【python】下载中国大学MOOC的视频
【python】下载中国大学MOOC的视频
脚本目标:
输入课程id和cookie下载整个课程的视频文件,方便复习时候看
网站的反爬机制分析:
分析数据包的目的:找到获取m3u8文件的路径
1. 从第一步分析数据包开始,就感觉程序员一定是做了反爬机制,从一开始就防备着了,网站在打开调试工具的时候会死循环在debugger上,代码写法和原理可以参考这篇文章【如何防止页面被调试_小敏哥的专栏-CSDN博客_网页禁止调试】,只需要停用断点就可以继续调试,在network里看数据包
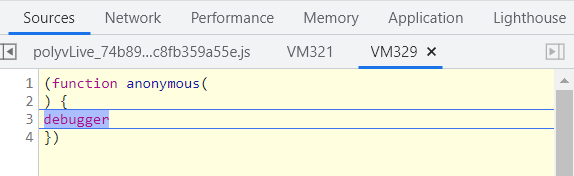
2. 搜索关键字m3u8,获得下载m3u8的链接
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de820f66b1081b2dbb1d6300ca9e91c8b349a14ab1e5b4e06c0887fe54fe47de9823059f726dc7bb86b92adbc3d5b34b1320647b25cf54eb8ac6ed1f0d7db7826b19bb0a5ea14ff29775bd482caa79ccf8b
简化得到
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8
通过get方式,下载查看,里面的ts下载链接是可以需要拼接的,文件没有加密,因此只需要用request发送数据包,就可以下载得到,接下来寻找构造数据包的依据
3. 分析数据包得到,m3u8文件的下载链接出现在另一个链接访问得到的内容里
链接为:https://vod.study.163.com/eds/api/v1/vod/video?videoId=1215086738&signature=75584967794f373450387775426e39512b565a6d4a4643384a366b3743766e556474475a7454466252672b6c5252306a744e585a61365031766269547650504454724750544c683252715a475876585962727a536f7431736a596d4f7843593577306d714654534864385873446e5470397a5675537a7233486836336d7a4355576e506745582b47762f2b37574b6972745365744d673d3d&clientType=1
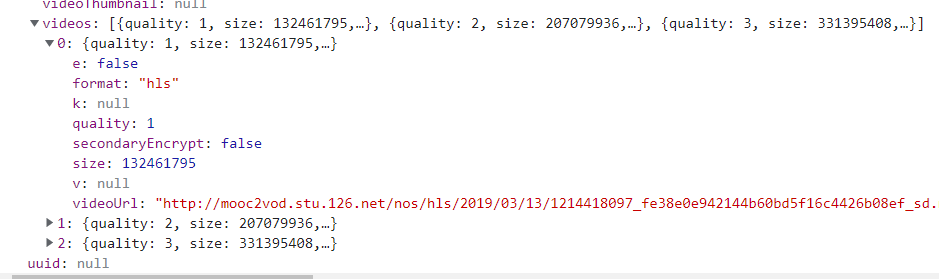
链接需要由videoId和signature,两个变量组成,两个变量必须对应,不然无法访问,并且是采用了http2的形式传输,相当于ban掉了request库,接下来需要找到videoId和其对应的signature
4.分析数据包得到signature的值被包含在以下url中,需要通过http2进行访问,并且在访问的同时需要POST提交一个数据包,数据包的内容为“bizId=1268148xxx&bizType=1&contentType=1
https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b5751”
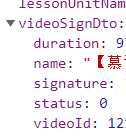
此时需要寻找bizId和csrfKey的值
5. 分析数据包得到,bizid,每节课的名称,每节课videoid(contentId)被存放在以下url的内容中,需要通过http2进行访问,并且在访问的同时需要POST提交一个数据包,数据包的内容为“termId: 1465388xxx”
https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b575
提交的数值和课程链接中tid后面的值相同,需要填写变量仅剩下csrfKey
6.csrfKey被存放在cookie的NTESSTUDYSI=中,只需要cookie就可以得到csrfKey。此时只需要cookie和课程id就能获得每个课程的m3u8文件下载链接
已知信息:
1. 网站的反爬机制
2. 视频ts文件没有加密
3. 网站使用http2协议,使用httpx代替request
4. 拿到m3u8文件的下载链接后,直接甩给上一篇写的m3u8的下载器,改一改拼接在一起,能用就行
5. 虽然在调试的时候提示是“非法的跨域请求”,但是没有判断referer的值,只是判断了cookie值
脚本思路:
1. 获得自己的cookie,从cookie中提取出NTESSTUDYSI=得到csrfKey
2. 用http2.x,且为post的方式访问“https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=csrfKey“,构造POST数据包 termId: tid。在得到的数据包内得到每节课的名称,每节课videoid(contentId),bizId(id)
3. 用http2.0,且为post的方式访问,访问做了跨域限制“https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=csrfKey”构造POST数据包bizId=bizId&bizType=1&contentType=1 。 得到signature
4. 用http2.0,且为get的方式访问https://vod.study.163.com/eds/api/v1/vod/video/videoId=videoId&signature=signature&clientType=1 得到videoUrl,就是一个m3u8的下载地址,删除问号后面的内容,直接访问就可以下载
