Tensorflow学习笔记2019.01.22
 tensorflow学习笔记2
tensorflow学习笔记2
edit by Strangewx 2019.01.04
4.1 机器学习基础
4.1.1 一般结构:
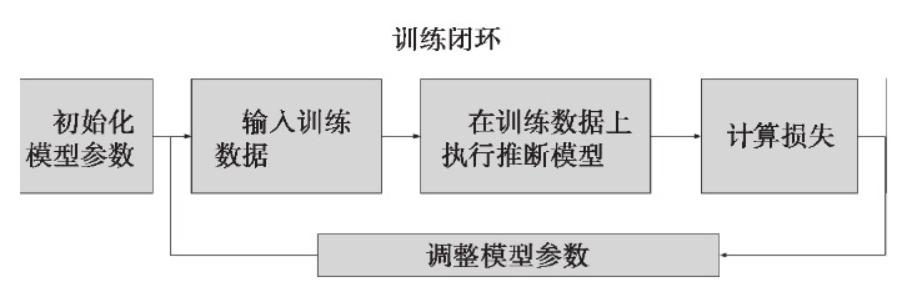

初始化模型参数:通常随机赋值,简单模型赋值0
训练数据:一般打乱。random.shuffle()
在训练数据上推断模型:得到输出
计算损失:loss(X, Y)多种损失函数
调整模型参数:最小化损失 SGD等优化方法。
评估:70%:30% 分训练集和校验集
代码框架:
首先模型参数初始化,
然后为每个训练闭环中的运算定义一个方法:读取训练数据input,计算推断模型inference,计算相对期望输出的损失loss,调整模型参数train,评估训练模型evaluate,
之后启动一个Session会话对象,并进行闭环训练。
模型满意之后,导出模型,用它对所需要的数据进行推断,例如:为冰激凌App用户推荐不同口味的冰激凌。
import tensorflow as tf
#初始化变量和模型参数,定义训练闭环中的运算
def inference(X):
#计算推断模型在数据X上的输出,并将结果返回。
def loss(X, Y):
#依据训练数据X和期望输出Y计算损失
def inputs():
#读取或生成训练数据X,期望输出Y
def train(total_loss):
#依据计算的总损失,训练或调整模型参数。
def evalute(sess, X, Y):
#队训练模型进行评估
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coor = tf.train.Coordinator()
threads = tf.train.start_queue_rnners(sess=sess, coor=coord)
#实际训练迭代轮数
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
#为了调试和学习的目的,查看损失在训练过程中的变化
if step % 100 == 0:
print("loss:",sess.run([total_loss]))
evalute(sess, X, Y)
coord.request_stop()
coord.join(thread)
sess.close()
保存训练检查点&恢复
tf.train.Saver()类
目的:
将数据流图中的变量保存到专门的二进制文件中。周期性保存所有变量,创建检查点(checkpoint)文件,并在必要时从最近的检查点恢复。
每次调用tf.train.Saver.save 方法,都会创建一个 my-model-step的检查点文件,如my-model-1000,my-model-2000等。默认情况保存近5次的文件
在上述框架稍作修改:
#模型定义代码 ...
#创建一个Saver()类
saver = tf.train.Saver()
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
#模型设置...
#实际的闭环训练
for step in range(training_steps):
sess.run([train_op])
if step % 1000 == 0:
saver.save(sess, 'my-model', global_step=step)
#模型评估。。。
#最终模型保存
saver.save(sess, 'my-model', global_step=training_steps)
sess.close()
tf.train.get_checkpoint_state
验证之前是否有检查点文件被保存下来
tf.train.Saver.restore
负责恢复变量值。
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
#模型设置...
initial_step = 0
#验证之前是否存在检查点文件
ckpt = tf.train.get_checkpoint_state(os.path.dirname(__file__))
if ckpt and ckpt.model_checkpoint_path:
#从检查点恢复模型参数
saver.restore(sess, ckpt.model_checkpoint_path)
initial_step = int(ckpt.model_checkpoint_path.split('-', 1)[1])
#实际的闭环训练
for step in range(initial_step, training_steps):
#...
