MapReduce 的 shuffle 过程中经历了几次 sort ?
shuffle 是从map产生输出到reduce的消化输入的整个过程。
排序贯穿于Map任务和Reduce任务,是MapReduce非常重要的一环,排序操作属于MapReduce计算框架的默认行为,不管流程是否需要,都会进行排序。
在MapReduce计算框架中,主要用到了两种排序方法:快速排序和归并排序
1)快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另外一部分的所有数据都小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此使整个数据成为有序序列。
2)归并排序:归并排序在分布式计算里面用的非常多,归并排序本身就是一个采用分治法的典型应用。归并排序是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列。
在map任务和reduce任务的过程中,一共发生3次排序操作。
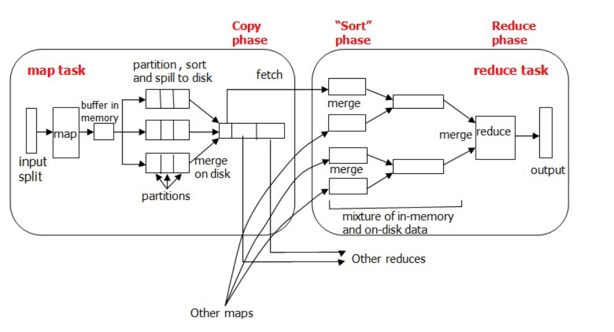
当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阈值,在刷写磁盘之前,后台线程会将缓冲区的数据划分成相应的分区。在每个分区中,后台线程按键进行内排序,如下图所示:
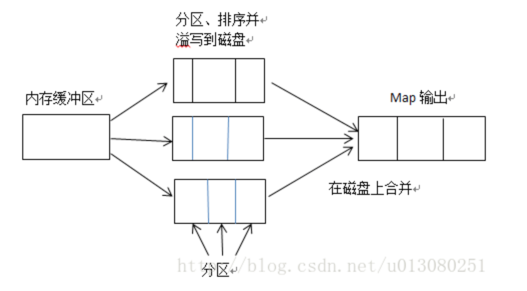
在Map任务完成之前,磁盘上存在多个已经分好区,并排好序的、大小和缓冲区一样的溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过第一次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序。
在shuffle阶段,需要将多个Map任务的输出文件合并,由于经过第二次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序,如下图所示。
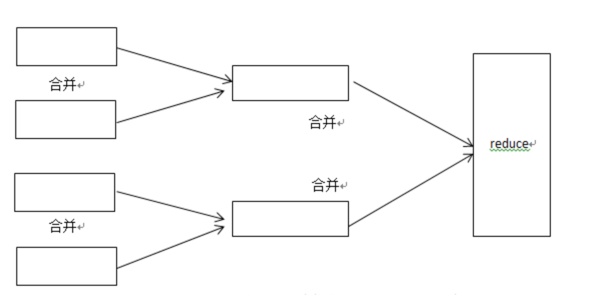
在这3次排序中第一次是在内存缓冲区做的排序,使用的算法是快速排序,第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序。
MapReduce 的 shuffle 过程中经历了几次 sort ?的更多相关文章
- MapReduce的Shuffle过程介绍
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop MapReduce的Shuffle过程
一.概述 理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看. 二. MapReduce确保每个reducer的输入都是按键排序的.系统执行 ...
- mapReduce的shuffle过程
http://www.jianshu.com/p/c97ff0ab5f49 总结shuffle 过程: map端的shuffle: (1)map端产生数据,放入内存buffer中: (2)buffer ...
- shuffle过程中的信息传递
依据Spark1.4版 Spark中的shuffle大概是这么个过程:map端把map输出写成本地文件,reduce端去读取这些文件,然后执行reduce操作. 那么,问题来了: reducer是怎么 ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- Shuffle过程
Shuffle过程 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整 ...
- 2.27 MapReduce Shuffle过程如何在Job中进行设置
一.shuffle过程 总的来说: *分区 partitioner *排序 sort *copy (用户无法干涉) 拷贝 *分组 group 可设置 *压缩 compress *combiner ma ...
随机推荐
- Nginx使用中遇到的问题记录
问题一.关于空格 nginx配置对空格十分敏感,在关键字和符号的前后,一定记得有空格(或换行).一个典型的场景是 if { } 语句,大括号前后要有空格,否则可能出现非预期行为. 问题二.关于serv ...
- ubuntu16.04下chrome安装flash插件
最近自己的ubuntu安装了最新的chrome54版本,发现视频无法播放,提示flash版本过期,原来最新的chrome已经不内置flash插件了,需要自己安装. 方法/步骤 1.安装chrome打开 ...
- Python格式化字符串(f,F,format,%)
# 格式化字符串: 在字符串前加上 f 或者 F 使用 {变量名} 的形式来使用变量名的值 year = 2020 event = 'Referendum' value = f'Results of ...
- H5移动端手势密码组件
项目简介 最近参加了2017年360前端星计划,完成了一个有趣的UI组件开发大作业,借机和大家分享一下移动端开发的技术啦~~ 本项目采用原生JS和Canvas实现移动端手势密码组件,支持手势密码设置和 ...
- Vulhub Docker环境部署
1:安装Linux 2:安装Docker : curl -s https://get.docker.com/ | sh 3:安装Docker-compose curl -s https://boots ...
- 学习Hibernate5 JPA这一篇就够了
配套资料,免费下载 链接:https://pan.baidu.com/s/158JkczSacADez-fEMDXSYQ 提取码:2ce1 复制这段内容后打开百度网盘手机App,操作更方便哦 第一章 ...
- c++之广度优先搜索
广度优先搜索BFS(Breadth First Search)也称为宽度优先搜索,它是一种先生成的结点先扩展的策略. 在广度优先搜索算法中,解答树上结点的扩展是按它们在树中的层次进行的.首先生成第一层 ...
- Hyperledger Fabric 部署
Hyperledger Fabric 部署 Hyperledger Fabric需要使用Docker.Go环境. Docker环境安装 Docker环境安装 直接查看这一篇,安装好之后将当前用户非ro ...
- Homekit_Dohome_月球灯
此款月球灯可以使用Homekit或者Dohome App进行有效的智能控制,支持多种色彩和亮度调节,功能强大,有兴趣的可以去以下链接看看: https://item.taobao.com/item.h ...
- JS实例-全选练习
<!DOCTYPE html><html lang="zh"><head> <meta charset="UTF-8" ...