5. 拼接上次写的脚本
最终功能代码:
import os
import re
import httpx
import time
import requests
import aiohttp
import asyncio
import aiofiles
obj = re.compile(r".*?NTESSTUDYSI=(?P<csrfkey>.*?);")
obj2 = re.compile(r".*?'units': \[{'id':(?P<id>.*?),")
obj3 = re.compile(r".*?'contentType': 1, 'contentId':(?P<bizld>.*?),")
obj4 = re.compile('.*?"signature":"(.*?)",')
obj5 = re.compile('.*?"videoUrl":"(?P<m3u8>.*?)\?ak')
obj6 =re.compile('.*?"name":"(.*?)",')
def init():
if not os.path.exists("./temp_data"):
os.mkdir("./temp_data")
if not os.path.exists("./cookie.txt"):
cookie = str(input("没有检测到cookie,请输入cookie>"))
with open("./cookie.txt", "w") as f:
f.write(f"{cookie}")
with open("cookie.txt", "r") as f:
cookie = f.read()
return cookie def get_video_id(csrfkey):
tid = str(input("输入课程的tid>"))
data = {"termId": f"{tid}"}
client = httpx.Client(http2=True)
resp = client.post(f"https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey={csrfkey}",headers=header, data=data)
resp.close()
json = resp.json()
shu_ju = str(json["result"]["mocTermDto"]["chapters"])
bizld = str(obj2.findall(shu_ju)).replace(" ","").replace("[","").replace("]","").replace("'","").split(",")
video_id = str(obj3.findall(shu_ju)).replace("' None', ","").replace(" ","").replace("'","").replace("[","").replace("]","").split(",")
print("获取bzid和video_id")
return bizld,video_id def get_signature(bizlds,csrfkey):
signatures=[]
client = httpx.Client(http2=True)
for bizld in bizlds:
data = {"bizId":f"{bizld}","bizType":"1","contentType":"1"}
resp=client.post(f"https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey={csrfkey}",headers=header,data=data)
resp.close()
signatures = signatures+obj4.findall(resp.text)
print("获取signatures")
return signatures def get_m3u8_url(video_ids,signatures):
m3u8_urls = []
merge_name = []
client = httpx.Client(http2=True)
for video_id,signature in zip(video_ids,signatures):
resp = client.get(f"https://vod.study.163.com/eds/api/v1/vod/video?videoId={video_id}&signature={signature}&clientType=1",headers=header)
resp.close()
time.sleep(2)
merge_name.append(str(obj6.findall(resp.text)).replace("[", "").replace("]", "").replace("'", ""))
m3u8_url = obj5.findall(resp.text)[0]
m3u8_urls.append(m3u8_url)
print("下面是合并文件名:",merge_name)
return m3u8_urls,merge_name
async def download_ts(file_name,download_url,session): async with session.get(download_url,headers=header) as resp:
async with aiofiles.open(f"temp_data/{file_name}",mode="wb") as f:
await f.write(await resp.content.read()) async def starter(name,m3u8_url):
tasks=[]
async with aiohttp.ClientSession() as session:
#https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144b60bd5f16c4426b08ef_sd0.ts
url = str(m3u8_url).rsplit("/",1)[0]
with open(f"temp_data/{name}.txt", "r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip()
file_name = line # 得下载的ts文件名
download_url = url + "/" + line
print("下载链接是:",download_url)
task = download_ts(file_name, download_url, session)
tasks.append(task)
await asyncio.wait(tasks) # 等待任务执行结束
print("文件下载完成") def m3u8_files_download(url,name): #下载m3u8文件
resp = requests.get(url)
with open(f"temp_data/{name}.txt",mode="wb") as f:
f.write(resp.content)
resp.close()
def verification(name):
files=[]
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line=line.strip()
if os.path.exists(f"temp_data/{line}"):
continue
else:
files.append(line)
print("以下文件缺失,请手动查看:",files)
def merge_ts(file_name,merge_name):
new_name = str(merge_name)
with open(f"./{new_name}.mp4", "ab+") as f:
with open(f"temp_data/{file_name}.txt","r") as f2:
for line in f2:
if line.startswith("#"):
continue
else:
line = line.strip().split("/")[-1].strip()
ts_name = line
try:
with open(f"temp_data/{ts_name}","rb") as f3:
f.write(f3.read())
except:
continue def m3u8_main(m3u8_urls,merge_names):
print("获取m3u8链接,开始执行下载任务")
for url,merge_name in zip(m3u8_urls,merge_names):
name = url.rsplit("/")[-1]
m3u8_files_download(url, name) # 下载m3u8文件
asyncio.run(starter(name,url))
print("校验文件完整性")
verification(name)
merge_ts(name,merge_name) if __name__=="__main__":
cookie = init()
header = {"cookie": f"{cookie}"}
csrfkey = obj.findall(cookie)[0]
print("获取csrfkey")
bizid,video_id= get_video_id(csrfkey)
signatures = get_signature(bizid,csrfkey)
m3u8_urls,merge_name = get_m3u8_url(video_id,signatures)
m3u8_main(m3u8_urls,merge_name)
【python】下载中国大学MOOC的视频的更多相关文章
- 大学MOOC课程视频下载、流文件合并、批量重命名、b站视频下载及学习课程视频推荐
计算机行业技术更新快,编程语言种类多,在当今大数据和人工智能的时代,为了能在相关领域有所成就,就必须掌握好python.R等语言,较好的数学基础和深入的行业背景知识.计算机从业人员务必践行" ...
- 中国大学MOOC课程信息爬取与数据存储
版权声明:本文为博主原创文章,转载 请注明出处: https://blog.csdn.net/sc2079/article/details/82016583 10月18日更:MOOC课程信息D3.js ...
- 中国大学MOOC中的后台文件传输
早期版本的中国大学MOOC一旦被挂起后,应用在完成当前下载任务后无法继续添加新任务,当然也无法将缓存状态写入数据库.这个问题能否顺利解决直接关系到用户体验. 顺便吐槽下,凡是使用了后台文件传输还提示你 ...
- 中国大学MOOC课程信息之数据分析可视化二
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/82318571 - 写在前面 本篇博客继续对中国大学MOOC ...
- 中国大学MOOC课程信息之数据分析可视化一
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/82263391 9月2日更:中国大学MOOC课程信息之数据分 ...