4.1.2 整合架构
包括:一般架构,训练点保存和恢复
import tensorflow as tf
#初始化变量和模型参数,定义训练闭环中的运算
def inference(X):
#计算推断模型在数据X上的输出,并将结果返回。
def loss(X, Y):
#依据训练数据X和期望输出Y计算损失
def inputs():
#读取或生成训练数据X,期望输出Y
def train(total_loss):
#依据计算的总损失,训练或调整模型参数。
def evalute(sess, X, Y):
#队训练模型进行评估
#--checkpoint--创建一个Saver()类
saver = tf.train.Saver()
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coor = tf.train.Coordinator()
threads = tf.train.start_queue_rnners(sess=sess, coor=coord)
#--checkpoint恢复--
initial_step = 0
#验证之前是否存在检查点文件
ckpt = tf.train.get_checkpoint_state(os.path.dirname(__file__))
if ckpt and ckpt.model_checkpoint_path:
#从检查点恢复模型参数
saver.restore(sess, ckpt.model_checkpoint_path)
initial_step = int(ckpt.model_checkpoint_path.split('-', 1)[1])
#实际训练迭代轮数
training_steps = 10000
for step in range(initial_step, training_steps):
sess.run([train_op])
#为了调试和学习的目的,查看损失在训练过程中的变化
if step % 100 == 0:
print("loss:",sess.run([total_loss]))
#--checkpoint--每1000次保存训练检查点
if step % 1000 == 0:
saver.save(sess, 'my-model', global_step=step)
evalute(sess, X, Y)
#--checkpoint--最终模型保存
saver.save(sess, 'my-model', global_step=training_steps)
coord.request_stop()
coord.join(thread)
sess.close()
4.2 线性回归
Y=XW + b
实例:脂肪含量和年龄,体重的关系。
代码:
import tensorflow as tf
import numpy as np
#初始化变量和模型参数
W = tf.Variable(tf.zeros([2,1]), name="weights")
b = tf.Variable(0., name="bias")
#定义闭环训练的方法
def inference(X):
return tf.matmul(X, W) + b
def loss(X, Y):
#此处采用均方误差
Y_predicted = inference(X)
return tf.reduce_sum(tf.squared_difference(Y, Y_predicted))
def inputs():
#体重年龄
weight_age = [[84, 46], [73, 20], [65, 52], [70, 30],[76, 57],
[69, 25], [63, 28], [72, 36], [79, 57], [75, 44],
[27, 24], [89, 31], [65, 52], [57, 23], [59, 60],
[69, 48] ,[60, 34], [79, 51], [75, 50], [82, 34],
[59, 46], [67, 23],[85, 37], [55, 40], [63, 30]]
#血脂含量
blood_fat_content = [354, 190, 405, 263, 451, 302, 288,385, 402,
365, 209, 290, 346, 254, 395, 434, 220, 374,
308,220, 311, 181, 274, 303, 244]
return tf.to_float(weight_age), tf.to_float(blood_fat_content)
def train(total_loss):
learning_rate = 0.0000001
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
def evaluate(sess, X, Y):
print(sess.run(inference([[80., 25.]])))
print(sess.run(inference([[65., 25.]])))
print(sess.run(inference([[84., 46.]])))
