的文章或者下载了源码,你搞定一般在10分钟之内.我先给各位介绍下它: Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯 ...
- C#之Form表单认证
原文地址: https://blog.csdn.net/chadcao/article/details/7859394 ASP.NET的安全认证,共有“Windows”.“Form”.“Passpor ...
- CreateWindowW()函数
函数原型为: 该函数利用已经注册的窗口类 创建一个窗口,并返回该窗口的句柄 HWND CreateWindow( LPCTSTR lpClassName, //窗口类名称,也可以是控件名称 LPCTS ...