- 中国大学mooc直播回放看这里哦http://www.icourse163.org/forum/1001974001/topic-1003372881.htm?sortType=1&pageIndex=1
中国大学mooc直播回放看这里哦http://www.icourse163.org/forum/1001974001/topic-1003372881.htm?sortType=1&pageI ...
- 中国大学MOOC 邮箱验证的问题
在使用 中国大学 MOOC 过程中,在PC端修改个人资料时,其中有项“常用邮箱”,于是写了QQ邮箱,结果发现一直无法验证,连邮件都无法收到. 经过多番尝试,重新使用邮箱注册的方式注册账号,然后注册成功 ...
- 用 Python 下载抖音无水印视频
说起抖音,大家或多或少应该都接触过,如果大家在上面下载过视频,一定知道我们下载的视频是带有水印的,那么我们有什么方式下载不带水印的视频呢?其实用 Python 就可以做到,下面我们来看一下. 很多人学 ...
- 如何用firefox57看中国大学mooc视频
最新的firefox57看mooc视频不成功,查了很多帖子,不知所云. 其实只要几步: 1.安装User Agent Switcher(看一下其条目,如果没有的话就添加 [Mozilla/5.0 (W ...
随机推荐
- 广度优先搜索 BFS 学习笔记
广度优先搜索 BFS 学习笔记 引入 广搜是图论中的基础算法之一,属于一种盲目搜寻方法. 广搜需要使用队列来实现,分以下几步: 将起点插入队尾: 取队首 \(u\),如果 $u\to v $ 有一条路 ...
- 类变量_main方法_代码块
需要解决的问题: 统计一共创建了多少个对象 类变量(静态变量) 被所有对象共享 可以通过 类名(推荐)|对象名.变量名 方式来访问 main main 方法 是虚拟机在调用 args 传值灵活 结果 ...
- for & while &迭代器
for (int i = 0; i < 10; i++) { System.out.println("hello"); } int a=100; for (;a<110 ...
- python3 获取函数变量
Python 3.8可以使用f字符串调试功能: 1 test_dict = {1: "1", 2: "2", 3: "3"} 2 print ...
- [题解] 春荔(cut) | 贪心
题目大意 有一个长度为 \(n\) 的非负整数序列 \(a_i\),每次可以选择一段区间减去 \(1\),要求选择的区间长度 \(\in[l,r]\),问最少多少次把每个位置减成 \(0\). 不保证 ...
- Nginx中FastCGI参数的优化配置实例
在配置完成Nginx+FastCGI之后,为了保证Nginx下PHP环境的高速稳定运行,需要添加一些FastCGI优化指令.下面给出一个优化实例,将下面代码添加到Nginx主配置文件中的HTTP层级. ...
- Django学习——分页器基本使用、分页器终极用法、forms组件之校验字段、forms组件之渲染标签、forms组件全局钩子,局部钩子
内容 1 分页器基本使用 2 分页器终极用法 3 forms组件之校验字段 1 前端 <!DOCTYPE html> <html lang="en"> &l ...
- 聊一聊 HBase 是如何写入数据的?
hi,大家好,我是大D.今天继续了解下 HBase 是如何写入数据的,然后再讲解一下一个比较经典的面试题. Region Server 寻址 HBase Client 访问 ZooKeeper: 获取 ...
- TinyMCE简介
TinyMCE是一款开源.易用.UI时新的富文本编辑器. 插件丰富,自带插件基本满足要求 可扩展性强,可自定义功能 界面好看,符合现代审美 提供经典.内联.沉浸无干扰三种模式 官网:https://w ...
- 网易数帆 Envoy Gateway 实践之旅:坚守 6 年,峥嵘渐显
服务网格成熟度不断提升,云原生环境下流量处理愈发重要, Envoy Gateway 项目于近日宣布开源,"旨在大幅降低将 Envoy 作为 API 网关的使用门槛",引发了业界关注 ...