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
# 开启一个协调器
coord = tf.train.Coordinator()
# 使用start_queue_runners 启动队列填充
threads = tf.train.start_queue_runners(sess, coord)
#实际训练迭代轮数
training_steps = 5000
for step in range(training_steps):
sess.run([train_op])
#为了调试和学习的目的,查看损失在训练过程中的变化
if step % 1000 == 0:
print("loss:",sess.run([total_loss]))
print(W.eval(), b.eval())
evaluate(sess, X, Y)
coord.request_stop()
coord.join(threads)
sess.close()
'''
输出:
loss: [7608772.5]
[[2.6675313]
[1.5194209]] 0.03884
loss: [5330322.0]
[[3.5245109]
[1.5017073]] 1.1460863
loss: [5318362.0]
[[3.512061 ]
[1.4964026]] 2.2396185
loss: [5306486.5]
[[3.4996552]
[1.4911169]] 3.3292856
loss: [5294695.0]
[[3.4872932]
[1.4858491]] 4.415105
---evaluate result---
[[320.51013]]
[[268.3853]]
[[365.50278]]
'''
小插曲《typora使用指南》
参考:https://blog.csdn.net/moonclearner/article/details/52842679
表情
Tensorflow学习笔记2019.01.22的更多相关文章
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- tensorflow学习笔记(3)前置数学知识
tensorflow学习笔记(3)前置数学知识 首先是神经元的模型 接下来是激励函数 神经网络的复杂度计算 层数:隐藏层+输出层 总参数=总的w+b 下图为2层 如下图 w为3*4+4个 b为4* ...
- tensorflow学习笔记(2)-反向传播
tensorflow学习笔记(2)-反向传播 反向传播是为了训练模型参数,在所有参数上使用梯度下降,让NN模型在的损失函数最小 损失函数:学过机器学习logistic回归都知道损失函数-就是预测值和真 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- tensorflow学习笔记——VGGNet
2014年,牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发了新的深度卷积神经网络:VGGNet ,并取得了ILSVRC201 ...
- TensorFlow学习笔记0-安装TensorFlow环境
TensorFlow学习笔记0-安装TensorFlow环境 作者: YunYuan 转载请注明来源,谢谢! 写在前面 系统: Windows Enterprise 10 x64 CPU:Intel( ...
随机推荐
- 未来-区块链-Aliyun:阿里云IoT - 所知不止于感知
ylbtech-未来-区块链-Aliyun:阿里云IoT - 所知不止于感知 1.返回顶部 1. 基础产品接入 设备接入 设备管理 数据分析 应用开发 网络管理 边缘计算 设备认证 安全运营 AliO ...
- listview-android:打造万能通用适配器(转)
转载:https://blog.csdn.net/q649381130/article/details/51781921: 1.前言 listview作为安卓项目中一个的明星控件,它的适配器的写法是广 ...
- Java定时器小实例
有时候,我们需要在Java中定义一个定时器来轮询操作,比如每隔一段时间查询.删除数据库中的某些数据等,下面记录一下一种简单实现方式 1,首先新建一个类,类中编写方法来实现业务操作 public cla ...
- gevent-websocket初识
初试 from flask import Flask, request from geventwebsocket.handler import WebSocketHandler from gevent ...
- 《深度探索C++对象模型》读书笔记(二)
第三章:Data语意学 这一章主要讲了类中的数据在内存中是如何分配的,包括(多重)继承和多态. 让我们首先从一段代码开始: class X{}; class Y :virtual public X{} ...
- ef6.0+mysql配合使用的问题
折腾了很久由于所用到的各种库版本问题:后来终于组合成了一个可用的:记录下各种库的版本 ef6.0 mysql5.5 mysql-connector-net-6.9.12.msi mysql-for-v ...
- 01 jmeter性能测试系列_Jmeter的体系结构
深圳文鹏教育jmeter 性能测试讲义 概念 元件:元件代表jmeter工具菜单中的一个子菜单,比如HTTP请求.事务控制器.响应断言等: 组件:一组元件的集合(一个或者多个),比如逻辑控制器中有事务 ...
- C#中获取文件信息的代码
如下的内容内容是关于C#中获取文件信息的内容,应该对大伙有一些好处. FileInfo fi = new FileInfo(@"C:file.txt"); if(fi.Exists ...
- qt button clicked(bool) always false
今天用 qt 中的按键的时候,希望按键有两种状态,通过 clicked(bool) 发送信号给槽,结果一直发的是 false,不能为 true,后来终于找到问题了,有两种解决方法. 在 button ...
- 通过日志来看Spring跨库更新操作的事务
场景介绍: 一个项目俩个数据源,连接俩个不同的库 数据源初始化 @Configuration @MapperScan(basePackages = "com.qing.mapper.paym ...